 北大开源了一个中文分词工具包,名为——PKUSeg
北大开源了一个中文分词工具包,名为——PKUSeg
分词技术是一种比较基础的模块,就英文而言,词与词之间通常由空格分开,因此英文分词则要简单的多,但中文和英文的词是有区别的,再加上中国文化的博大精深,分词的时候要考虑的情况比英文分词要复杂的多,如果处理不好就会直接影响到后续词性标注、句法分析等的准确性,
目前,我们最常用的分词工具大概有四种哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba。
不过最近,北大开源了一个中文分词工具包,名为 ——PKUSeg,基于Python。据介绍其准确率秒杀THULAC和结巴分词等工具。
一经开源,pkuseg已经在GitHub上获得1738个Star,244个Fork(GitHub地址:https://github.com/lancopku/PKUSeg-python)
pkuseg具有如下几个特点:
多领域分词:不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。 我们目前支持了新闻领域,网络文本领域和混合领域的分词预训练模型,同时也拟在近期推出更多的细领域预训练模型,比如医药、旅游、专利、小说等等。
更高的分词准确率:相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
支持用户自训练模型:支持用户使用全新的标注数据进行训练。
各类分词工具包的性能对比
前面有提到说pkuseg的准确率远超其他分词工具包,现在就是用数据说话的时候了,下面就是在 Linux 环境下,各工具在新闻数据 (MSRA) 和混合型文本 (CTB8) 数据上的准确率测试情况
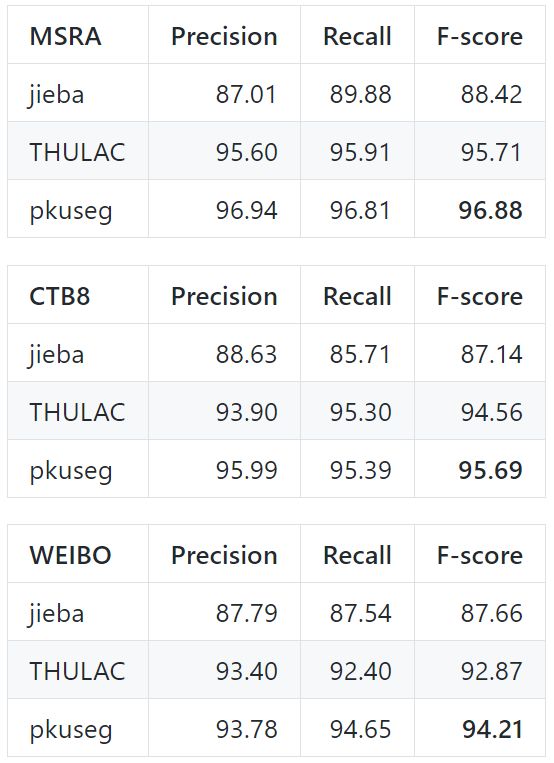
测试使用的是第二届国际汉语分词评测比赛提供的分词评价脚本,从上图看出结巴分词准确率最低,
跨领域测试结果
以下是在其它领域进行测试,以模拟模型在“黑盒数据”上的分词效果。
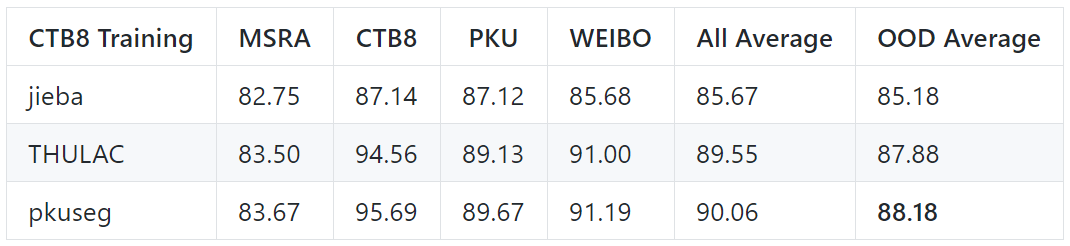
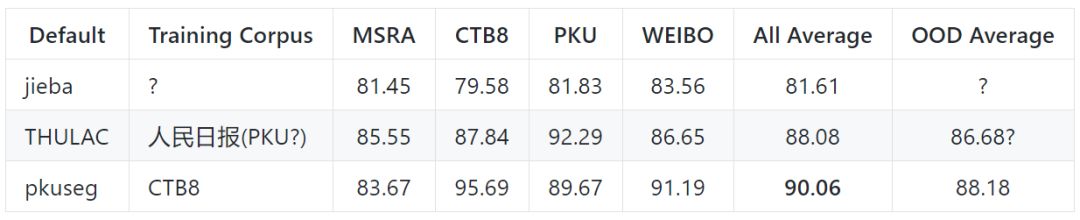
默认模型在不同领域的测试效果
以下是各个工具包的默认模型在不同领域的测试效果
使用方式
代码示例1:使用默认模型及默认词典分词
importpkusegseg=pkuseg.pkuseg()#以默认配置加载模型text=seg.cut('我爱北京***')#进行分词print(text)
代码示例2:设置用户自定义词典
importpkuseglexicon=['北京大学','北京***']#希望分词时用户词典中的词固定不分开seg=pkuseg.pkuseg(user_dict=lexicon)#加载模型,给定用户词典text=seg.cut('我爱北京***')#进行分词print(text)
代码示例3:使用其它模型
importpkusegseg=pkuseg.pkuseg(model_name='./ctb8')#假设用户已经下载好了ctb8的模型#并放在了'./ctb8'目录下,通过设置model_name加载该模型text=seg.cut('我爱北京***')#进行分词print(text)
代码示例4:对文件分词
importpkusegpkuseg.test('input.txt','output.txt',nthread=20)#对input.txt的文件分词输出到output.txt中,#使用默认模型和词典,开20个进程
代码示例5:训练新模型
importpkuseg#训练文件为'msr_training.utf8'#测试文件为'msr_test_gold.utf8'#模型存到'./models'目录下,开20个进程训练模型pkuseg.train('msr_training.utf8','msr_test_gold.utf8','./models',nthread=20)
此外,pkuseg提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型:
MSRA:在MSRA(新闻语料)上训练的模型。
下载地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8:在CTB8(新闻文本及网络文本的混合型语料)上训练的模型。随pip包附带的是此模型。
下载地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO:在微博(网络文本语料)上训练的模型。
下载地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
最后附上前面提到的另外四大分词工具的GitHub地址:
1、LTP:https://github.com/HIT-SCIR/ltp
2、NLPIR:https://github.com/NLPIR-team/NLPIR
3、THULAC:https://github.com/thunlp/THULAC
4、jieba:https://github.com/yanyiwu/cppjieba
-
Linux
+关注
关注
87文章
11373浏览量
211300 -
开源
+关注
关注
3文章
3471浏览量
42937 -
python
+关注
关注
56文章
4813浏览量
85304
原文标题:准确率秒杀结巴分词,北大开源全新中文分词工具包PKUSeg
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
在Google Colab笔记本电脑上导入OpenVINO™工具包2021中的 IEPlugin类出现报错,怎么解决?
构建开源OpenVINO™工具包后,使用MYRIAD插件成功运行演示时报错怎么解决?
安装OpenVINO™工具包稳定扩散后报错,怎么解决?
云计算开发工具包的功能
TDC1000-TDC7200 GUI调试工具求助
RT-Thread荣登2024开源创新榜单,跻身中国十大开源社区

TSP工具包软件的应用说明
最新Simplicity SDK软件开发工具包发布
基于EasyGo Vs工具包和Nl veristand软件进行的永磁同步电机实时仿真
FPGA仿真工具包软件EasyGo Vs Addon介绍


使用freeRTOS开发工具包时,在哪里可以找到freeRTOS的版本?
新加坡推出Project Moonshot -- 这是一款生成式人工智能测试工具包,用于应对LLM安全和安保挑战






 工商网监
工商网监
评论