 如何将语音识别、计算机视觉和自然语言处理结合起来帮助精神健康患者
如何将语音识别、计算机视觉和自然语言处理结合起来帮助精神健康患者
本文作者Albert Haque,Michelle Guo,Adam S Miner和Li Fei-Fei。文章主要介绍了李飞飞团队的最新研究成果:一种基于机器学习的抑郁症症状严重程度测量方法,该方法使用了视频、音频和文本数据集,以及因果卷积神经网络模型,准确率超过80%。
抑郁症现在是一个全球性问题:已经有3亿多人患有抑郁症,严重时可导致自杀。
由于社会舆论、高昂成本和治疗缺位,60%的精神性疾病患者没有获得任何精神健康服务。就抑郁症来说,有效且高效的诊断服务依赖于临床症状检测,但是,抑郁症症状的自动检测正在打破这一传统,无需临床检测也可以潜在地提高诊断准确性和有效性,从而带来更快速的干预治疗。
在本文中,我们提出了一种机器学习方法来测量抑郁症症状的严重程度。此多模态方法使用了3D面部表情和口语,这些数据在现在的手机上很常见。结果显示,在经过临床验证过的病人健康问卷(PHQ, Patient Health Questionnaire)水平上,它的的平均误差仅有3.67分(相对误差为15.3%);对于检测重度抑郁症,模型则显示出了83.3%的敏感性和82.6%的特异性。
总的来说,本文展示了如何将语音识别、计算机视觉和自然语言处理结合起来帮助精神健康患者,以及相关的从业人员。这项技术还可以应用到手机上,并促进低成本和普惠精神健康服务发展。
1 介绍
一般来说,精神障碍患者会由基础医疗服务医生等人员进行检查,包括基础医疗服务医生。然而,相比身体疾病,精神障碍更难被发现。而且,诸如社会舆论、经济成本和治疗缺位等治疗障碍又加剧了精神健康的负担。为了解决医疗服务中这些根深蒂固的障碍,人们呼吁采取可推广的方法来检测精神健康症状。如果成功了,早期检测可能影响到60%未接受治疗的精神病成年人,并让他们有机会获得治疗。
在临床实践中,医生首先通过面对面临床问诊测量抑郁症症状的严重程度,以此来甄别患者的抑郁症症状。在这些问诊中,临床医生同时评估抑郁症症状的语言和非语言指标:包括音高单调、语速降低、音量降低、手势较少和总向下看,如果这些症状持续了两周,可以认为患者重度抑郁症发作。
在临床人群中,结构化问卷早已用来评估抑郁症状的严重程度。最常见的问卷就是病人健康问卷(PHQ)。这种已被临床验证的工具会在多个个人维度上测量抑郁症症状的严重程度。评估症状的严重性虽然需要很多时间,但这对于初步诊断和进一步改善治疗服务都至关重要。
而基于人工智能的解决方案可以解决这些获得治疗的重重障碍。
图1:多模态数据。对于每个临床问诊,我们使用:(a)3D面部扫描的视频,(b)音频录音,可转化为可视化的log-mel声谱图,以及(c)患者讲话的转录文本。我们的模型使用了这三种模式预测抑郁症症状的严重程度。
我们设想了一种基于人工智能的解决方案:其中的抑郁个体们可以接受循证精神健康服务,同时又避免了现有的治疗获取障碍。这种解决方案可以利用多模态传感器或者文本消息(就是现代智能手机上常见的那些)来增多及时和效率高的症状筛查。对话式AI是另一种潜在的解决方案。我们的希望是自动化反馈将(i)为可能抑郁的个体提供可操作的反馈,并(ii)通过包括视觉、音频和语言信号来改进临床医生的抑郁自动化筛查工具。
贡献:我们提出了一种机器学习方法通过去识别化的多模态数据来测量抑郁症症状的严重程度。我们模型的输入是面部关键点的音频、3D视频以及患者在临床问诊中的说话转录文本。我们的模型的输出要么是PHQ评分,要么是表明重度抑郁症的分类标签。我们的方法利用了因果卷积网络(C-CNN),将句子们“概括”为单个嵌入,然后使用这个嵌入来预测抑郁症症状的严重程度。在我们的实验中,我们展示了我们基于句子的模型是如何与单词级嵌入以及前人的工作发生相互关系的。
2 数据集
我们使用了DAIC-WOZ数据集,其中包含了抑郁症和非抑郁症患者的音频和3D面部扫描。对于每一个患者,我们都提供了PHQ-8评分。这个语料库是用半结构化临床问诊数据创建的。在半结构化临床问诊中,病人与遥控数字助理对话,临床医生会通过数字助理询问一系列专门针对抑郁症症状的问题。数字助理用查询的方式提问每一个病人(例如,“你多久去一次你的家乡?”),并得到对话反馈(例如“酷”)。我们一共收集了来自142名患者的189次临床问诊的共50小时的数据。我们论文的结果来自验证集。更多的细节可以在附录中找到。这项工作中使用的数据不包含受保护的健康信息(PHI)。数据集管理员从音频录音和转录中删除了对个人姓名、具体日期和地点的信息。3D面部扫描是低分辨率的(68像素),并不包含足够的信息来识别出个人,只包含足够的信息来测量面部运动,比如眼睛、嘴唇和头部运动。虽然数据集是公开可用的,但是在未来,将此方法应用于其他数据集的研究人员可能会遇到PHI,那时他们应该合理的设计实验。
3 模型
我们的模型由两个技术部分组成:(i)一个句子级的“概要”嵌入(嵌入的目的是“概括”一个可变长度的序列,将它变为固定大小的数字向量。)和(ii)一个因果卷积网络(C-CNN)。概览如图2所示。
句子级嵌入:几十年来,单词和音素级嵌入一直是编码文本和语音的必备因素。虽然这些嵌入在某些任务中表现不错,但它们的句子级建模能力有限。这是因为单词和音素级嵌入智能捕获一个狭窄的时间范围,通常最多有几百毫秒。在这项工作中,我们提出了一种新的多模态句子级嵌入,这使得我们能够捕获更长期的声音、视觉和语言元素。
图2:我们的方法:学习一个多模态句子级嵌入。总的来说,我们的模型是因果卷积神经网络。输入到我们的模型是:音频,3D面部扫描和文本。多模态句子级嵌入被装到了抑郁症分类器和PHQ回归模型里(上面没有显示)。
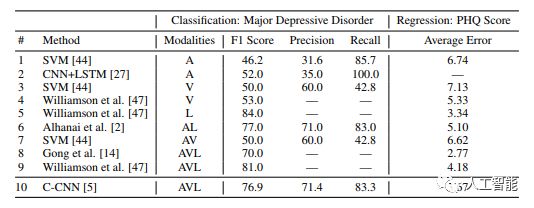
表1:检测抑郁症的机器学习方法的比较。评估了两项任务:(i)重度抑郁症的二元分类和(ii)PHQ评分回归。模态:A:音频,V:视觉,L:语言(文本),AVL:三者组合。对于前人的工作,数字来源于原始出版物中的报告。破折号表示未被报告度量。
因果卷积网络:在临床问诊中,患者可能会结巴,并且经常在说话时停顿。这导致了抑郁症患者视听录像比非抑郁症患者时间更长。近来,因果卷积网络(C-CNN)在长序列上的表现优于递归神经网络(RNNs)。有作者甚至表明,RNNs可以由完全前反馈网络(即CNNs)来近似。结合扩张性卷积,C-CNN已经可以为抑郁症筛查问诊建立长序列模型。为了更全面地比较C-CNN和RNN,我们建议请读者查阅Bai et al。
4 实验
我们的实验分为两部分。首先,将我们的方法与现有测量抑郁症症状严重程度的工作进行了比较(表1)。我们预测PHQ评分,并输出关于患者是否患有重度抑郁症的二元分类,通常PHQ评分大于或等于10。其次,我们对我们的模型进行消融研究,以更好地理解多模态和句子级嵌入的效果(表2)。数据格式、神经网络结构和关键超参数可以在附录中找到。
4.1 抑郁症症状严重程度的自动测量
在表1中,我们将我们的方法与前人在测量抑郁症症状严重程度方面的工作进行了比较。我们的方法与前人工作的一个区别在于我们的方法不依赖于问诊情景。前人的工作在很大程度上取决于问诊情境,比如所问问题的类型,而我们的方法接受没有这种元数据的句子。虽然额外的上下文通常对模型有帮助,但是它可能引入技术性挑战,比如每个上下文分类的训练样本太少。我们方法的另一个区别是使用原始输入模态:音频、视觉和文本。前人的工作使用的是工程化的特征,比如最小/最大音调和词频。
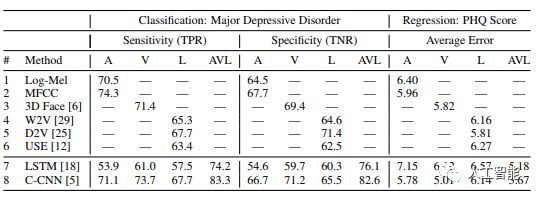
表2:消融研究。1-2行是手工制作的嵌入,3-6行是前期训练的嵌入,7-8行表示我们学习的句子级嵌入。模态:A:音频,V:视觉,L:语言(文本),AVL:三者组合。TPR和TNR分别表示真阳性率和真阴性率。输入到7-8行的是log-mel声谱图、3D面部和Word2Vecs的序列。
4.2 消融研究
在表2中,1-6行表示手工制作的或前期训练的句子级嵌入。也就是说,整个输入语句(音频、3D面部扫描和转录)被概括为一个向量。然而,我们建议通过输入学习一个句子级嵌入。这些显示在7和8行里。要注意,我们的方法确实使用了手工制作和前期训练的单词级嵌入作为输入。然而,在内部,我们的模型学习句子级嵌入。在前期的句子级嵌入工作之后,再简单计算1-6行的平均值。为了学习句子级嵌入,我们评估了:(i)长短期记忆和(i i)因果卷积网络。
5 讨论
在我们的工作适用于未来的研究之前,有一些问题需要考虑。
首先,虽然一个人控制着数字助理,但是数据是从人与计算机的访谈中收集的,而不是人与人之间。研究显示,与真人相比,患者与助理交谈时对公开秘密的恐惧更小,并且表现出更高的情感强度。人们通过向聊天机器人表露情感还可以体验到心理上的安慰。
第二,虽然它通常用于治疗方案设置和临床试验,但症状严重程度评分(PHQ)与抑郁症的正式诊断不同。我们的工作旨在加强现有的临床方法,而不是发布一个正式的诊断。
最后,虽然预先存在的嵌入方便使用,但是最近的研究表明这些向量可能包含由于基础训练数据引起的误差。减小误差超出了我们的工作范围,但对于提供敏感的诊断和治疗至关重要。
未来的工作可以更好地利用纵向和时间信息,例如相隔数周或数月的问诊中的抑郁症评分。搞清楚为什么模型会做出某些预测也是很有价值的。诸如3D人脸上的置信度图谱和音频片段的“有用性”评分等可视化技术也可能会带来新的见解。
总的来说,我们提出了一种结合语音识别、计算机视觉和自然语言处理技术的多模态机器学习方法。我们希望这项工作将激励其他人建立基于人工智能并用来了解抑郁症以外的心理健康障碍的工具。
致谢
这项研究得到了美国国立卫生研究院、国家高级转化科学中心、临床和转化科学促进中心的支持。本文内容仅由作者负责,并不一定代表NIH的官方观点。
A 附录
A.1 数据格式
完整的数据细节可以在原始数据集网站找到。音频是用16kHz的头戴式麦克风记录。视频被微软Kinect以每秒30帧的速度记录。使用OpenFace提取了总共68个三维面部关键点。音频被数据集管理员转录并被分成具有毫秒级时间戳的句子和短语。我们使用数据集的train-val分割:训练(107名患者),验证(35名患者)。注意,当一个测试集存在时,标签不是公开的。我们规范了转录中的俚语。比如,bout被翻译成about,till被翻译成until,lookin被翻译成looking。所有文本都被小写,数字也规范化(例如,24代表二十四)。
A.2 实现细节
A.2.1 实验1:自动测量抑郁症症状的严重程度
输入“我们的方法”,比如如下的因果卷积神经网络:
• 音频:带有80个mel过滤器的log-mel声谱图。
• 视觉:68个三维面部特征点。
• 语言:Word2VEC嵌入。
网络结构是一个10层的因果卷积网络,内核大小为5,每层有128个隐藏节点。对于所有非线性层,归零概率为0.5。损失目标是用于分类的二元交叉熵,以及用于回归的平均方差。模型采用Adam优化器进行优化,β1=0.9,β2=0.999,L2的权重衰减是1e-4。最初的学习率为1e-3和1e-5,分别用来分类和回归。使用的批量大小为16。该模型在一块NVIDIA V100 GPU上训练,它的最大训练次数为100。我们的模型用Pytorch实现。
A.2.2 实验2:消融研究
对于表2,每一行的详细信息如下:
1.用80个mel过滤器计算log-mel声谱图。
2.用13个结果值计算mel-frequency倒谱系数。
3.数据集总共提供了68个三维面部关键点,它们是用OpenFace提取的。
4.Word2VEC向量使用谷歌公开的Word2VEC模型和Gensim Python库计算,每个向量的长度为300。
5.Doc2Vec向量也使用Gensim计算,每个向量的长度为300。
6.通用句子级嵌入使用公开发行版的Tensorflow计算,每个向量的长度为512。
7.LSTM由10层和128个隐藏单元组成,并且还用附录A.2.1中所述的相同批量大小,优化器等进行优化。
8.我们的因果卷积神经网络模型与附录A.2.1中所概述的模型相同。公共代码用于实现LSTM和因果CNN的核心网络结构的构建。
-
语音识别
+关注
关注
38文章
1721浏览量
112541 -
计算机视觉
+关注
关注
8文章
1696浏览量
45927 -
自然语言处理
+关注
关注
1文章
612浏览量
13504
原文标题:李飞飞团队最新成果:通过口语和3D面部表情评估抑郁症严重程度
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理包括哪些内容 自然语言处理技术包括哪些
四轴姿态怎么和电机结合起来
如何把库函数写的文件和寄存器写的文件结合起来用?
【推荐体验】腾讯云自然语言处理
将微机原理与单片机结合起来
什么是人工智能、机器学习、深度学习和自然语言处理?
什么是自然语言处理_自然语言处理常用方法举例说明

AI:计算机视觉与自然语言处理融合的研究进展





 工商网监
工商网监
评论