 使用MCU的存储器架构降低功耗并优化系统成本
使用MCU的存储器架构降低功耗并优化系统成本

现代MCU具有各种存储元件,了解其组织,性能限制和功耗对于有效实施应用程序至关重要。特别是,用于代码存储的片上闪存的特性,用于数据存储的片上SRAM的组织以及片外存储器的访问特性将对整体处理效率产生巨大影响。让我们分析一下这些关键的存储器元件,以便更好地了解如何最有效地使用它们来最大限度地提高性能,降低功耗并优化系统成本。
片上闪存
片上闪存可能是最关键的任何应用程序中的内存元素,因为它通常是处理器的所有指令的源。如果没有有效地获取指令,则整体MCU性能将受到影响。向CPU提供指令有两种不同的方法。在一种方法中,存储器根据需要快速操作以匹配CPU的指令周期。例如,瑞萨RX600群使用先进的闪存技术,提供对指令存储器的高性能零等待状态访问。这种方法可以简化CPU架构和确定性时序。
访问闪存通常使用双端口方式进行CPU访问,通过高速总线进行读取操作和更慢访问,使用闪存控制器进行写入操作。 RX600的闪存接口如图1所示。请注意,闪存进一步分为数据闪存部分,用于存储经常修改的非易失性信息,以及指令部分,通常被视为读取仅存储器(ROM),即使它使用Flash技术,并且可以在制造期间或通过系统更新由用户多次重新编程。闪存控制单元(FCU)是一个独立的专用处理器,可管理闪存写入并具有自己的RAM和固件存储器块。 CPU可以启动FCU操作;这是使用图1顶部所示的外设总线实现的。
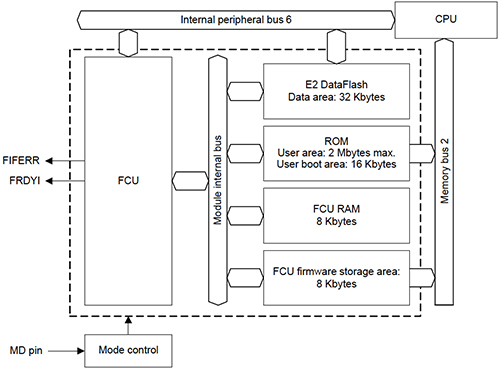
图1:瑞萨RX600 MCU的闪存接口(由Renesas提供)。
另一种架构使用比CPU时钟慢的指令存储器,可能需要插入等待状态。这可以显着降低处理性能,因此通常在CPU和较慢的指令和数据存储器块之间插入高速缓冲存储器。高速缓存存储最近的存储器访问,并且如果再次需要相同的指令或数据元素,则可以在不必访问较慢的主存储器块的情况下使用它。 Atmel SAM9G MCU的数据和指令高速缓冲存储器的组织如图2所示.16 KB存储器提供快速的本地存储,减少了CPU通过多路复用访问大型Flash ROM或SRAM块所需的次数。层AHB矩阵。请注意,使用本地高速缓存存储器的能力也减少了总线矩阵流量,因此DMA或外设访问将具有额外的总线带宽。
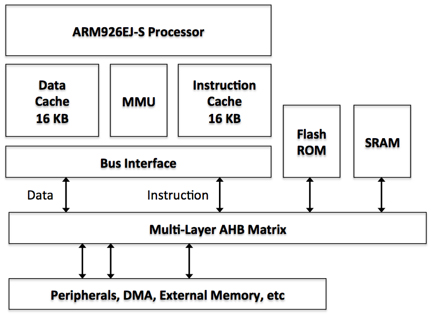
图2:Atmel的SAM9G MCU的高速缓存存储器接口。
如果高速缓存存储器是高效的,整个“内部循环”可以适应高速缓存,这可能导致应用程序的最关键部分几乎为零等待状态性能。注意,在该方法中执行定时可能更难以估计,因为高速缓存“未命中”导致意外的处理减速。另外,如果一个小的内部循环不可用,或者数据的组织方式使得缓存算法所依赖的“位置”被违反,则处理可能变得非常低效。然而,一般而言,由于大多数算法的局部特性,缓存算法已被证明可以提高效率。
更复杂的缓存架构
高带宽计算密集型MCU,如德州仪器面向DSP的TMS320DM814x视频处理器,高速缓冲存储器系统可以具有额外的复杂程度。 TMS320DM814x的处理器到存储器接口(图3)具有三种不同级别的存储器层次结构。最接近处理器的是两个1级(L1)高速缓存存储器,一个用于指令,一个用于数据。当所需数据不在L1高速缓存中时,向2级(L2)存储器发出请求。 L2存储器是多端口存储器,具有多个存储区以进一步组织数据。带宽管理用于每个高速缓存控制器,以管理存储器访问的优先级,以保持数据顺畅地流入和流出处理器。最多可提供9个优先级,如果低优先级访问被阻止时间过长(超过Max_Wait周期),则可以优先考虑优先级。
这种多级内存架构在高带宽时并不少见是必需的,包含优先级和其他高级管理功能对于减轻优化带宽的负担至关重要。尝试识别包含高效缓存,智能带宽管理功能和多个内存端口的MCU,以自动优化内存带宽。
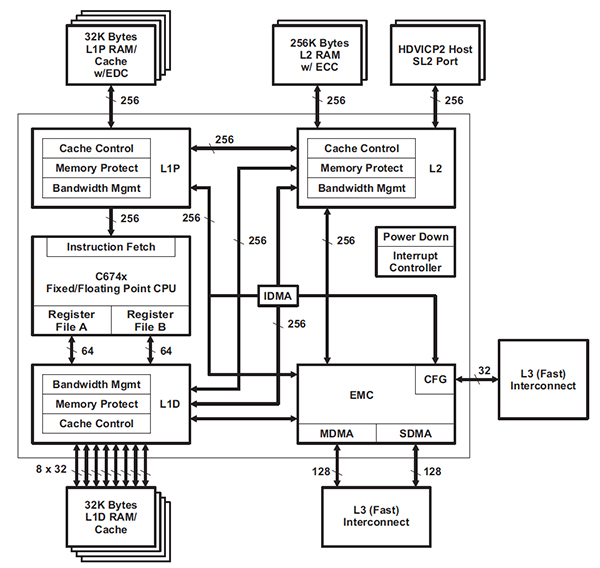
图3:德州仪器的TMS320DM814x DSP内存接口架构(图片提供)德州仪器(TI))。片上SRAM
需要了解片上SRAM的组织,以便在应用中组织数据元素以获得最佳效率。在许多情况下,MCU将SRAM组织成单独的块,可以由总线主机独立访问以重叠并提高数据传输效率。恩智浦半导体LPC15xx MCU将SRAM分成三个不同的模块,每个模块通过多级AHB矩阵可用于处理器,USB或DMA主设备,如图4顶部所示。图中底部显示了SRAM模块的特性,如SRAM模块的特性。作为大小,地址范围,以及是否可以禁用它以节省每个LPC15xx系列成员的电源分配不同大小的SRAM模块并不罕见,无论是从处理角度还是从功率角度来看,都可以帮助您以最有效的方式对设计进行分区。让我们更详细地了解如何智能地将您的算法要求与SRAM块组织相匹配,从而提高处理能力和功率效率。
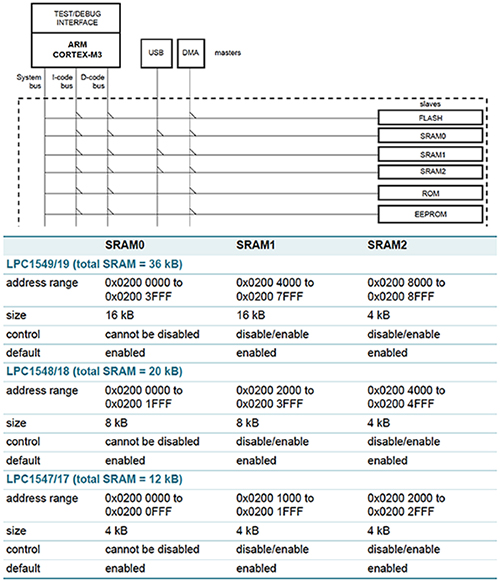
图4:通过AHB矩阵将NXP LPC15xx SRAM连接到总线主控器和SRAM模块特性(恩智浦提供)。
提高处理效率
基于MCU的设计中最常见的效率改进之一是使用DMA功能从CPU卸载简单的数据传输功能。如果CPU可以进入休眠模式或与数据传输并行处理,则整体效率得到提高。多个SRAM块的存在可以成为支持无冲突并行操作的重要元素。此外,同样具有多级总线接口的高级MCU,如NXP LPC15xx,可以提供对共享资源的优先访问,以自动提高处理效率。例如,如果算法必须通过USB接口接收数据,则处理数据,存储数据,当有足够的数据可用时,通过另一个接口发送结果,各种数据缓冲区的位置对整体性能至关重要。最好将输入和输出缓冲区分成不同的SRAM块,因此来自CPU,DMA和USB端口的主控请求不会同时尝试访问同一个块。为主访问建立正确的优先级设置将有助于消除算法停顿。确保在数据处理中以更高的优先级捕获接收的数据对于消除数据接收错误和冗长的重试周期至关重要。了解算法的数据流要求是有效利用内存块的关键要求。
如上图4的下半部分所示,可以启用或禁用某些NXP LPC15xx SRAM模块以降低功耗。组织数据以利用这一点可以有助于实现积极的电力目标。例如,许多算法在CPU计算期间使用数据缓冲区来存储大数据。计算完成后,无需保存该数据,并且可以禁用相关的存储器块以节省电量。如果SRAM存储器块在使用之前需要一些额外的时间来“唤醒”,则始终启用的SRAM块中的较小缓冲区可以存储数据,直到新启用的块准备就绪。在某些情况下,需要进行详细的计算以确定这些电源管理技术可以产生的节能量(如果有的话);但是具有多个具有省电选项的SRAM模块通常可以提高功率效率。
外部存储器接口
访问片外存储器资源会增加显着的延迟,因此寻找缓冲片内数据和预取存储器的机会从片外可以显着提高整体带宽。将片上存储器缓冲器匹配到适当的片上SRAM块是重要的考虑因素,并且可以被认为是先前描述的技术的扩展。但是,外部存储器接口通常组合多种类型的访问。了解如何在访问多个外部存储器时避免冲突同样重要。例如,Atmel SAM9G上的外部存储器接口(如图5所示)支持组合的DDR,LPDDR和SDRAM控制器,静态存储器控制器和NAND闪存控制器。双从属接口连接到多级总线矩阵,以便在由不同总线主控器启动时传输可以重叠。请注意,静态存储器控制器和NAND控制器共享一个公共从端口。尝试重叠NAND和静态存储器访问可能效率低于重叠DDR2和NAND访问。同样需要注意在内部存储器块中分配数据以避免影响效率
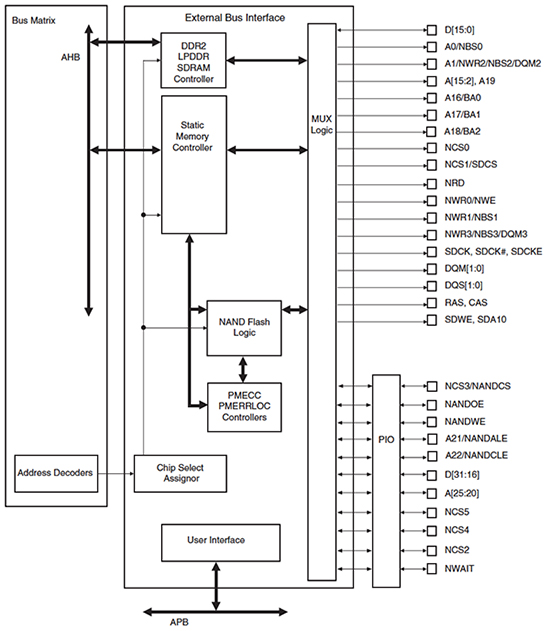
图5:Atmel SAM9G MCU上的外部存储器接口(由Atmel提供)。许多存储器接口子系统还提供缓存或本地存储器缓冲区以减少访问延迟。一些高级DDR控制器还可以自动优先考虑访问并组合操作,以利用DDR内存架构的块性质。如果外部存储器流量是算法的重要组成部分,则必须检查MCU上包含的存储器控制器功能的详细信息,以便更好地估计您可以预期的传输效率类型。
-
处理器
+关注
关注
68文章
20339浏览量
255220 -
mcu
+关注
关注
147文章
19160浏览量
404471 -
存储器
+关注
关注
39文章
7758浏览量
172237
发布评论请先 登录
怎样使移动电话存储子系统的功耗降至最低
KeyStone存储器架构
8个超低功耗 MCU 的设计指导原则
采用低功耗28nm FPGA降低系统总成本
基于FRAM的MCU在低功耗的应用
超低功耗的嵌入式应用的实现:降低系统中电池功耗
超低功耗MCU如何降低功耗
可提高性能并降低功耗的UltraScale架构
低功耗蓝牙芯片的应用可显著降低功耗和成本
电磁突破可以降低功耗,提高数字存储器的速度
华大电子MCU-CIU32F011x3、CIU32F031x5系统及存储器架构



评论