 你认为Grid R-CNN会成为Faster R-CNN那样的传世经典吗?
你认为Grid R-CNN会成为Faster R-CNN那样的传世经典吗?
Grid R-CNN是商汤科技最新发表于arXiv的一篇目标检测的论文,对Faster R-CNN架构的目标坐标回归部分进行了替换,取得了更加精确的定位精度,是最近非常值得一读的论文。
今天就跟大家一起来细品此文妙处。
一、作者信息
该文所有作者均来自商汤科技:
该文直取Grid(网格)修饰R-CNN,意即将目标检测中位置定位转化为目标区域网格点的定位。
二、算法思想
如下图所示:
在目前的R-CNN目标检测算法中,目标的2个点(比如左上和右下)就能表征其位置,将目标的定位看为回归问题,即将ROI特征flatten成向量,后接几个全连接层回归目标的坐标偏移量和宽高。
作者认为,这种处理方式没能很好的利用特征的空间信息。
作者希望利用全卷积网络的精确定位能力计算目标位置,将2个目标点的回归问题,转化为目标区域网格点(Grid Points)的定位问题。目标区域的网格点位置是全卷积网络的监督信息,因为是直接将目标区域等分,是可以直接计算的。网络推断时,计算heatmap的极值,即为求得的网格点(Grid Points)。
上图展示了使用3*3网格点的情况。
三、算法流程
作者改造的是Faster R-CNN的目标定位部分,其算法流程如下:
前半部分与Faster R-CNN相同,在得到目标候选区域和ROI特征后,分类部分进行目标分类,而定位部分接全卷积网络,其监督信息来自根据目标位置计算得到的网格监督信息。
流程图中作者特别标出了特征融合模块(feature fusion module),其意在使用网格中相邻网格点的位置相关性,融合特征使得定位更加精确。
以下针对其中关键步骤进行详细说明。
3.1 网格引导定位
将目标区域划为网格,目标的定位即转化为网格点的定位。
训练时,ROI特征(14*14大小)通过8个3*3空洞卷积,再通过两个反卷积把尺寸扩大(56*56),再通过一个卷积生成与网格点相关的 heatmaps(9 个点就是 9 张图,后文实验也使用了4个点的情况)。监督信息是每一个点所处位置的交叉十字形状的5个点的位置。最后再接sigmoid函数,在heapmaps上得到概率图。
推断时,将heapmaps极值的位置映射回原图,即得到了网格点的位置。

读到这里,读者可能会有一个疑问,即计算得到的网格点组成的形状是方方正正的,而Heapmaps极值得到的网格点未必组合在一起是方方正正的,不好确定目标区域。
作者的方法是对原本应该具有相同x或者y坐标的网格点的坐标进行平均。

到此,即得到了目标位置。
3.2 网格点特征融合
很显然,网格点之间具有内在的联系,相邻网格点之间可以相互校正位置提高定位精度。
为此,作者设计了网格点特征融合的机制。
首先,在计算网格点heapmaps时,每个网格点使用不同的滤波器组,防止它们之间共用特征以至相互影响。
然后在每个网格点的Heapmap出来后,将相邻网格点的Heapmaps经过卷积滤波与其相加,形成新的heapmap。
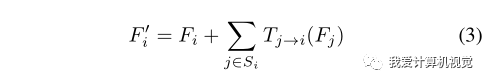
作者将距离特定网格点最近的相邻网格点(1个单位网格长度)组成的网格点集合的特征融合称为一阶特征融合,次近的相邻网格点(2个单位网格长度)组成的网格点集合的特征融合称为二阶特征融合。下图中(a)(b)分别展示了此融合过程。
3.3 扩展区域映射
这一步主要是为了应对在实际使用中,RPN 给出的 proposal并不总是将完整物体包含在内。如下图:
图中白色的实线框表示 RPN 给出的候选框,它没有完全包含所有的网格点。
而作者指出,简单的扩大候选框的大小,不会带来提升,甚至降低对小物体检测的精度(后面有实验验证)。
作者认为heatmap的感受野其实是很大的,并不限于候选框内,所以就干脆直接将heatmap对应的区域看成候选框覆盖的区域两倍大(如图中虚线围起来的区域)。
这么做的好处是,只需简单修改网格引导定位中的位置映射公式。即
四、实验结果
作者首先研究了算法中网格点数对精度的影响。如下图:

相比回归的方法,Grid R-CNN精度更高,而且随着点数增加精度也在提高。
比较AP0.5和AP0.75发现,精度提升主要来自高IoU阈值的情况。
其次,作者实验了网格点特征融合策略对性能的影响。如下图:

可见该文提出的特征融合策略是有效的,而且二阶特征融合更加有效。
然后,作者实验了扩展区域映射对精度的影响。如下图:
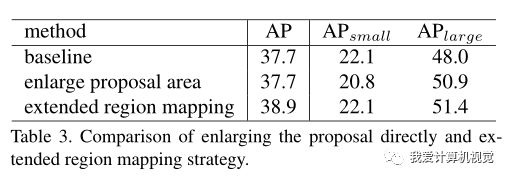
可见,直接扩大候选框区域的方法伤害了精度,而本文提出的扩展区域映射(extended region mapping)的方法则使精度有较大的提高(1.2个AP)。
作者又在主流的目标检测数据库上与state-of-the-art进行了比较。
下图展示了在Pascal VOC数据集上,相比R-FCN、FPN,使用相同骨干网的情况下,精度取得了极大的提升!

在COCO minival数据集上的实验,同样取得了较大幅度精度提升。

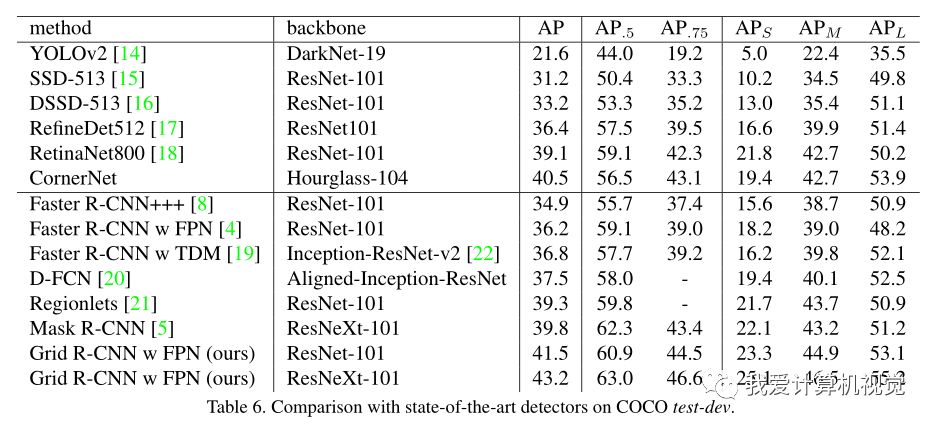
在COCO test-dev数据集上也实现了一骑绝尘!如下图:
与Faster R-CNN相比,发现精度提升主要来自高IoU阈值的部分,如下图所示。
所以作者猜测,Grid定位分支也许轻微影响了分类的分支。
下图是一些目标的定位示例(请点击大图查看):
作者最后列出了Grid R-CNN对各目标类别的精度增益,发现那些矩形和长方形目标(例如键盘,笔记本电脑,叉子,火车和冰箱)往往获得更大的精度增益,而具有圆形性质的物体(例如运动球,飞盘,碗,钟和杯子)则性能下降或获得较小的增益。
五、总结
该文反思了目标检测中的定位问题,提出以覆盖目标的网格点作为监督信息使用全卷积网络定位网格点的方法,大幅提高了目标定位精度。值得研究目标检测的朋友学习~
文中没有提及推断速度、代码是否会开源,希望有进一步的消息出来。
目标定位的方法还有什么可挖掘的吗?
你认为Grid R-CNN会成为Faster R-CNN那样的传世经典吗?
-
滤波器
+关注
关注
161文章
7816浏览量
178103 -
数据库
+关注
关注
7文章
3799浏览量
64385 -
网格
+关注
关注
0文章
139浏览量
16018
原文标题:Grid R-CNN解读:商汤最新目标检测算法,定位精度超越Faster R-CNN
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于深度学习的目标检测算法解析
深度卷积神经网络在目标检测中的进展
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别
手把手教你操作Faster R-CNN和Mask R-CNN
一种新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位

基于改进Faster R-CNN的目标检测方法
基于Mask R-CNN的遥感图像处理技术综述
用于实例分割的Mask R-CNN框架
深入了解目标检测深度学习算法的技术细节
PyTorch教程14.8之基于区域的CNN(R-CNN)

PyTorch教程-14.8。基于区域的 CNN (R-CNN)






 工商网监
工商网监
评论