 2018年,机器学习和人工智能领域最重要的突破是什么?
2018年,机器学习和人工智能领域最重要的突破是什么?

2018年,人工智能发展到什么阶段了?Quora鼎鼎有名的大V认为,AI炒作和AI威胁论在今年都降温,并且不会有AI寒冬,升温的是各种开源框架,2019年的AI,你认为会是怎样?
2018年,机器学习和人工智能领域最重要的突破是什么?
(这里给你留出充分思考的时间。)
看看其他的观点。
之前,KDnuggets邀请了11位来自工业、学术和技术一线人员,回顾2018年AI的进展。其中,呼吁阻止AI学术顶会向商业化沦陷的CMU助理教授Zachary C. Lipton认为,2018年 (深度学习) 最大的进展就是没有进展。
最近,Forbes则采访了120位AI行业的创始人和高管,在2018年AI技术和产业现状的基础上,对2019年进行展望,提出了120个预测。(里面有让你觉得英雄所见略同的看法吗?)
与往年一样,Quora鼎鼎有名的大V、机器学习研究者、前Quora工程负责人Xavier Amatriain,也写下了他认为2018年机器学习和人工智能领域最大的进展:
AI炒作和AI威胁论都有所降温;
越来越多的人开始关注公平性、可解释性或因果关系等问题;
深度学习不会再遇到寒冬,并且在图像分类以外(尤其是自然语言处理)领域投入实用并产生效益;
AI框架方面的竞争正在升温,要是你想做出点事情,最好发表几个你自己的框架。
一起来看看。
深度学习寒冬不会到来,2018对AI的期望和恐惧都下降了
正如Xavier Amatriain说的那样,深度学习的寒冬不会到来——这项技术已经用到产业里并带来了收益,现实让人们收起了一部分对AI的期望和恐惧,业界开始思考数据的公平性、模型的可解释性等更本质的问题。
如果说2017年是人工智能炒作和威胁论的风口浪尖,那么2018似乎是我们开始冷静下来的一年。
虽然马斯克等人确实还在继续强调他们对人工智能的恐惧,但他们可能忙于处理其他事务而无暇顾及这个议题。
与此同时,媒体和公众看来也都意识到,虽然自动驾驶汽车和类似的技术在推进,但不会很快到来。不过,仍然有声音支持对AI本身进行管制,Xavier Amatriain认为这种观点是错误的,真正该管制的是AI所造成的结果。
深度学习:可解释性得到更多关注,NLP迎来ImageNet时刻
关于AI炒作和AI威胁论的降温实际上前面已经说过了,Xavier Amatriain表示他很高兴看到今年的重点似乎已经转移到去解决更具体的问题上面。
例如,业内围绕公平性 (fairness)展开了大量的讨论,不仅举办了多个相关主题的会议 (比如FATML、ACM FAT),甚至还出现了一些在线课程。
ACM FAT会议,2019年1月底在美国召开
关于可解释性 (interpretability)、对算法或模型的理解 (explanation)和因果关系 (causality)。后者重新成为人们关注的焦点,主要是因为Judea Pearl出版了“The Book of Why”这本书。关于推荐系统的ACM Recsys会议,最佳论文奖也颁给了一篇讨论如何在嵌入中包含因果关系的论文 (Causal Embeddings for Recommendations)。
话虽如此,许多其他作者认为,因果关系在某种程度上是对深度学习理论的干扰,我们应该再次关注更具体的问题,比如 interpretability 或 explanation。说到 Explanation,这个领域的亮点之一可能是华盛顿大学 Marco Tulio Ribeiro等人发表的 Anchor论文和代码,这他们对自己提出的著名模型LIME的改进。
虽然关于深度学习是最通用的AI范例这一点,仍然存在许多疑问(提问者算我一个);虽然Yann LeCun和Gary Marcus两人已经是第n次争论这个问题,但很明显,深度学习不仅仅停留于此。
在这一年里,深度学习方法在视觉以外的领域,包括语言、医疗、教育等领域取得了前所未有的成功。尤其是教育方面,国内国外的自适应学习(Adaptive Learning) 都愈发火热,以中国的松鼠AI (乂学教育) 为代表的个性化自适应教学平台,甚至请到了“机器学习教父”Tom Mitchell出任首席科学家。
事实上,在NLP领域,我们看到了今年最引人注目的进展。如果让我必须选择今年最令人印象深刻的AI应用程序,那么我的选择都来自NLP领域(而且都来自谷歌)。第一个是谷歌的超级有用的Smart Compose智能撰写邮件工具,第二个是Duplex对话系统。
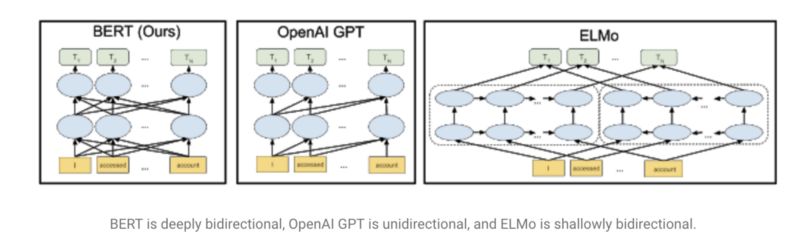
使用语言模型的想法加速了NLP的进步,这个想法在今年由Fast.ai的UMLFit推广起来。接着,我们看到了其他(改进的)方法,如艾伦研究所的ELMO,Open AI的transformers,以及最近谷歌发布的BERT,它在许多任务上击败了此前的SOTA结果。这些模型被描述为“NLP的ImageNet时刻”,因为它们提供了随时可用的预训练通用模型,也可以对特定任务进行微调。
除了语言模型之外,还有许多其他有趣的改进,比如facebook的多语言嵌入。值得注意的是,我们还看到这些方法和其他方法是如何迅速地集成到更一般的NLP框架中,比如AllenNLP或Zalando的FLAIR。
生态:AI框架战升温,要出成绩你最好发表几个自己的框架
说到框架,今年的“AI框架战争”可谓愈演愈烈。令人惊讶的是,随着Pytorch 1.0的发布,Pytorch似乎正在赶上TensorFlow。
虽然在生产中使用Pytorch的情况仍然不够理想,但是Pytorch在这方面的进展似乎比TensorFlow在可用性、文档和教育方面的进展要快。有趣的是,选择Pytorch作为实现Fast.ai library的框架很可能起了重要作用。
话虽如此,谷歌已经意识到了这一切,并正在朝着正确的方向推进,例如将Keras纳入框架。最后,我们都能从所有这些伟大的资源中获益,所以请继续迎接它们的到来吧!
pytorch 与 tensorflow 的搜索趋势
在框架空间中,另一个进展很快的是强化学习。
虽然我认为RL的研究进展并不像前几年那样令人印象深刻 (浮现在我脑海中的只有DeepMind最近的Impala工作),但令人惊讶的是,在一年时间里,我们看到所有主要AI玩家都发布了RL框架。
谷歌发布了用于研究的Dopamine框架,Deepmind发布了某种程度上与Dopamine竞争的TRFL框架。Facebook不甘落后,发布了Horizon,而微软发布了TextWorld,后者更专门用于训练基于文本的智能体。希望2019年所有这些开源的优势能够帮助RL领域取得更多进步。
最后,我很高兴看到谷歌最近在TensorFlow之上发布了TFRank。 Ranking是一个非常重要的ML应用。
数据:用合成数据训练DL模型
深度学习似乎最终消除了对数据的智能需求,但事实远非如此。
围绕着改进数据的想法,该领域仍有一些非常有趣的进展。例如,虽然数据增强已经存在了一段时间,并且对于许多DL应用程序来说是关键,但谷歌今年发布了AutoAugment,这是一种深度强化学习方法,可以自动增强训练数据。
一个更极端的想法是用合成数据训练DL模型。这已经在实践中尝试了一段时间,被许多人视为AI未来的关键。NVidia在Training Deep Networks with Synthetic Data这篇论文中提出了有趣的新颖想法。在“Learning from the experts”这篇论文中,我们还展示了如何使用专家系统来生成合成数据,然后将合成数据与实际数据相结合,使用这些数据来训练DL系统。
最后,还有一个有趣的想法,即使用“弱监督”来减少对大量手工标记数据的需求。Snorkel是一个非常有趣的项目,旨在通过提供一个通用框架来促进这种方法。
基础理论:AI没有太多基础性突破?
我并没有看到太多AI更基础性的突破。我并不完全同意Hinton的观点,他说这种创新的缺乏是由于该领域“资深人士太少,年轻人太多”,尽管在科学上确实存在这样的趋势,即突破性研究经常是在更老的年纪完成的。
在我看来,目前缺乏突破的主要原因是,现有方法和变体仍然有许多有效的实际应用,所以很难冒险采用那些可能不太实际的方法。当该领域的大部分研究由大公司赞助时,这一点就更加重要了。
这方面,今年有一篇有趣的论文挑战了某些假设,题为“对用于序列建模的一般卷积和递归网络的经验评估”(An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling)。在高度经验主义和使用已知方法的同时,这篇论文打开了发现新方法的大门,因为它证明了通常被认为是最优的方法实际上并不是最优。
需要明确的是,我不同意Bored Yann LeCun的观点,他认为卷积网络是最终的“终极算法”(master algorithm),而且我认为RNN也不是。
即使是序列建模,也有很大的研究空间!另一篇具有高度探索性的论文是最近的NeurIPS最佳论文“Neural Ordinary Differential Equations”,它挑战了DL中的一些基本内容,包括layers本身的概念。
2018年,机器学习和人工智能的发展卡在了数据集上面
在 Xavier Amatriain 的观点之后,新智元也补充一点:
2018年,机器学习和人工智能的进展卡在了数据集上面。
为什么这么说?
昨天,创业公司Graphext在Reddit上发帖,公布了他们对2018年Reddit网站Machine Learning内容分类里2509条帖子聚类分析的结果 (点击“阅读原文”查看大图):
(Reddit上) 人们最关心的话题 (占比20%) 是数据集,包括训练数据,大规模数据集,开源,新的数据、模型、样本等等;其次是研究论文 (占比18%),包括复现结果、Kaggle竞赛和谷歌、FB的工作;再次是训练 (占比16%)。
Graphext对2018年Reddit机器学习帖子聚类结果:最受关注的是数据
虽是一家之言,但这个聚类结果也在一定程度上反映了当前机器学习和人工智能从业者的关注点——数据!大数据!开源大数据!
也难怪作为学者的Zachary Lipton要说,2018年深度学习最大的进展就是没有进展——我们仍旧在依靠大数据,手握大数据和大算力的谷歌、FB等巨头最容易出成果,而迫切复现其算法和模型的其他机器学习工程师则关注训练的问题。
-
人工智能
+关注
关注
1821文章
50366浏览量
267026 -
机器学习
+关注
关注
67文章
8567浏览量
137243 -
深度学习
+关注
关注
73文章
5610浏览量
124651
原文标题:2018机器学习和AI最大突破没找到,但我发现了最大障碍!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录



评论