 如何从Facebook的2018年的成长中获取养分
如何从Facebook的2018年的成长中获取养分
Facebook在2018年过的并不好,一连串的数据泄露丑闻打的小扎和他同事措手不及。
但是,一年的时间,Facebook仍然做出了许多的成绩,尤其在AI方面,这家社交媒体公司利用人工智能开发了许多的应用。例如智能推荐系统,例如对一些色情内容进行识别的智能识别工具等等。
抛去那些不好的事情,我们如何从Facebook 的2018年的成长中获取养分?相信下面这篇Facebook 2018年的工作总结可以给你带来一些灵感。
这篇文章,发布在code.fb.com上,大数据文摘有删改的进行了编译。
Facebook瞅准AI发展的眼光一直很在行,在这一领域里的行动也从未停止。
我们不满足于在当前机器学习瓶颈的发展,而是希望找寻更新、更高效的学习方式。我们抱有利用AI造福世界的信念和对机器学习研究的坚持,我们的工程师将更多前沿的算法和工具开源到AI社区,例如Pytorch深度学习的开源框架及其升级,更新后的Pytorch还专门开发了支持新手的接口,使得他们更容易接触深度学习,在一定的程度上推动了相关AI项目的落地。
除了一些论文和数据集之外,还有一些很棒的日常生活助手,比如加持人工智能的MRI扫描变得更加高效了,在救灾工作和预防自杀方面也有提高。
2018年,我们找到了使用较少监督数据进行相关研究的可行性的方法,也将研究项目从最初的图像识别扩展到了语言的翻译和理解。
通过半监督和无监督培训推进AI学习
当前,大多数AI系统更多使用的还是监督式学习,这意味着他们必须使用大量被标记过的样本才能进行学习任务,而这些样本数量对于训练需求来说是严重不足的,因而这也就限制了技术长期发展的潜力,而想要改变以上问题可能需要多年的研究。
Facebook AI Research(FAIR)小组成立后,在人工智能研究上进行了多样的探索。2018年,该小组使用了无监督机器翻译,通过减少对标记训练数据的依赖,打开了翻译“小语种”的大门,让我们的系统支持更多的语言翻译。
主要采用多种方法来避免标签训练数据不足的问题,包括使用多语言建模来利用给定语言组中方言之间的相似性,例如白俄罗斯语和乌克兰语、乌尔都语等语言的资源目前都很少,与英语相比,他们现有数据集十分有限。
虽然使用的是无监督的数据,但是它的性能却能与“打标签”数据训练的系统相媲美。现在无监督方法有了更实质性的改进。
这就是为什么我们要探索更多的训练方法,让监督学习变得不再那么重要的原因。半监督和无监督式的学习方法或许是不错的选择。
在这项研究在今年已经被应用。并且为自动翻译软件增加了24种语言。此外,在与纽约大学合作过程中,我们为现有的MultiNLI数据集添加了14种语言,这些数据集广泛用于自然语言理解研究,此前仅有英语版本。
我们最新的XNLI数据集中包括两种低资源语言:斯瓦希里语和乌尔都语,这一方法有助于整体采用跨语言的语言理解,从而减少了对标记数据的需求。
为了研究基于标签的图像识别,我们颠覆了传统的研究方法,新的方法能够使得数据进行自我标记并形成大型训练集,例如35亿个公开的Instagram图像就是用这么形成的。
我们的结果不仅证明使用数十亿个数据点对于基于图像的任务非常有效,而且它还使我们打破了一个记录,比ImageNet上先前最先进的图像识别模型的准确率高出一个百分比。
Hashtags可以帮助计算机视觉系统快速识别图像的额外信息以及特定的子类。
加快人工智能研究和产业应用的融合
AI已成为Facebook几乎所有产品和服务的基础。这点从我们的工程师正在构建和增强的各种基于AI的平台和工具中可以看出。
但是在2018年Facebook有了一个共同的主题:如何将人工智能技术嵌入到人工智能系统中。
自2017年PyTorch发布以来,深度学习框架已被AI社区广泛采用,它目前是GitHub上增长速度第二快的开源项目。 PyTorch的用户友好界面和灵活的编程环境使其成为AI开发中快速迭代的通用资源。由于代码库的贡献和反馈,其开放式设计确保了框架将继续改进。对于2018年,我们希望为PyTorch社区提供更加统一的工具集,重点是将他们的AI实验转变为生产就绪的应用程序。
我们在5月份的F8会议上发布了更新的框架,我们详细介绍了它的原型系统和设置,以及它是如何集成Caffe2模块的。还有产品为导向的能力和新扩展的ONNX。这一切都简化了整个AI开发流程。
10月,我们在第一届PyTorch开发者大会上发布了PyTorch 1.0开发人员预览版。也展示了该框架的平台生态系统。谷歌,微软,NVIDIA,特斯拉和许多其他技术提供商在该活动中对PyTorch 1.0进行讨论,且fast.ai和Udacity都上线了新版本课程,教授深度学习。
我们在本月早些时候完成了PyTorch 1.0的推出,放出了其完整版本的所有功能,例如在eager和图形执行模式之间无缝转换的混合前端,改进的分布式训练,以及纯C ++前端,用于高性能研究。
我们今年还发布了一些工具和平台,扩展了PyTorch的核心功能,包括一对内核库(QNNPACK和FBGEMM),它可以使移动设备和服务器更容易运行最新的人工智能模型。还有一个加速自然语言处理开发的框架—PyText。
PyTorch还为Horizon提供了基础。Horizon是第一个使用应用强化学习(RL)来优化大规模生产环境中的系统的开源端到端平台。
Horizon对RL进行了大量研究,但很少尝试进行决策,也没有用于那种可能包含数十亿条记录的数据集的应用程序。 在Facebook内部部署平台后,在优化流视频质量和改进Messenger中的M建议等用例中,我们使Horizon开源桥接RL研究和生产,让任何人都可以下载。
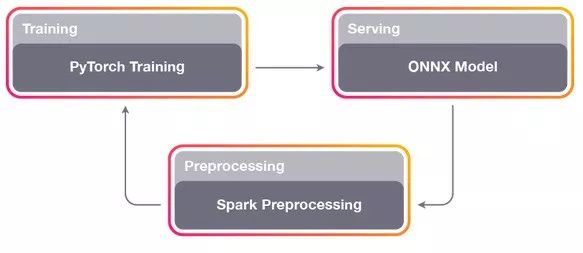
这是一个显示Horizon的反馈路径的高级图表。首先,我们预处理现有系统记录的一些数据。然后,我们训练模型并在离线设置中分析反事实政策结果。最后,我们让专门人员配置模型,衡量真正的政策。新模型的数据反馈到下一次迭代,大多数团队每天都会部署一个新模型。
我们还发布了Glow——一个开源的、社区驱动的框架。其支持机器学习(ML)的硬件加速。Glow与一系列不同的编译器,硬件平台和深度学习框架(包括PyTorch)合作,现在由包括Cadence,Esperanto,Intel,Marvell和Qualcomm Technologies Inc.在内的合作伙伴提供支持。
为了进一步鼓励在整个行业中使用机器学习,我们发布了一种新的机器学习优化服务器设计,称为Big Basin v2,作为开放计算项目的一部分。我们已将新的模块化硬件添加到我们的数据中心机队中,并且任何人都可以在OCP市场下载Big Basin v2的规格。
2018年标志着Oculus Research转变为Facebook Reality Labs,以及对AI和AR / VR研究重叠的新探索。作为我们尽可能多地开源人工智能相关工具的持续努力的一部分,我们发布了DeepFocus项目的数据和模型,该项目使用深度学习算法在VR中渲染逼真的视网膜模糊。
在未来一年,我们希望获得有关所有这些版本的更多反馈。我们将继续构建和开源工具,完成PyTorch 1.0的使命,帮助整个开发人员社区从实验室和研究论文中,提取最先进的AI系统并投入生产。
建立有益于每个人的AI
我们在开发非常广泛的AI技术的技术方面有着悠久的历史记录。在过去的一年中,我们继续部署应用人工智能的工具使世界受益,包括我们对自杀预防工具的扩展开发,这些工具使用文本分类来识别那些表达自杀的想法和语言的帖子。该系统使用单独的文本分类器来分析帖子和评论,接着如果可以的话,将它们发送给我们的社区运营团队进行审核。
该系统利用我们已建立的文本理解模型和跨语言功能,让我们能够接触到需要获得服务的人群数量得到提升。
我们还发布了一种使用AI的方法,可以快速准确地帮助查明灾难影响最严重的区域,而无需等待手动标注数据。
这种方法是与CrowdAI合作开发的,能够以更快速和更高效为受害者提供援助。将来,这项技术还可用于量化森林火灾,洪水和地震等大规模灾害造成的破坏程度。
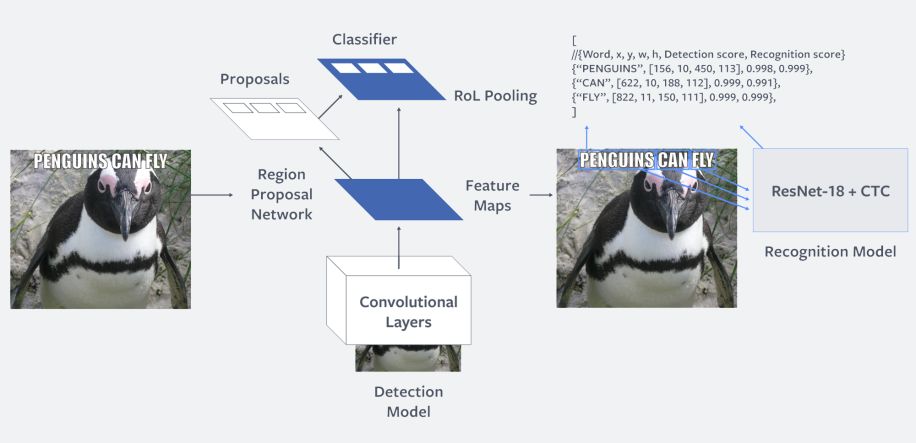
我们部署了一个名为Rosetta的机器学习系统,每天从超过十亿个公共图像和视频帧中提取文本,并使用文本识别模型一起理解文本和图像的上下文。 Rosetta适用于多种语言,它自动识别有助于我们了解模因meme(目前比较公认的定义是“一个想法,行为或风格从一个人到另一个人的传播过程。)和视频或违反政策内容。
2018年,一个与纽约大学医学院的长期合作的项目—fastMRI启动。这个项目的目标是改进现有的诊断成像技术,使MRI扫描速度提高10倍。
fastMRI的目标不是开发专有流程,而是为了加速该领域技术。我们的合作伙伴已经为这项研究制作了有史以来最大的全采样MRI原始数据集(由纽约大学学院完全匿名发布),以及开源模型,可以帮助更广泛的研究群体开始这项任务。我们还推出了在线排行榜,其他人可以发布并比较他们的结果。
-
AI
+关注
关注
87文章
32302浏览量
271398 -
Facebook
+关注
关注
3文章
1432浏览量
55236
原文标题:Facebook全年成果总结:我们在AI领域的行动从未停止
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
获取通信事件计数器与获取通信事件记录
90后程序员的职业成长漫谈

PCM1808的主模式和从模式在应用上有什么区别?用从模式可以测量从MIC获取到的音量是多少分贝吗?
我在京东做产研 校招 2 年,个人角度(成长)回顾 - 行且知
从校招新星到前端技术专家的成长之路
AT+CIPSNTPTIME为什么不能获取正确时间?
如何从帧控制中获取WEP位?
在ethernet_input函数中从以太网模块获取数据就会崩溃的原因?
芯盾时代入选“2023年度中国高科技高成长企业系列榜单”

云知声荣登“2023年度中国高科技高成长企业系列榜单”







 工商网监
工商网监
评论