 向来提倡open的谷歌,现在也玩儿“自闭”?
向来提倡open的谷歌,现在也玩儿“自闭”?
谷歌AI又成了话题。Reddit网友找到了谷歌AI一个名叫Conceptual Captions的数据集,发现该数据集并不完善,于是乎联系谷歌AI相关人员,却惨遭三连拒。
向来提倡open的谷歌,现在也玩儿“自闭”?
昨天谷歌AI大佬Jeff Dean刚刚发表长文总结了2018年的主要研究成果,其中包括“开源软件和数据集”:
发布开源软件和创建新的公共数据集是我们为研究和软件工程社区做出贡献的两种主要方式。
然而细心的Reddit网友却发现,谷歌AI并没有那么“开源”,反而还拒绝共享数据:
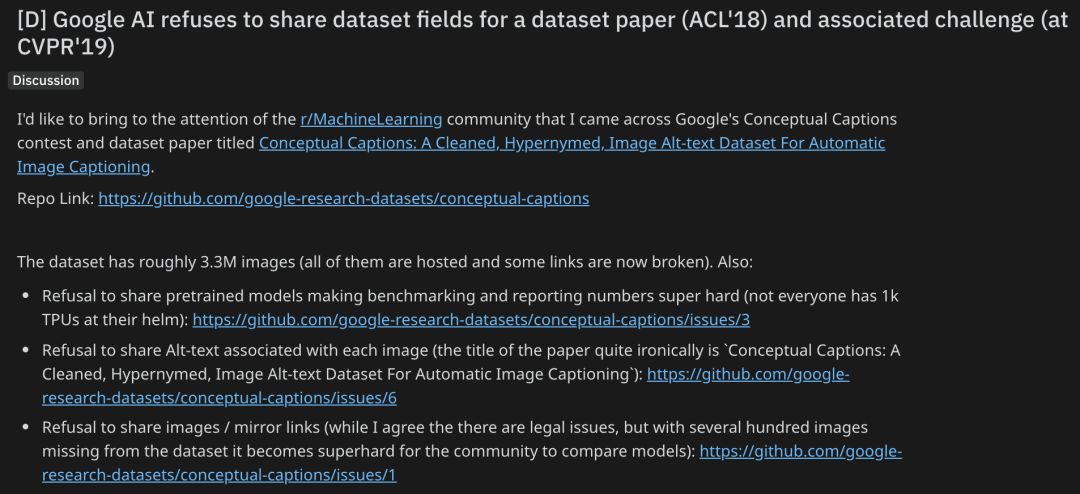
事情是这样的。
这位网友发现了谷歌AI一个叫Conceptual Captions数据集相关的比赛,以及描述这个数据集的论文(ACL 2018):
论文地址:
http://aclweb.org/anthology/P18-1238
在GitHub中对此数据集的描述为:一种包含330万张图像的大规模图像数据集,专门用于机器学习图像字幕系统的训练和评估。
GitHub地址:
https://github.com/google-research-datasets/conceptual-captions
然而,当这位网友跃跃欲试想要拿这个数据集操练一番时却发现了一些问题:这个数据集全部图像都是托管的,一些链接现在已经失效。
于是,这位网友开始试图联系谷歌AI相关人员。
结果,真可谓是大跌眼镜。
惨遭三连拒,热心研究者被泼冷水
第一拒:拒绝分享预训练模型
这就使得基准测试和论文里的结果数字变得非常难以复现。毕竟,不是每个人都有1k的TPU。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/3
问:哪里可以找到基于Conceptual Captions数据集的预训练模型(RNN-,Transformer-based)?
答:预训练模型没有发布。
第二拒:拒绝分享与每个图像关联的Alt-text
讽刺的是,这篇论文标题是“Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning”。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/6
问:是否会发布与每个图像关联的Alt-text?用于生成字幕的代码也会公开吗?
答:没有发布Alt-text或代码的计划。
第三拒:拒绝分享图像/镜像链接
这位网友表示:虽然我同意存在法律问题,但数据集中缺少数百张图像,其他研究人员要想比较模型变得超级困难。
地址:https://github.com/google-research-datasets/conceptual-captions/issues/1
问:您能提供从tsv文件通过url下载图像的示例代码吗?Python的urllib无法下载某些url (IOError: [Errno socket error] [Errno 110] Connection timed out)。但是我可以在浏览器中看到这些图像。
答:谢谢你的关注!不幸的是,由于版权/法律问题,我们无法提供通过url从tsv文件下载图像的代码。
谷歌AI“自闭”拒共享,引网友热议
这位热心网友在惨遭三连拒后表示对这样的事情非常痛心:
一篇数据集论文对于复现结果非常重要,如果存在阻碍数据集共享的法律问题,那么发表私人数据集论文就好了(有些领域不公开Alt-text),但基于一个不公开预训练模型、不完全共享的数据集举办挑战赛,我认为这就不太酷了。
而后,其它网友们也炸锅了。
热心网友1:_michaelx99
Deepmind的一些论文也是这样,仅仅根据他们发表的论文,完全不可能把结果复现出来。我花了一段时间才意识到Arxiv或他们网站上的一篇“论文”并不是真正的出版物,因此它的主要目标是展示公司已经开发了某种能力。这与其他人能够证实或否认他们在科学过程中所做的事情关系不大。我并不是说大公司在网上发布的所有论文都是这样,但正如你刚刚发现的,其中一些论文确实如此。
热心网友2:duckbill_principate
据我所知,四分之一的ML论文本质上是美化的广告。
热心网友3:GoAwayStupidAI
可重复性是科学的标志。没有这些数据,这个结果是不可复制的,所以科学会很糟糕。
热心网友4:Silver5005
这是ML论文最大的问题。我一直在尝试实现一个股票预测的LSTM,你可以找到数百篇论文都在做同样的概念。但它们都没有数据集,也不会谈论它们如何清理或标准化它们的数据。
热心网友5:duckbill_principate
人们不分享他们的模型、代码或数据集,这本身并不困扰我。令我困扰的是,这种情况发生了,而这些论文仍然被接受。这是同行评审过程的绝对失败,它的责任完全落在审查员(和我们)的肩上。这些论文是在信任的基础上被接受的,在某些情况下甚至是权威(我们都知道,尽管存在着双盲的本质,但不难推断出某些论文可能来自哪个群体),这是绝对不可接受的。
这更接近于广告而不是科学。
热心网友6:epic
我不知道为什么有这么多谷歌的辩护者。这对科学和机器学习都不利。是的,我们都明白为什么,但这仍然很糟糕。特别是像这样的论文,如果不能从数据中分离出来的话,再现性是非常困难的。有机会的组织和个人应该以一个好榜样来领导这个领域,而不是反过来。
对此,你怎么看?
-
谷歌
+关注
关注
27文章
6164浏览量
105323 -
AI
+关注
关注
87文章
30763浏览量
268910 -
数据集
+关注
关注
4文章
1208浏览量
24691
原文标题:谷歌AI遭猛怼!发布数据集论文和挑战赛,却拒绝公开数据集
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TAS5411-Q1 open load不管接不接喇叭都是open,重启也不变,为什么?
单北斗定位智能终端提倡应用的重要性

苹果确认未来也将与谷歌Gemini合作
两小时“吼出”121次AI,谷歌背后埋伏着Open AI的幽灵

中国电信和GSMA成立全球首个Open Gateway联合开放实验室
opc ua open62541.c和open62541.h如何移植到stm32中?
Open RAN的未来及其对AT&T的意义
谷歌模型合成软件有哪些
谷歌模型怎么用手机打开文件






 工商网监
工商网监
评论