 使用智能外设提高整体处理效率和节省功耗
使用智能外设提高整体处理效率和节省功耗
现代MCU增加了一系列新功能,如果使用得当,可以显着提高应用效率。特别地,使用可独立于CPU操作的智能外围设备,外围设备允许CPU并行地执行其他任务或者使其进入低功率睡眠模式。使用这些技术中的任何一种都可以提高整体处理效率和节省功耗。
基于MCU的设计中遇到的首批智能外设之一是直接存储器访问(DMA)控制器。这种专用硬件模块可以在存储器和/或外设之间传输数据,而不需要CPU参与每次传输。高级DMA控制器(例如STMicroelectronics STM32F4系列中包含的控制器)可以通过使用灵活的数据流分配和传输管理功能进一步卸载CPU。让我们更详细地看一下这些功能,看看它们如何用于提高处理效率。图1显示了一个框图,表示STM32F4器件上两个DMA控制器之一可用的各种数据路径。如图左侧所示,DMA请求来自8个不同的通道(分配给各种启用DMA的外设),并被路由到仲裁器上的8个不同的请求输入,建立优先级(编号较低的输入具有更高的优先级) )。然后激活最高优先级的传输,图右侧的AHB Masters执行所需的数据传输。内存和外设接口的独立主机进一步提高了外设到内存传输的效率,这可能是基于MCU的设计中最常用的DMA。
为每个流分配单独的FIFO,如图所示在图1的中间,允许针对每个外设接口的特性调整FIFO特性。例如,FIFO的阈值电平(请求传输的深度)可以单独设置为FIFO大小的1/4,½或3/4。这允许低速通道在传输之前等待FIFO几乎满,以最小化开销。更快的通道可以更快地启动传输,可能是½大小以避免FIFO溢出。
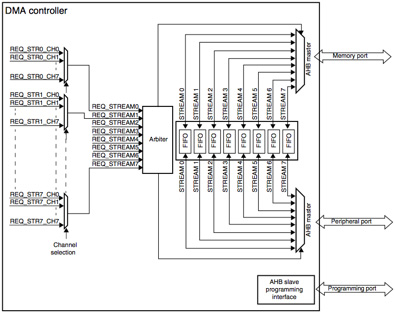
图1:STM32F4系列DMA控制器(由STMicroelectronics提供)。
其他高级DMA寻找的能力与数据传输的管理有关。某些外设提供传输结束指示器,高级DMA控制器可以检测并使用它来独立于CPU终止传输。 DMA控制器完成双缓冲和循环缓冲管理,通过在传输过程中自动重新配置源和目标来消除CPU开销。如果CPU需要管理这些类型的低级任务,您可以看到处理效率会受到影响映射,优先级排序和管理数据传输活动的这种灵活性大大降低了CPU开销,一旦初始化了智能DMA控制器,就可以管理传输并有效地分配带宽而无需进一步的CPU干预。这种独立操作是任何智能外设的关键特性,设计人员在选择目标器件时应该寻找,我们将在其他智能外设中找到我们将在下面讨论的内容。
在串行外设中寻找智能《 br》一旦理解了DMA的使用,就可以自然地寻找为串行外围设备提供额外智能的方法,以充分利用DMA功能并进一步从低级功能中卸载CPU。集成到高速外设(如以太网和USB)中的专用FIFO缓冲器的使用提供了额外的CPU自治水平,因为可以通过单个突发中的传输来分阶段和处理传输,以提高效率。智能外设可以根据带宽要求设置CPU可以中断的各种级别。请注意,这些独立的FIFO可以与专用于DMA控制器的任何FIFO配合使用,如图1所示的STM32F4器件。外设FIFO可以提供第一级缓冲,DMA可以根据哪些外设同时处于活动状态来提供第二级。当FIFO仅在外设上可用时,这允许额外级别的管理和控制(即智能)。
如前所述,许多外设包括可用于请求CPU干预的灵活中断,如果中断具体到足以告诉CPU究竟需要什么服务,响应时间可以大大减少。如果中断不是智能的,则CPU需要搜索各种标志或状态位以确定要采取的操作。在时序预算和延迟要求最具侵略性的情况下,使用具有智能中断的外设可以产生很大的不同。
有些MCU采用这种方法更进一步,完全消除了某些操作的中断。 Energy Micro(现为Silicon Labs的一部分)EFM32GZ系列包括一个特殊的外设反射系统(PRS),可通过允许外设之间的快速和自主通信来实现许多常见的中断功能。由于来自一个外围设备的事件可以用作输入信号或由其他外围设备触发,因此可以消除对CPU的中断以实现简单的内务处理功能的需要。通过四个可配置互连通道之一选择和路由这些信号。生成外设(产生事件的外设)的输出被路由到消费者(由事件触发的外设)并针对电平或上升/下降沿灵敏度进行调整。
PRS的示例使用如图2所示。定时器可以用于触发ADC转换的开始,ADC转换完成信号可用于触发DMA传输。反过来,DMA完成信号可用于重置定时器以重新开始序列。无需CPU干预,无需生成中断。请注意,在进行了一些测量(可能是1,000次)之后,可以将额外的计数器添加到用于唤醒CPU的PRS中。然后,CPU可以同时处理所有1,000个样本,以进一步提高处理能力和功效。
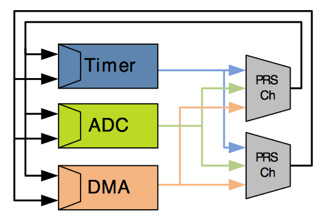
图2:Silicon Labs EFM32GZ系列外设反射系统示例(由Silicon Labs提供)。 》多核MCU创建智能外设
高性能MCU的终极卸载引擎是一个协处理器,可以完全独立地管理外设I/O功能。最近采用NXP LPC4370FET100E的多核MCU,允许设计人员创建一个专用于外设控制的完全独立的通道控制器。实际上,恩智浦LPC4370有三个CPU内核:主ARM Cortex-M4 CPU,面向协处理器的ARM Cortex-M0 CPU,以及面向外设控制的ARM®Cortex™-M0 CPU。图3显示了面向外设的CPU(位于框图左上方)是外设子系统的一部分,该子系统包括AHB子系统总线矩阵,SPI端口,子系统GPIO和本地SRAM存储器。核心到核心的桥通过主AHB总线矩阵将子系统连接到设备的其余部分。外设子系统具有独立管理外设所需的所有硬件,在某些情况下可以是唯一的CPU活动,其他CPU处于低功耗状态以提高电源效率。
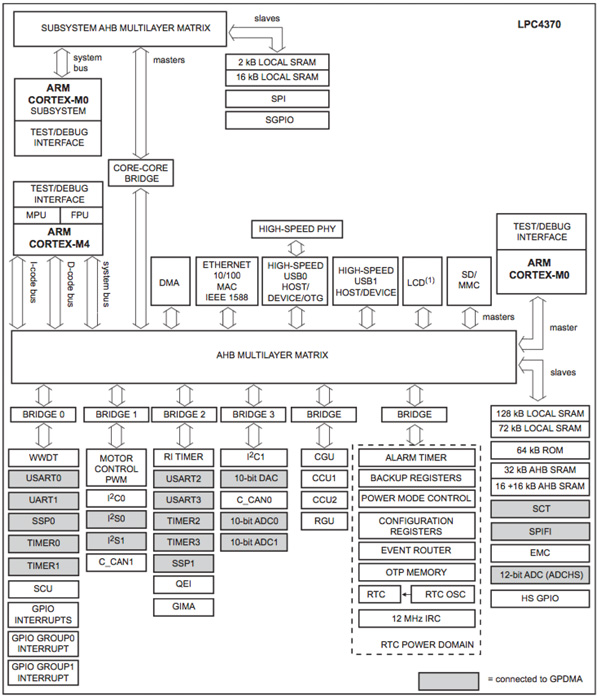
图3:恩智浦LPC4370系列框图(由恩智浦提供)。但是,智能外设控制无需停在那里。实际上,第二个ARM Cortex-M0 CPU也可用于外设控制,可能用于模拟DAC和ADC子系统,也可用作智能电机控制外设。智能外设控制的这种分层使得仅启用所需的子系统成为可能;高性能数据处理功能中的主CPU,通过SPI端口进行命令处理时的低速智能外设接口(设备的其余部分处于掉电模式),或高速智能外设控制器期间电机控制或模拟操作。当多个内核可用于创建独立的智能子系统时,独立操作的可能性很大,并且可以更轻松地针对应用的特定需求进行定制。
不要忽视智能模拟
可能很容易专注于数字外设,忽略了模拟外设中可用的新功能,这些功能也为他们提供了更高的智能水平。瑞萨RL78系列等高级MCU中包含的模数转换器(ADC)能够独立运行,类似于串行端口等数字外设所描述的操作。例如,智能ADC可以配置为在由硬件定时器触发时进行定期测量,完全独立于CPU。捕获的值可以使用DMA功能按顺序存储到存储器中,并且在需要进行足够的测量以进行处理之前,CPU不需要参与。在数字信号处理(DSP)应用中,在需要处理之前可能需要进行一千次测量。在此期间,CPU可以执行其他功能,或者可以进入低功耗睡眠模式和定时器中断,用于在获取足够的样本时唤醒CPU。很容易看出,在需要使用CPU捕获和存储每个ADC测量值的实现中,处理和功率效率都得到了很大改善。
您可能认为这种级别的智能自主操作就足够了,但是正如他们在低预算的深夜电视广告中所说的那样,“等等,还有更多!”瑞萨RL78 ADC还具有窗口功能,可用于进一步改善自主操作。该功能允许编程人员为捕获的ADC值定义低电平和高电平阈值(窗口),如图3所示。如果捕获的值超出定义的阈值,则可以生成中断(如果ADRCK控制位设置为“1”。请注意,如果需要反向窗口,如果值落在窗口内,则可以生成中断。如果模拟值开始在可接受范围之外漂移,则此功能允许快速响应。如果没有这种智能水平,则需要捕获完整数据集(可能是一千次测量)的结束,然后大量的CPU周期扫描整个数据集以确定该值是否已开始超出可接受的范围。如果每10μs进行一次测量并且每次进行1,000次测量,则对阈值违规的最坏情况响应将超过10 ms(不包括CPU扫描整个数据集的时间,整个时间刻录功率) 。显然,像瑞萨RL78那样使用窗口函数可以节省大量的处理周期时间和功耗。
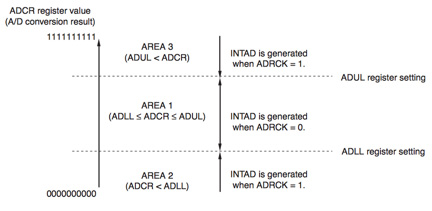
图4:瑞萨RL78 ADC窗口函数的范围设置(由瑞萨提供。)智能使用低功耗模式
重要的是要注意,将非活动CPU置于低功耗模式的能力是进一步提高功效的关键技术。 TechZone最近的一篇文章“使用MCU电源管理选项来优化系统效率”提供了一个很好的资源,可以更好地理解各种可用的低功耗模式,因此我们可以在此处放弃详细讨论。我们关于低功耗模式的关键点是,智能外设由于其自主运行能力,提供了许多机会将CPU置于低功耗状态,“节省”它们用于最擅长的复杂数据处理任务。当低功耗模式与智能外设结合使用时,功耗和处理效率的提高可能会非常显着。总而言之,MCU已开发出多种自主功能,可用于卸载低级处理任务以进行管理外围设备及其相关的数据传输功能。新的多核MCU提供了更多创建和使用智能外设的机会,可以满足应用的特定需求。当正确集成到基于MCU的应用程序中时,智能外设子系统的使用可以显着提高处理和功效。不要忽视设计中的这些机会。
-
mcu
+关注
关注
146文章
17135浏览量
351031 -
控制器
+关注
关注
112文章
16339浏览量
177859 -
存储器
+关注
关注
38文章
7484浏览量
163776 -
cpu
+关注
关注
68文章
10855浏览量
211610
发布评论请先 登录
相关推荐
怎样提高三坐标测量机的测量效率
DMD芯片的功耗与效率优化方法
智慧园区智能照明控制系统-节省照明用电,提高照明管理效率
如何优化智能系统的运行效率
nRF54L 系列SOC芯片NRF54L15 超低功耗蓝牙5.4 SOC
AH7691D低功耗、高效率、低纹波52V转12V 1.5A安防POE电源芯片
软国际携手福建某铝企业共建智能仓储整体解决方案
如何提高工业交换机的电源功耗
esp32的整体平均功耗能到多少?
东莞mes系统:提高生产效率的利器
提高效率的DC电源模块设计技巧

雾天行车诱导系统中低功耗车辆检测雷达的关键机制






 工商网监
工商网监
评论