 专用NPU是发挥端侧人工智能潜力的捷径
专用NPU是发挥端侧人工智能潜力的捷径
1971年,第一颗划时代的大规模集成电路产品Intel4004出现,它使用MOSFET集成电路技术,采用10μm工艺,集成了2300个MOSFET。虽然这颗IC仅仅集成了2300个晶体管,但它标志着人类大规模集成电路时代正式开启,而且它开辟了一条提升IC性能的路径——同样面积下,要提升性能就要集成更多晶体管,要集成更多晶体管只要升级工艺就可以实现。
自此之后,人类一直就享用着IC工艺升级带来的红利。根据Intel的创始人之一戈登·摩尔(GordonMoore)提出的摩尔定律:集成电路上可容纳的晶体管数目,约每隔18个月便会增加一倍,性能也将提升一倍。50 年来,IC工艺在摩尔定律的指导下飞速发展,我们也一直在享用工艺技术升级带来的好处——性能升级,功耗降低,尺寸越来越小。
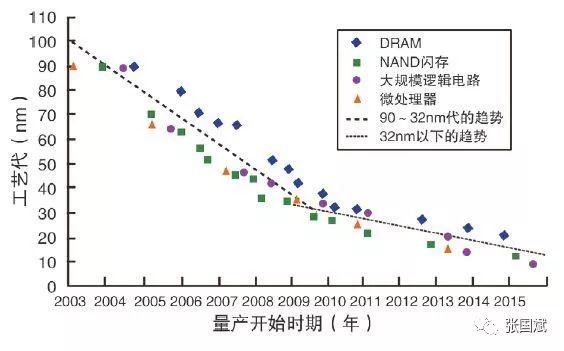
但是,当工艺scaling到10nm以下时,由于工艺复杂度大幅度提升,摩尔定律已经趋缓。2018年11月,AMD CTO发表言论认为摩尔定律已经减缓;6月份美国举办的DAC大会上,著名计算机领域专家2018图灵奖获得者David Patterson(开源CPU RISC-V发明人之一)也明确认为摩尔定律已经减缓;而且,英特尔自己的10nm工艺连续跳票,不能按时交付新工艺芯片。这些言行都说明,依靠半导体工艺升级带来IC器件性能提升,已经不可能再像以前那样继续维持高速提升了,那该如何提升处理器性能?尤其是提升人工智能的处理效率?
架构创新是出路,AI时代需要专用处理单元
David Patterson 认为现在是计算机系统架构的黄金时代,单靠工艺升级难以实现大的性能突破,未来处理器必须从架构上寻求出口。
而根据业内众多半导体专家的观点,异构架构是未来IC发展的必由之路。*** 半导体产业协会理事长卢超群博士(Nicky Lu)就认为,异构集成设计系统架构(HIDAS, Heterogeneous Integration Design Architecture System)将大量促进IC创新,要提升IC性能就要集成新的异质单元。 同理,对于目前热门的人工智能处理需求来说,通过工艺升级CPU或者GPU、DSP、FPGA都不是好办法,更合理的方案是就集成人工智能处理单元。
人工智能到底需要一种什么样的处理单元?想要寻找答案,我们可以回头看看GPU的发展历程。
1962年,麻省理工学院的博士伊凡•苏泽兰发表的论文以及他的画板程序奠定了计算机图形学的基础。在随后的近20年里,计算机图形学在不断发展,但是当时的计算机却没有配备专门的图形处理芯片,图形处理任务都是CPU来完成的。
1999年8月,NVIDIA公司发布了一款代号为NV10的图形芯片Geforce 256。Geforce 256是图形芯片领域开天辟地的产品,因为它是第一款提出GPU概念的产品。Geforce 256所采用的核心技术有“T&L”硬件、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。“T&L”硬件的出现,让显示芯片具备了以前只有高端工作站才有的顶点变换能力,同时期的OpenGL和DirectX 7都提供了硬件顶点变换的编程接口,GPU的概念因此而出现。由此开始,CPU、GPU 才正式确立了各自的属性和工作内容。
从结构上来说,CPU和GPU不同之处体现在他们处理任务的方式不同。CPU由专为串行任务而优化的几个核心组成;GPU则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。稍微深入一点来讲,CPU和GPU的不同,是因为它们的使命不同。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断,又会引入大量的分支跳转中断的处理,这使CPU的内部结构异常复杂。而GPU需要处理的则是类型高度统一、相互依赖的大规模数据和不需要被打断的计算环境。因此,GPU和CPU就呈现出非常不同的架构。
从GPU的发展来看,它的出现在于首先要应对新的处理需求——图形处理,其次是要以不同于CPU的架构来完成处理效率最大化。这两点对人工智能处理也有借鉴意义:首先,人工智能处理是不同于CPU和GPU的新处理需求;其次,人工智能处理需要新的架构,因为无论CPU、GPU还是FPGA都不是最好的架构,尤其是在手机领域FPGA更不适合。
我们知道,手机是消费电子中最大的品类,在工艺、封装、集成、架构方面都走在行业最前沿,它的技术也在引导着整个半导体行业的发展。一方面,手机SoC使用最新的工艺制程;另外一方面,手机也是对功耗、面积特别敏感的产品品类。用CPU,GPU这些面向传统指令计算、浮点运算的计算单元,去执行以张量计算为主的AI运算,效率和能效都不能达到最好,同时随着传统半导体工艺制程不断逼近极限,如果还用摩尔定律的增长红利去满足日益提升的AI运算量,代价会越来越高。
另外,AI的框架、算法和网络模型发展也非常快,如果采用CPU,GPU适配日新月异的AI框架和算子,软件适配等工作也非常繁多,这不仅为开发者带来更高的开发成本,更同时加大了产品上市的时间成本。如果采用FPGA,虽然人工智能的处理效率会大大提升,但是FPGA的面积和功耗都不适合集成在手机平台;如果采用DSP,虽然有一定的灵活性,但是效能还不是最大。因此,借鉴GPU的发展,从最优能效角度考虑,手机平台需要集成专用的NPU,让专业的器件干专业的事情。
专用NPU性能强劲,麒麟芯片引领端侧AI应用潮流
毫无疑问,手机平台需要专用的NPU。在这方面,华为大胆尝试,在2017年9月率先推出了集成专用NPU处理单元的麒麟970。麒麟 970采用了创新的HiAI移动计算架构,能够用更少的能耗更快地完成AI计算任务。实际对比显示:性能上,NPU 是 CPU 的 25 倍,是GPU 的 6.25 倍(25/4);能效比上,NPU 更是达到了 CPU 的 50 倍,GPU 的 6.25 倍(50/8)。
实测中,麒麟 970 的 NPU 每分钟可以识别出 2005 张照片,而在没有NPU的情况下每分钟只能识别 97 张,优势对比非常明显。
麒麟970是史上首个在端侧实现人工智能推理应用的手机芯片平台。笔者在芯片发布之初就判断,华为将凭借这个新的计算平台领先高通的骁龙平台,并将在人工智能应用方面,帮助华为手机与其他手机拉开至少4个月的领先期。事实果真如此,麒麟970开启了端侧人工智能应用的新篇章,并助力华为Mate10手机率先实现了拍照场景识别、翻译等人工智能应用,引领了整个智能手机的AI应用大潮。
2018年9月,华为在2018德国柏林消费电子展(IFA)上正式发布麒麟980处理器。麒麟980在AI方面有了更大的突破:首度采用了双核NPU,提供147个算子,人工智能算力大幅度提升;每分钟识别4500张图片,识别速度相比上一代提升120%,远高于业界同期水平。
麒麟980的发布,标志着华为在端侧人工智能领域的成熟与进步。独立的双核NPU处理单元让麒麟980在人脸识别、物体识别、物体检测、图像分割、智能翻译等AI场景下应用更流畅。例如华为Mat 20系列可实现多人姿态实时识别,实时帧率高达30 FPS,无论是表演节奏感极强的舞蹈,还是在镜头前快速跑步,麒麟980都能够实时绘制出人体的关节和线条。可以说,麒麟980再次引领了全球端侧AI应用的潮流。
另外,基于独立的NPU处理单元,华为从麒麟970开始就推出了HUAWEI HiAI。HiAI是面向移动终端的AI能力开放平台,是专门为了配合NPU进行开发的第三方开发者平台,能够给开发者提供AI计算库以及API,并且能够便捷地编写APP上的AI应用。
HUAWEI HiAI能力开放平台分为三层架构,除了我们熟知的HUAWEI HiAI Foundation的运算能力、HUAWEI HiAI Engine端侧应用能力,还有海量的HUAWEI HiAI service服务能力。此外,HiAI能够让开发者快速迁移模型,并且对于普通APP开发者来说,HiAI会提供已封装好的语音识别等技术,开发者能够直接应用。
HUAWEI HiAI堪称是一个开发人工智能APP的神器,能帮助小白用户迅速开发出AI应用,而且能用上麒麟芯片的NPU能力。开发者可以利用这个开放架构开发新的人工智能应用,并通过华为认证后集成进麒麟平台。这是超越APP应用的新机制,开放的架构让华为率先拥有了大量编外人工智能开发者,这也意味着麒麟平台可以集成大量第三方的人工智能算法和应用。
如今,专用NPU在人工智能领域的应用已成燎原之势。笔者观察到,业界其他芯片厂商也在采用这样的独立NPU架构,例如苹果A12、联发科的P系列平台等。在安防领域,独立NPU已经推动智能安防发展,一些IP公司也开发出了专用NPU IP如Imagination的PowerVR 2NX NNA加速器、PowerVR 3NX NNA等。反之,某些没有集成独立NPU的芯片平台,依旧在通过CPUGPU和DSP进行人工智能运算,不但增加了功耗,影响其他运算任务的处理,还加大了第三方人工智能算法和应用接入的难度。
目前,人工智能已成人类的一项通用技术。人类会用AI技术和理念去解决现在和未来的问题, AI也必将会与更多产业应用结合,从而改变所有行业,更将改变每个组织。人工智能在语音识别、图像识别、工业、汽车自动驾驶、农业、AR、VR等领域的应用潜力无限,而华为麒麟系列芯片在端侧人工智能领域的探索处于全球领先,华为手机卓越的人工智能应用体验也应证了专用NPU架构的选择是非常明智和正确的,期待华为在这个领域的探索更深入,带给我们更多惊喜。
-
MOSFET
+关注
关注
146文章
7151浏览量
213095 -
人工智能
+关注
关注
1791文章
47164浏览量
238147 -
NPU
+关注
关注
2文章
278浏览量
18582
原文标题:发挥端侧人工智能潜力,专用NPU才是王道
文章出处:【微信号:FPGA-EETrend,微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论