 人类的视觉识别学习过程是怎样的?我们能否研究这些不同的来源?
人类的视觉识别学习过程是怎样的?我们能否研究这些不同的来源?
当只需要把大规模标注图像数据库塞给深度神经网络就可以得到高准确率的物体分类模型之后,有很多研究人员开始考虑更深入的问题:人类的视觉识别学习过程是怎样的?以及既然人类视觉系统与计算机视觉系统之间表现出了种种不同,我们能否研究这些不同的来源?这是否能给我们带来新的启示?
与深度学***不同的是,人类幼儿正是靠少量物体、少量面容的反复多视角观察培养出了稳定、通用的物体识别能力。
视觉学习同时依赖于算法和训练材料。这篇文章考虑了婴幼儿以自我为中心视觉的自然统计特性。这些用于人类视觉目标识别的自然训练集与输入机器视觉系统的训练数据有很大的不同。比起通过平均经历所有事情来进行学习,幼儿经历的分布偏向明显:有很多事情重复发生。虽然从整体上看变化很大,但个体对事物的看法是按照特定的顺序来体验的——从每时每刻变化的缓慢、流畅的视觉,到场景内容发展有序的过渡。我们认为,婴幼儿偏向明显、有序、有偏向的视觉体验是一种训练数据,它使人类学习者能够开发出一种方法来识别所有事物,包括随处可见的实体和很少见到的实体。人类和机器学习研究人员将真实世界统计的学习数据联合起来考虑,似乎有可能为这两个学科带来进步。
引言
学习是人类认知的核心属性,是人工智能长期追求的目标。我们正处于在人类和人工智能领域产生出新见解的临界点,这些见解将通过明确地将人类认知、人类神经科学和机器学习的进步联系起来而更快地显现出来。「Thought-papers」呼吁机器学习的研究人员利用来自人类和神经的灵感来建造像人一样学习的机器(例如Kriegeskorte, 2015;Marblestone et al., 2016),并呼吁人类认知和神经科学的研究人员把机器学习算法作为关于认知、视觉和神经机制的假设(Yamins and DiCarlo, 2016)。这种新萌发出的兴趣的推动力之一使深度学习网络在解决非常困难的学习问题方面取得了巨大的成功。这些问题是以前无法解决的(例如Silver et al., 2016)。在神经感知器和连接主义网络的谱系中,深度学习网络将原始的感官信息作为输入,并使用多层的分层组织结构,每一层的输出作为下一层的输入,从而形成特征提取和转换的级联。这些网络特别成功的一个应用是机器视觉。这些卷积深度学习网络(CNNs)的分层结构和空间汇聚不仅产生了最先进的图像识别技术,而且通过特征提取的分层组织来实现这一功能,这种特征提取近似于人类视觉系统皮层的功能(Cadieu et al., 2014)。
在人类认知方面,头戴式摄像机和头戴式眼球追踪技术的最新进展,已经在自然学习环境方面取得了令人兴奋的发现。人类日常视觉环境的结构和规律——尤其是婴儿和儿童的视觉环境——一点也不像最先进的机器视觉中使用的训练集。机器学习的训练图像是由成人拍摄并组织起来的照片。因此,他们偏向于成熟系统的「看起来有用」的东西,反映的是感知发展的结果,而不一定是驱动这种发展的场景(例如,Fathi et al., 2011;Foulsham et al., 2011;Smith et al., 2015)。真实世界的感知体验并不是由摄像机来框定的,而是与身体在世界上的活动联系在一起的。因此,学习者对视觉环境的视角是高度选择性的,取决于瞬间的位置、空间中的方位、姿势以及头部和眼睛的运动(参见Smith et al., 2015., 2015, 待审)。图1显示了以自我为中心的视域的选择性:并不是环境中的所有内容都在婴儿的视域范围中;除非婴儿转过头去看,否则看不到猫、窗户、时钟、站着的人的脸。感知者的姿势、位置、运动、兴趣和社会互动使视觉信息的观点产生系统性偏向。
图1 自我中心视域的选择性。阴影指示的视场对应婴儿头部视角。
随着个人成长,对不同类别的视觉体验会产生偏向。从而使所有这些——姿势、位置、动作、兴趣——都发生了巨大的变化。特别是在生命的前两年,每一项新的感官运动的成就——翻身、伸展、爬行、行走(以及更多)——都会为新的视觉体验类别打开大门。因此,人类视觉系统的发展不是通过成批的处理,而是通过一套系统、有序的视觉体验课程来完成的,这套课程是通过婴儿自身的感觉运动发展而设计的。以自我为中心的视觉系统为研究人员提供了直接访问这些发展受到制约的视觉环境属性的途径。在这里,我们考虑了真实世界视觉学习数据集的新发现与机器学习的潜在相关性。
有人可能会问,鉴于当代计算机视觉的所取得的成功,机器学习者为什么要关心孩子们是如何做到这一点的呢?Schank 是人工智能早期的一位开创性人物,他写道:「我们希望能够开发出一个可以学习的程序,就像一个孩子所做的那样……」(Schank, 1972)。这似乎仍然是自主人工智能的一个合适目标。最近,在一个大型的机器学习会议上,Malik(2016年,私人交流,参见Agrawal et al., 2016)告诉想为机器学习下一个大的进步做准备的年轻学习者「认真学习发展心理学,然后运用这些知识构建新的更好的算法。」有鉴于此,我们从一个例子开始,说明为什么机器学习者应该关注儿童学习环境中的规律:有充分的证据表明,一个两岁儿童在视觉学习方面的能力是当代计算机视觉中尚无法匹敌的(见Ritter et al., 2017)。
两岁小孩能做什么
人类可以在不同条件下下识别多种类别的大量物体实例(Kourtzi and DiCarlo, 2006;Gauthier and Tarr, 201)。识别所有这些实例和类别需要视觉训练;人们必须曾经见过狗、汽车和烤面包机才能在视觉上识别这些类别的实例(例如,Gauthier et al., 2000;Malt and Majid, 2013;Kovack-Lesh et al., 2014)。这对人类和计算机视觉算法都适用。但目前儿童的发展轨迹和算法有很大的不同。对于儿童来说,早期学习是缓慢且充满错误的(例如,MacNamara, 1982;Mervis et al., 1992)。的确,1-2 岁的儿童在视觉目标识别任务中的表现可能比表现最好的计算机视觉算法要差一些,因为 1-2 岁儿童在进行类别判断时具有许多抽象过度和抽象不足的特点,有时在视觉拥挤的场景中完全不能识别已知的物体(Farzin et al., 2010)。然而,两岁之后情况就不一样了。此时,孩子们可以从一个实例推断出整个类别。只要给定一个新类别的实例及其名称,两岁的儿童就会立即以成人的方式概括该名称。例如,如果一个两岁的孩子遇到第一个拖拉机——比如说,一个绿色的 John Deere 拖拉机在地里工作——而当听到它的名字,孩子从这一点会认识所有的各种各样的拖拉机——红色的 Massey-Fergusons,古董拖拉机,割草机——但不是挖掘机或卡车。这种现象在发展文献中被称为「形状偏向」,是在儿童的自然类别学习中观察到的「单样本」学习的一个例子。这已经在实验室中得到了复制和广泛研究(例如,Rosch et al., 1976;Landau et al., 1988;Samuelson and Smith, 2005)。
研究人员如今已经非常了解「形状偏向」及其发展,下面列举一些相关研究成果。形状偏向的出现与儿童物体名称词汇量的快速增长是同时发生的。这种偏向是关于感知到的事物的形状,当儿童能够从主要部分的关系结构中识别出已知的物体时,这种偏向就会出现(Gershkoff-Stowe and Smith, 2004)。形状偏向本身是通过对一组初始对象名称的缓慢学习而习得的(据估计,其中可以包括 50 到 150 个学习到的类别,Gershkoff-Stowe and Smith, 2004)。在实体游戏的背景下,对基于形状的对象类别辨别进行早期强化训练,会导致 1-2 岁的儿童比一般儿童更早出现形状偏向,而且这些儿童词汇量的增长速度也会更早 (Samuelson, 2002;Smith et al., 2002;Yoshida and Smith, 2005;Perry et al., 2010)。形状偏向不仅与儿童对物体名称的学习有关,还与对的物体操作有关 (Smith, 2005;James et al., 2014a),并随着儿童从三维形状的抽象表征中识别物体的能力逐渐增强(Smith, 2003,2013;Yee et al., 2012)。学习语言有困难的儿童——晚说话者、有特殊语言障碍的儿童、自闭症儿童——不会形成强烈的形状偏向(Jones, 2003;Jones and Smith, 2005;Tek et al., 2008;Collisson et al., 2015;Potrzeba et al., 2015)。简而言之,典型的成长中的儿童在缓慢地学习一组对象类别名称的过程中,也会学习到如何以某种方式直观地表示对象形状。这种方式使他们能够在只提供一个新类别实例的情况下,估计出一个新对象类别的边界。最先进的机器视觉运作方式则不同。没有哪种机器学习的方法能够改变其学习的本质;相反,每一个需要学习的类别都需要大量的训练和例子。
区别在哪里?所有的学习都依赖于学习机制和训练数据。幼儿是非常成功的视觉分类学习者;因此,他们的内部算法必须能够利用日常经验中的规律,不管这些规律是什么。因此,了解婴儿的日常视觉环境——以及他们如何随着发展而变化——不仅有助于揭示相关的训练数据,而且还提供了有关学习的内部机制的信息。
发展变化的视觉环境
对婴儿头部摄像机获得的数据进行研究,非常清楚地表明:人类视觉学习的训练集在成长过程中发生了很大的变化。图 2 显示了头摄像头捕获的示例图像。一个例子涉及到婴儿对周围人的以自我为中心的视角。对婴儿在日常生活中采集的大量头部相机图像进行分析(Jayaraman et al., 2015,2017;Fausey et al., 2016)研究表明,人物总是出现在婴儿头部相机图像中,新生儿和两岁儿童的这一比例是相同的。这并不奇怪,因为不能把婴幼儿单独留下。然而,在头部摄相机的图像中,年龄较大和较小的婴儿的具体身体部位是不一样的。对于3个月以下的婴儿来说,人脸无处不在,在每小时的视觉体验中,人脸占15分钟以上。此外,这些脸始终靠近年幼的婴儿(在距离头部摄像机2英尺以内),并显示出两只眼睛。然而,当婴儿接近 1 岁生日时,头部摄像机记录下的面部图像已经很少见了,在醒着的每一个小时里,只有大约6分钟的时间有面部出现。相反,对于 1- 2 岁的孩子来说,他们可以看到其他人的手(Fausey et al., 2016)。这些手主要(超过85%的手的图像中)会接触和操作一些物体。这种婴儿面前视觉场景内容的变化是由他们的感觉运动能力的变化、父母相应的行为以及婴儿兴趣的变化所驱动的。在所有这些相互联系的力的作用下最终产生了用于视觉学习的数据。这些数据会发生变化——从许多全景式和近距离的面孔到许多作用于物体的手。我们强烈怀疑这个顺序——早期的面孔,后来的物体——这关系到人类视觉物体识别如何以及为什么以这种方式发展。
图2 头部相机的样本捕捉了三个不同年龄的婴儿的图像。
在构型人脸处理中,「沉睡效应」体现了早期密集的人脸视觉体验的重要性。Maurer et al. (2007)将沉睡效应定义为一种在发展后期出现的永久性缺失,但这是由于早期体验不足造成的。一个例子涉及婴儿在 2 至 6 个月大时因先天性白内障而丧失早期视力输入的情况。根据多项视力发展指标(包括敏锐度、对比敏感度),这些婴儿在白内障摘除后,开始追赶上同龄人,呈现出视力发展的典型轨迹。但随着年龄的增长,这些个体在人类视觉面部处理的成熟特征之一「构型面部处理」(configural face processing)中表现出永久性的缺失。构形处理是指基于一种类似格式塔的表征,它压制个体特征信息对个体面孔进行区分和识别的过程。这是人类视觉处理的一个方面,直到 5 - 7 岁时才开始出现(Mondloch et al., 2002)。Maurer et al. (2007)假设,早期的经验保存和/或建立了神经基质,用于较晚发展的面部处理能力(另见Byrge et al., 2014)。我们推测,婴幼儿密集的近距离、全视角面部体验是先天性白内障婴幼儿早期体验缺失的部分。因为这些经历与婴儿自身不断变化的偏向和感觉运动技能有关,所以当婴儿的白内障后来被摘除时,这些经历不会被他们的社交伙伴带来的经验所取代。因为到那时,婴儿自身的行为和自主性将产生非常不同的社交互动。因此,根据假设,早期密集的面部体验对于建立或维持大脑皮层回路可能是必要的,而大脑皮层回路支持后期出现的专门的面部处理。
有可能早期的面部体验只对面部处理重要,这是针对特定领域的结果的特定领域的体验。然而,我们有理由提出另一种观点。人类视觉皮层通过一系列特征提取和转换的层级系统构建我们所看到的世界(例如,Hochstein and Ahissar, 2002)。所有的输入都在相同的低层和所有较高的表示层中通过并进行调优——面孔、对象、字母——在低层的活动上进行计算。这样,对人脸的学习和对非人脸对象类别的学习都依赖于相同底层的精度、调优和激活模式。较低层次的简单视觉识别在较高层次的视觉过程中具有深远的普遍性(例如,Ahissar and Hochstein, 1997)。来自人类婴儿的头部摄像机图像表明,较低层次的最初调谐和发育是通过视觉场景完成的,其中包括许多闭着眼睛的面孔。正因为如此,儿童以后对非人脸物体特征的学习和提取至少在一定程度上是由较低层次的早期调谐形成的,这种调谐严重偏重于近距离人脸的低层次视觉特征。
虽然Maurer et al. (2007)使用「沉睡效应」一词来指代经验的缺失,但早期视觉体验对后来发展的作用同时具有消极和积极两方面的意义。个人早期经验中的结构规律性会对层次化的神经系统进行训练和调优,这样做可能建立潜在的隐藏能力,而这些能力对以后的学习起着至关重要的作用。人类发展的相关研究提供了许多目前无法解释的例子,它们说明了过去的学习对未来的学习有多么深远的影响。例如,通过点阵列视觉识别的准确性可以预测日后的数学成绩(Halberda et al., 2008),通过幼儿的形状偏向可以预测学习字母的能力(Augustine et al., 2015; 参见Zorzi et al., 2013)。与人类视觉系统相似,深度学习网络是「深度」的,因为它们包含层叠的层次结构。这种结构意味着,与人类视觉类似,在一个任务中形成的早期层表征将被重用。理论上它可以对在其他学习任务同时产生消极和积极的影响。对于这种分层学习系统,有序训练集的计算价值还没有得到很好的理解。从面部到手触物体的受限、但逐步发展的训练集的整个组合,是否就是解释 2 岁儿童只需要一个或几个实例就能够学会分类一种新的非面部物体的部分原因呢?
幼儿如何触类旁通
对 2 岁婴儿的头部相机图像的分析也告诉我们,这些图像中实体的分布既不是世界上实体的随机样本,也不是这些以自我为中心的图像中均匀分布的实体。相反,经验是极其右倾的。婴儿头部相机图像中的物体是高度选择性的——很少有哪个种类是普遍的,大多数物体是很少出现的。那么,这里有一个关键问题:通过广泛地(可能是缓慢地)学习某些东西,如何产生一个能够快速学习所有类别、包括一些不常见事物的学习系统呢?幂律分布既体现在婴儿对独特个体面孔的体验(Jayaraman et al., 2015),也体现在婴儿对物体的体验(Clerkin et al., 2017)。在婴儿出生后的一整年里,他们看到的面孔高度集中在少数几个人上,其中最频繁出现的三个人大约占头部相机图像中所有面孔的 80%。同样,婴儿视觉环境中的物体分布也极其右偏,一些物体类别比其他类别更频繁(Clerkin et al., 2017)。图 3 显示了 8- 10 个月大的婴儿在 147 次不同的餐桌时间(Clerkin et al., 2017)中,头部相机图像分析中常见物体类别的分布情况。很少有对象类别是普遍存在的,而大多数物体是很少出现的。有趣的是,最常见的物体类别的名称也是很早就获得的,但要在 8 到 10 个月,也就是第一个生日之后。这表明,早期密集的视觉体验为以后学习这些特定物体的标签做好了准备。
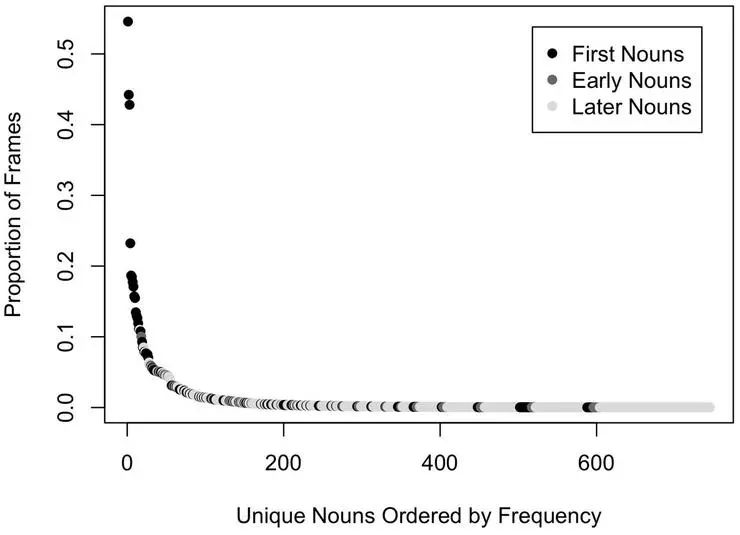
图3 8-10个月大婴儿头部相机图像中常见物体类别的分布(Clerkin et al., 2017)。对象类别根据其获取年龄进行着色(Fenson et al., 1994):第一名词(对象名称为至少50% 16个月婴儿的接受词汇),早期名词(对象名称不是第一名词和至少50% 30个月儿童的产出性词汇),以及后来的名词(所有其他对象名称)。
极右偏态分布的一个可能优势是,相对较小的个体对象和对象类别的普遍性,使婴儿能够定义学习的初始目标集(Clerkin et al., 2017;参见Salakhutdinov et al., 2011),然后掌握与在许多不同的观看条件下识别这些少数物体相关的视觉不变性。这可能是关键的一步——完成对一部分事物的学习——从而掌握从有限的经验中快速学习的通用能力,例如 2 岁儿童的形状偏差(Smith, 2013)。这种对一部分事物的完全了解可能不仅依赖于经验的数量,而且还依赖于经验在时间上的持续。当一个物体被长时间观察时,与该物体有关的视网膜信息必然会不断变化,显示出相关的转换和识别的不变性,这种不变性可扩展到识别新事物(Földiák, 1991;Wiskott and Sejnowski, 2002;Li and DiCarlo, 2008)。
控制饲养雏鸡的研究(Wood, 2013;Wood and Wood, 2016)为这一观点提供了一个论证:物体的缓慢变化转换为小鸡对物体形状的泛化学习提供了足够的输入。在这些研究中,新生的雏鸡在严格控制的视觉环境中长大,给它们观察移动和旋转的单个物体。通过一系列的控制饲养实验,研究人员们实验了不同的运动和旋转特性。结果表明,随着时间的推移,单个物体的观察经验就足以让小鸡建立健壮的物体识别技能,可以识别这个物体的未见过的视角以及从未见过的其它物体(Wood, 2013,2015)。控制饲养试验(Wood, 2016;Wood et al., 2016)也指出了小鸡学习的两个主要限制因素:缓慢和流畅。观察视角的变化需要缓慢而平稳地进行,并遵循物理对象在世界上的时空属性。不过,鸡的大脑和视觉系统与人类非常不同,因此小鸡数据的相关性不是人类视觉系统的动物模型。相反,这些发现的相关性在于,它们清楚地显示了单个视觉对象的时间上持续的体验中可用的信息。这可能也暗示了某种目前仍未开发出的算法,可以从对极少(或许只有一个)对象的扩展视觉体验中迅速学会识别对象类别。
自我生成的视觉体验
要测试幼儿对物体名称的了解程度,一种方法是向他们询问不同的物体名称,看他们表现出怎样的喜好,另一种方法是给他们展示一个物体,看他们是否会自发地说出它的名字。因此,幼儿的对象名称词汇是衡量他们视觉识别对象能力的一个很好的指标。在一岁之前,对象名称的学习开始得非常缓慢,儿童对单个对象名称的知识逐渐增长,最初以错误为特征(例如,MacNamara, 1982;Mervis et al., 1992, 参见Bloom, 2000)。大约 18 到 24 个月(不同的孩子学习时间不同),学习特性和学习速度会发生变化。大约 2 岁时,对象名称的学习变得似乎很容易,因为典型的成长中儿童只需要非常少的经验,通常只需要一个命名对象的单一经验,就而已适当地将名称推广到新实例(Landau et al., 1988;Smith, 2003)。从缓慢的渐进式学习向快速的几乎「一次性」学习的转变反映了学习本身所带来的内部机制的变化 (Smith et al., 2002)。然而,越来越多的证据表明,用于学习的视觉数据也发生了巨大的变化。
对于 8-10 个月大的婴儿来说,头部摄像头拍摄的场景往往杂乱不堪(Clerkin et al., 2017)。12 个月后的场景仍然经常是杂乱的,但是这些场景被一系列连续的场景打断。在这些场景中只有一个物体在视觉上占主导地位(例如Yu and Smith, 2012)。场景构成的变化是幼儿动手能力发展的直接结果。早在一岁之前,婴儿就会伸手拿东西,但他们缺乏长时间玩耍所需要的躯干稳定性(Rochat, 1992;Soska et al., 2010)。他们缺乏旋转、堆叠或插入对象的动手能力(Pereira et al., 2010;Street et al., 2011)。此外,他们最感兴趣的是把物体放进嘴里,这并不是理想的视觉学习。因此,他们经常从远处看这个世界。而从远处看,这个世界是许多杂乱的东西。在他们的第一个生日之后,这一切都改变了。幼儿在积极地处理物体时,并会近距离地观察它们。这种动手活动会促进更高级的视觉对象记忆和区分(Ruff, 1984;Soska et al., 2010;Möhring and Frick, 2013;James et al., 2014a)以及对象名字学习 (例如Yu and Smith, 2012;LeBarton and Iverson, 2013;James et al., 2014a)。
幼儿的视觉系统生成的画面视角有三个特性,可能是这些进步的基础。
首先,幼儿对物体的处理创造出的视觉场景比年纪更小的婴儿(Yu and Smith, 2012;Clerkin et al., 2017)和成人(Smith et al., 2011;Yu and Smith, 2012)的都要整洁。幼儿胳膊短,身体前倾,仔细看着手中的东西。在此过程中,它们创建一个对象填充视野的场景。这解决了许多基本问题,包括分割,竞争,以及参考对象不明。一项研究(Bambach et al., 2017)直接比较了一个常用的 CNN(Simonyan and Zisserman, 2014)在给定的由幼儿和成人头部摄像机图像组成的训练集(相同的真实世界事件)中学习识别物体的能力。该网络不提供待训练对象的裁剪图像,而是完整的场景,没有目标对象在场景中的相关位置信息。根据幼儿阶段画面学习到的系统比成人阶段的更健壮,并且表现出更好的泛化能力。这与当代计算机视觉的实践相吻合,计算机视觉的算法通常会在裁剪的图像或场景中加入边框,以指定要学习的对象。幼儿做到这一点的方式则是借助自己的手和头。
初学走路的孩子处理物体的第二个特点是,他们会生成单一物体的可变性很强的图像。图 4 显示了一个 15 个月大的幼儿在玩耍时生成的单个对象的视图(Slone et al., 审稿中)。在这项研究中,头戴式眼球追踪器被用来捕捉第一人称场景中的固定物体。一种单一的算法测量,掩膜取向(mask orientation,MO)被用来捕捉婴儿注视的物体的逐帧图像变异性:MO是图像中物体像素最细长轴的方向。至关重要的是,这不是一个面向真实世界或对象形状的方法,也不以任何直接的方式涉及的形状特性远端刺激,而是通过衡量近端图像属性的视觉系统来确定远端对象。主要结果是:15个月大的婴儿在玩玩具时所产生的MO变化量可以预测在6个月后,也就是21个月大的时候婴儿掌握物体名称词汇量。简而言之,更大的差异性导致更好的学习。在一项相关的计算研究(Bambach et al., 2017)中,研究人员们向 CNN 提供了一组训练集,这些训练集由父母或孩子佩戴的头部摄像机拍摄的共同玩耍事件的图像组成。相对于从父母佩戴的相机中看到的相同物体的变化较小的图像,从儿童佩戴的相机中看到的变化较多的物体图像导致了更强的学习能力和学习泛化能力。这些发现应该会改变我们对一次性学习的看法。幼儿对一个物体的视觉体验不是单一的体验,而是对同一事物的一系列非常不同的观察。这样的一系列对单个实例的不同观察能否引导年轻的学习者使用生成原则来识别某个类别所有成员(例如,所有的拖拉机)?
图4 一个15个月大的婴儿在玩耍时用头部照相机捕捉到的单个物体的样本图像。
幼儿自生成对象视图的第三个属性是他们倾向于(Pereira et al., 2010)让大多数对象的长轴垂直于视线(简单的握持方法),也会让(尽管更弱)长轴平行于视线(最简单的将一个对象插入另一个对象的方法)。幼儿通过旋转物体的主轴,在这些喜欢的视图之间转换。这些不同的视角和旋转突出了非偶然的形状特征。由手握物体的方式所产生的不同视角可能有一个视觉来源,因为当幼儿握着并查看透明球体中包含的物体时,这种偏差会更强(James et al., 2014b)。这样所有的视图对于手来说都是等势的。Wood (2016)在对小鸡的研究中提出了平滑性和缓慢变化的约束条件,但是,无论是正确的分析还是正确的实验都没有将这些自生成的物体视图的属性与这些约束条件进行比较。但是,考虑到物理世界和物理身体的时空限制,我们完全有理由相信,幼儿会遵从自生成的视图。
幼儿的全身视觉训练方法创造了独特的视觉训练集,这些训练集的结构似乎是为了教授一门非常具体的课程:独立于视觉的三维形状识别。单个对象在图像中是孤立的,因为它填充了图像。不同的视图通过时间上的接近和手的接触相互连接,这提供了一个强有力的学习信号,表明两个不同的视图属于同一个对象。视图的动态结构突出显示了非偶然的形状属性。这是视觉目标识别中的一个难题,可以通过数据本身的结构来解决。
幼儿成长和机器学习之间的互相借鉴
婴幼儿的视觉环境会随着发展而变化,他们会将不同的学习任务进行分类和排序,这样以后的学习就可以建立在之前在不同领域学习的基础上。在每个领域中,训练集集中于有限样本的个人实体—— 2 到 3 个人的脸,一个小的普遍的对象集,一个对象的多个视图——但这些经验构建了如何识别和了解许多不同种类的东西的通用知识。这不是从有限的数据中学习的情况;数据是巨大的——关于你母亲的脸,关于你的吸嘴杯的所有视图。这些训练集的整体结构与计算机视觉中常用的训练集有很大的不同。它们能成为更强大的机器学习的下一个进步的一部分吗?
机器学习没有采用发展的多阶段方法进行训练,但已经取得了巨大的进步。有争议的是,不需要这种辅导和结构化课程的学习机是否更强大。事实上,使用有序训练集(Rumelhart and McClelland, 1986)并在学习过程中增加难度的连接主义语言发展理论被强烈批评为作弊(Pinker and Prince, 1988)。但是,被批评的观点从发展的角度看是正确的(Elman, 1993)。目前有一些机器学习方法(例如课程学习和迭代教学)试图通过有序和结构化的训练集来优化学习(例如Bengio et al., 2009;Krueger and Dayan, 2009)。这些努力并没有过多地担心婴儿自然学习环境中的结构;这可能是人类和机器学习的有益结合。然而,婴幼儿学习的数据不仅是在发展过程中有序排列的,而且是由学习者自己的活动实时动态构建的。输入在任何时刻都取决于学习者的当前状态,并且会随着学习者内部系统作为学习功能的变化而实时变化。这样,在任何时间点提供的信息可能是最适合当前学习状态的,在正确的时间提供正确的信息。目前机器学习的一种相关方法是在学习过程中对深度网络中的注意力进行训练,使选择的学习数据随着学习的变化而变化(Mnih et al., 2014;Gregor et al., 2015)。另一种方法是在学习过程中利用好奇心将注意力转移到新的学习问题上(Oudeyer, 2004;Houthooft et al., 2016; 参见Kidd and Hayden, 2015)。我们如何将发展洞察力融入机器学习?Ritter et al. (2017)以机器学习者为研究对象的「认知心理学」实验,研究了机器学习者如何从缓慢渐进的学习者成长为具有儿童所表现出的形状偏向的「一次性」学习者。这些实验可以操纵结构的训练集(见Liu et al., 2017)以及算法。这些算法用于理解早期学习如何限制后期学习,以及一点点的学习如何泛化,大量的学习对比很多事情却只学一点。
当然,没有人能保证,通过追求这些理念,机器学习者就能建立强大的算法,赢得当前的竞争。但是,这样的努力似乎肯定会产生新的学习原则。这些原则——以算法形式表达——将构成理解人类学习和智力的一大进步。
-
神经网络
+关注
关注
42文章
4771浏览量
100772 -
人工智能
+关注
关注
1791文章
47279浏览量
238511 -
视觉识别
+关注
关注
3文章
89浏览量
16737
原文标题:机器学习如何借鉴人类的视觉识别学习?让我们从婴幼儿的视觉学习说起
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
微表情识别-深度学习探索情感






 工商网监
工商网监
评论