 详细介绍三个领域中来自微软亚洲研究院的那些硬核论文
详细介绍三个领域中来自微软亚洲研究院的那些硬核论文
AAAI即将举行,本文带来微软亚洲研究院入选的27篇论文解读,包括机器学习、自然语言处理(NLP)、计算机视觉和图形学等多个领域。
人工智能领域的国际顶级会议 AAAI 2019 将于 1 月 27 日至 2 月 1 日在美国夏威夷举行。
根据已经公布的论文录取结果,今年的大会录取率创历史新低,投稿数量高达 7745 篇,录取的数量仅有 16% 左右。
在被录取的论文中,来自微软亚洲研究院的有 27 篇之多,包括了机器学习、自然语言处理(NLP)、计算机视觉和图形学等多个领域。本文将详细介绍这三个领域中来自微软亚洲研究院的那些硬核论文。
机器学习
非自回归机器翻译模型的两种优化新方式
2018 年,非自回归(Non-Autoregressive)机器翻译模型引起了众多研究人员的兴趣。非自回归模型打破了翻译过程顺序性,将原来自回归机器翻译的逐词顺序生成转变为一次性产生所有目标端单词,极大地提升了机器翻译速度。然而,随着顺序依赖关系的打破,非自回归模型的翻译准确率却远远不及自回归机器翻译模型;同时,漏翻译和重复翻译也将翻译质量大打折扣。微软亚洲研究院分别通过以下两篇论文提出了针对上述两个问题的解决方法。
代表论文:Non-Autoregressive Neural Machine Translation with Enhanced Decoder Input
论文链接:https://arxiv.org/abs/1812.09664
在该论文中,研究员提出了两种方法来提升解码器的输入质量,减少翻译精度的损失。如下图所示:第一种方法(Phrase-Table Lookup)直接利用词表将源语言查表翻译成目标语言并输入到解码器,第二种方法(Embedding Mapping)通过词级别的对抗学习以及句子级别的对齐信息,将源语言的词向量对齐到目标语言的词向量,作为解码器的输入。
通过在 WMT14 En-De/De-En、WMT16 En-Ro、IWSLT14 De-En 一共 4 个翻译语言上的实验,相比基线模型(NART),这种方法达到了 3~5 个 BLEU 分的提升,相比先前最好的工作(IR-NAT)有 1~5 个 BLEU 分的提升。
该模型翻译精度更加接近 AT 模型,在 WMT16 En-Ro 数据集上,相比 AT 模型(Transformer)仅有 1 个 BLEU 分的差距。在翻译速度方面,相比 AT 模型(Transformer)最高有 25 倍的翻译速度提升;相比 NAT 模型(LT、NART、IR-NAT)也有速度上的提升。
同时这两种方法各有优势,Phrase-Table Lookup 在数据质量比较好的 WMT14 De-En 以及 IWSLT De-En 数据集上优势明显,因为能基于训练集得到高质量的词典,而在 WMT14 En-De 以及 WMT16 En-Ro 上,得到的词典质量较差,因此 Embedding Mapping 更能显现出优势。
代表论文:Non-Autoregressive Machine Translation with Auxiliary Regularization
论文链接:https://taoqin.github.io/papers/nat.reg.AAAI2019.pdf
对于非自回归模型的重复翻译和漏翻译的问题,该论文提出了基于辅助约束(Auxiliary Regularization)的非自回归翻译模型,如下图。
重复翻译的产生代表解码器端相邻位置的隐层表示(Hidden Representation)有着极大的相似性,从而解码产生同样的翻译单词。为此,研究员提出了相似性约束(Similarity Regularization)来限制两个相邻位置的隐层表示向量之间的关系:
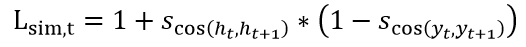
其中 s_cos 代表两个向量之间的余弦距离。H_t 代表解码器第 t 个位置的隐层状态向量,y_t 代表第 t 个位置的目标单词的单词嵌入(embedding)向量。L_sim 的意义在于,如果相邻两个位置(t 和 t+1)的目标单词语义接近(s_cos很大 ),那么 h_t 和 h_(t+1) 也应该很接近,反之亦然。
对于漏翻译,可以重建约束(Reconstruction Regularization),在非自回归模型的顶部添加一个反方向的自回归翻译模型,进而要求解码器的隐层向量在该反方向的模型中重建源端句子。通过这一约束,强制要求非自回归模型的翻译含有所有信息以克服漏翻译的问题。
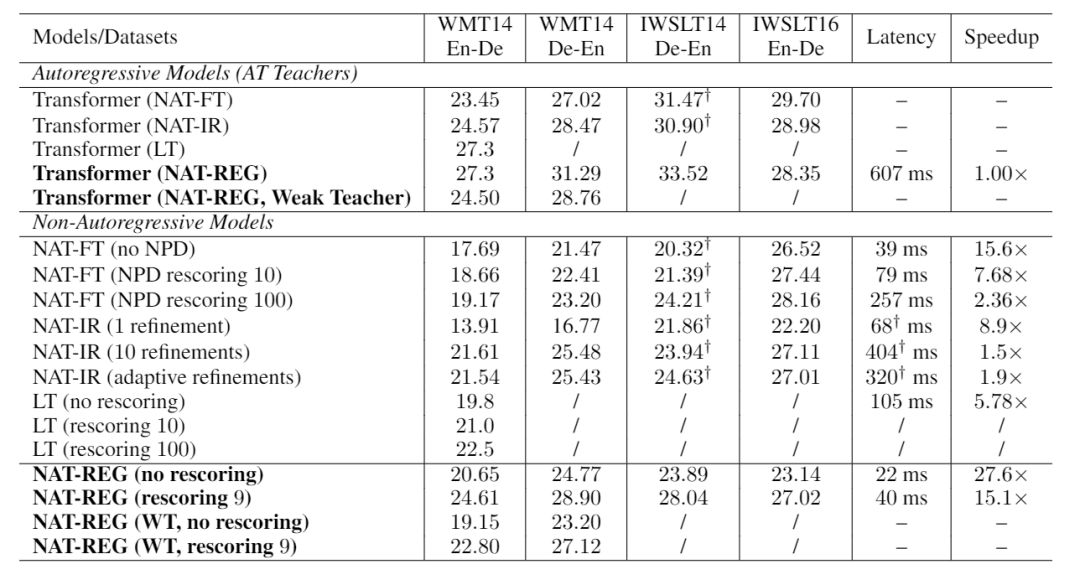
通过在多个数据集上与各个基线算法进行了性能的对比,包括对于翻译质量和翻译速度的衡量。NAT-REG 算法不仅具有良好的性能,在翻译速度(上图最后两列)也有了显著的提升。通过这两项约束项,非自回归机器翻译模型的重复翻译和漏翻译的现象得到了极大的缓解。
深度神经网络模型的泛化及对泛化误差的刻画
在机器学习领域,理解深度神经网络模型的泛化性质以及刻画其泛化误差是一个热点,论文 “Capacity Control of ReLU Neural Networks by Basis-path Norm” 论述了这一理论研究。
代表论文:Capacity Control of ReLU Neural Networks by Basis-path Norm
论文链接:https://arxiv.org/abs/1809.07122
ReLU 神经网络具有正伸缩不变性,即一个隐节点的所有入边乘以一个正常数 c, 同时所有出边除以一个正常数 c, ReLU 神经网络的输出值不变。因此,一个恰当的与神经网络泛化性质有关的度量,应该也具有正伸缩不变性。基于 ReLU 神经网络的路径的度量也满足该性质。
对于神经网络的路径(path),将 ReLU 神经网络看做一个有向无环图,一条路径 p 即为输入节点至输出节点的一条通路,路径的值 v(p) 被定义为其所经过的参数的乘积。那么 ReLU 神经网络的第 k 维输出可以表示为:
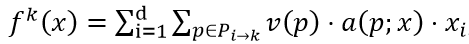 ,
,
其中 P_(i→k) 表示连接第 i 个输入节以及第 k 个输出节点的所有路径的集合;a(p;x) 取值为 1 或 0,分别代表该路径的值在经过多层激活函数作用后是否流入输出。
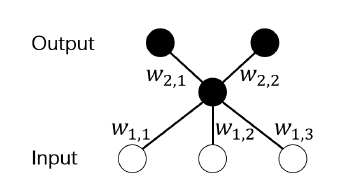
路径 p_(i,j) 的值等于 w_(1,i)⋅w_(2,j), 那么路径之间相互关联,例如 v(p_(2,2) )=(v(p_(1,2) )⋅v(p_(2,1) ))/v(p_(1,1) ) 。
Path-norm 被定义为所有路径值的 L2 - 范数,其被证明与 ReLU 神经网络的泛化能力紧密相关。然而,神经网络所有路径值是相关联的(如上图),这会使得当 Path-norm 作为约束加入优化算法中时,无法求解出闭式的更新法则。有工作通过研究路径值之间的关系,在所有路径值中找到了一组互不相关的路径,称为基路径,并且其余路径均可通过基路径的值进行计算。
这一论文提出了一个基于基路径的度量。首先,基路径可以分为两类,一类的值在表达非基路径时出现在分子,第二类的值在表达非基路径时出现在分母。于是,出现在分母的基路径值不能过大或过小。因此,限制前者的值靠近 0,后者的值靠近 1,受此启发,研究员提出了一个仅基于基路径的度量:BP-norm。
定义 1: (BP-norm) 对于任意的路径值向量
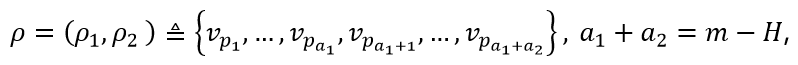
BP-norm 定义如下:
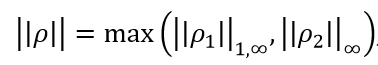
,
其中
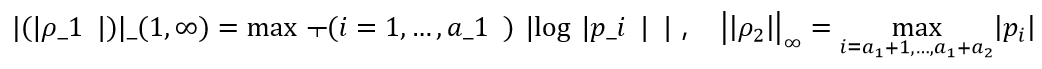
根据 BP-norm, 可得如下泛化误差的上界。
定理 1: 至少以概率 1-δ, 泛化误差 (测试误差 – 训练误差) of hypothesis space F can be upper bounded as
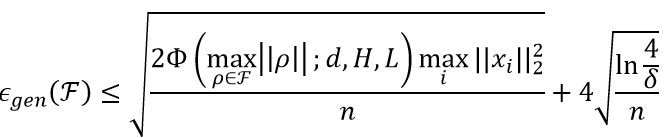
其中 Φ(u;d,H,L)=(e^2u+d⋅u^2) (1+H⋅u^2⋅e^2u)^(L-2) (4H)^L, d 表示输入维度, H 表示网络的宽度, L 表示网络的深度。
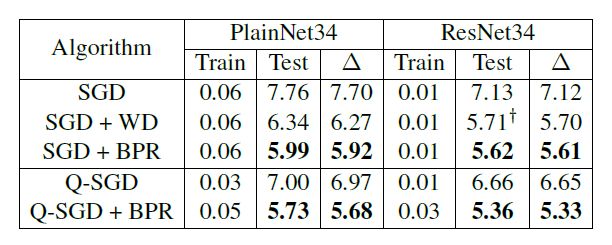
将 BP-norm 作为正则项加入损失函数,并用 SGD 和 G-SGD 来优化 BP 正则损失函数。下表展示了算法在图像分类任务上的训练误差、测试误差和泛化误差,其中Δ反映了泛化误差的大小。结果表明 BP 正则算法可以有效地降低模型复杂度,从而取得更小的泛化误差。
自然语言处理
AI 也可以自动发弹幕了
弹幕,已经成为人们看视频的一种习惯;不同用户之间的弹幕往往会形成上下文回复关系,更让弹幕成为一种新的社交模式。基于这一现象,微软亚洲研究院设计了一款名为 LiveBot 的自动弹幕生成系统。在这一系统中需要克服两个难点:一是要充分理解视频内容,根据其他用户的评论弹幕生成适当的内容;二是要在合适的时间点显示在对应的视频帧之上。
代表论文:LiveBot: Generating Live Video Comments Based on Visual and Textual Contexts
论文链接:http://export.arxiv.org/pdf/1809.04938
该论文论述了两种深度神经网络模型,基于视频和文本的上下文信息来生成弹幕,并构建了一个包含 2,361 个视频和 895,929 条弹幕的大规模训练数据集来验证模型的有效性。

实验结果表明,LiveBot 能够准确地学习到真实用户在观看视频时进行弹幕评论的行为特点,有效地进行了视频内容的理解和用户评论的交互,同时在客观评价指标上也取得优异的成绩。
无监督机器翻译的最新性能提升
最近一年,无监督机器翻译逐渐成为机器翻译界的一个研究热点。在无监督场景下,神经机器翻译模型主要通过联合训练(joint training)或交替回译(iterative back-translation)进行逐步迭代。但是由于缺乏有效的监督信号,回译得到的伪训练数据中会包含大量的噪音,这些噪音在迭代的过程中,会被神经机器翻译模型强大的模式匹配能力放大,从而损害模型最终的翻译性能。
代表论文:Unsupervised Neural Machine Translation with SMT as Posterior Regularization
论文链接:http://export.arxiv.org/pdf/1901.04112
该论文采用了后验正则(Posterior Regularization)的方式将 SMT(统计机器翻译)引入到无监督 NMT 的训练过程中,并通过 EM 过程交替优化 SMT 和 NMT 模型,使得无监督 NMT 迭代过程中的噪音能够被有效去除,同时 NMT 模型也弥补了 SMT 模型在句子流畅性方面的不足。
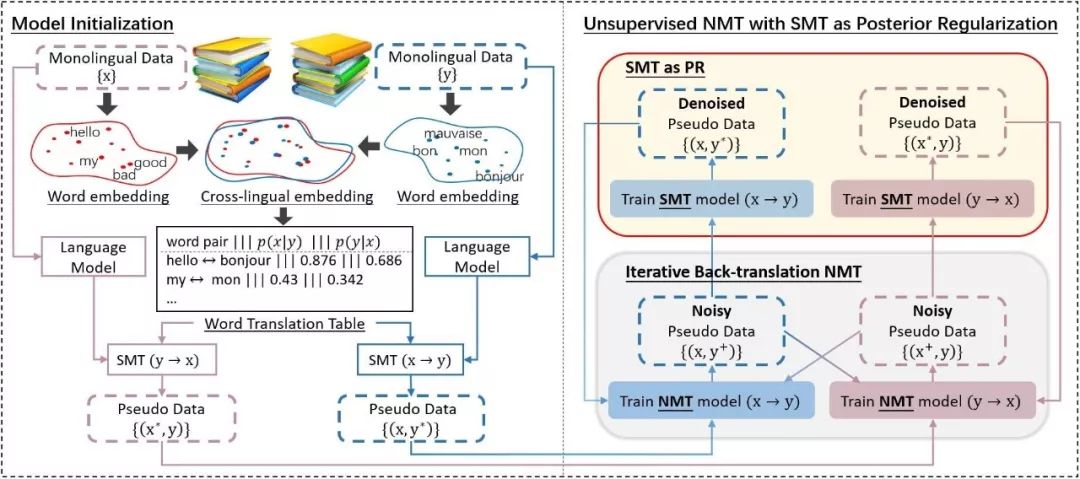
该方法的整体结构大致分为两部分,如上图所示。左边是模型初始化,通过单语数据训练出两种语言(如英语和法语)的词向量(word embedding),之后通过无监督的训练方法得到 cross-lingual embedding,并通过计算其余弦相似度得到初始的词到词的翻译概率表(word translation table)。这个翻译概率表连同由单语训练得到的语言模型(language model)作为初始的 SMT 模型的特性,从而完成了模型初始化。
上图右边是方法的主体部分,初始的 SMT 模型翻译一批单语数据,构成的伪数据作为初始 NMT 模型的训练数据。在训练得到初始的 NMT 模型后,将继续进行交替回译(右下,iterative back-translation NMT),并用收敛的 NMT 模型翻译出一批新的伪数据。此时产生的伪数据含有大量的噪音,可以通过这批伪数据训练新的 SMT 模型(右上,SMT as PR)。SMT 模型通过构造质量更高的基于片段的翻译概率表(phrase translation table),将伪数据中的噪音过滤掉,并通过翻译新的一批单语数据,得到互译性更好的一批伪数据。这一批伪数据便可以用于调整(fine-tune)之前的 NMT 模型,之后 NMT 模型再次进行交替回译。我们将训练 NMT 和 SMT 的过程集成在一个 EM 训练框架中,两个过程进行交互迭代直到最终收敛。
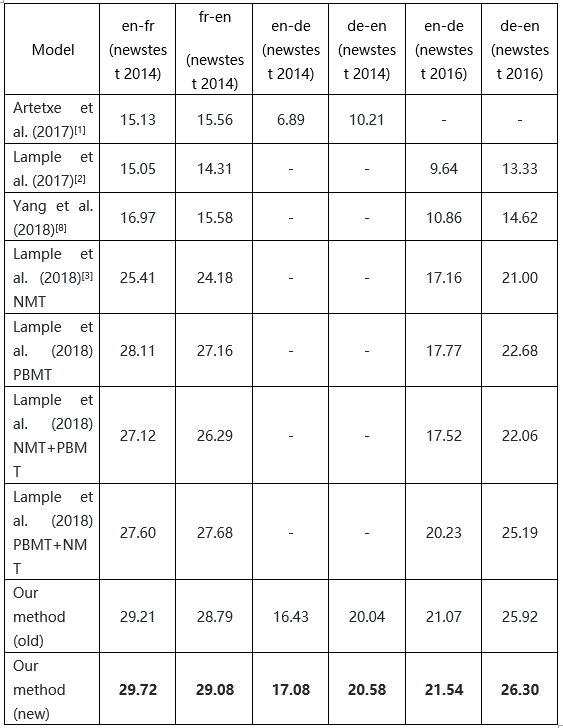
在英法 (en-fr) 和英德(en-de)语言对上进行的实验中,这一方法明显优于以前的方法,显著提高了无监督机器翻译的性能。
新型 TTS:结合了 Tacotron2 和 Transformer 的优点
人机交互中有项重要的任务,即文本合成语音(Text to speech,TTS),以达到合成清晰自然且接近真人录音的音频。
在过去的几十年里,基于拼接的模型(concatenative model)和基于参数的模型(parametric model)是 TTS 领域的两大主流;然而,两者都有着非常复杂的流水线,而且挑选有效的声学特征通常是非常耗时且与语言密切相关的。除此之外,这两种方法合成的音频不流畅,而且在韵律和发音上与真人录音都有较大的差距。
随着神经网络的兴起,一些端到端(end to end)的 TTS 模型逐渐出现,如 Tacotron 和 Tacotron2,使得合成的音频质量有了非常大的进步,甚至在某些特定的数据集上与真人录音不相上下。这种端到端的 TTS 模型主要有两部分:编码器和解码器。编码器负责将文本映射到语义空间(semantic space)中,生成一个隐状态序列;接着由解码器(通常是一个基于 RNN 的神经网络)配合注意力机制(attention mechanism)将这个隐状态序列解码成频谱。
然而,在 RNN 中,每一个隐状态的生成都要基于之前所有的隐状态以及当前时刻的输入;因此模型只能串行地进行计算,限制了网络的并行计算能力,从而降低了运算效率。并且 RNN 难以对距离较远的两个输入建立直接的依赖关系。而最近流行的自关注网络(Transformer)在训练中可以实现并行计算,而且有能力在输入序列的任意两个 token 之间建立起直接的依赖。
代表论文:Neural Speech Synthesis with Transformer Network
论文链接:https://arxiv.org/abs/1809.08895
该论文中结合了 Tacotron2 和 Transformer 的优点,提出了新的 TTS 模型:通过使用多头注意力 (multi-head attention) 机制代替了原本 Tacotron2 中的 RNN 以及编码器和解码器之间的 attention。这样,一方面通过自注意力(self attention) 机制,网络可以并行计算,从而使训练效率达到了原来的 4 倍;同时,任意两个输入之间可以建立起直接的长距离依赖。另一方面,多头的注意力机制可以从多个角度对输入信息进行整合。
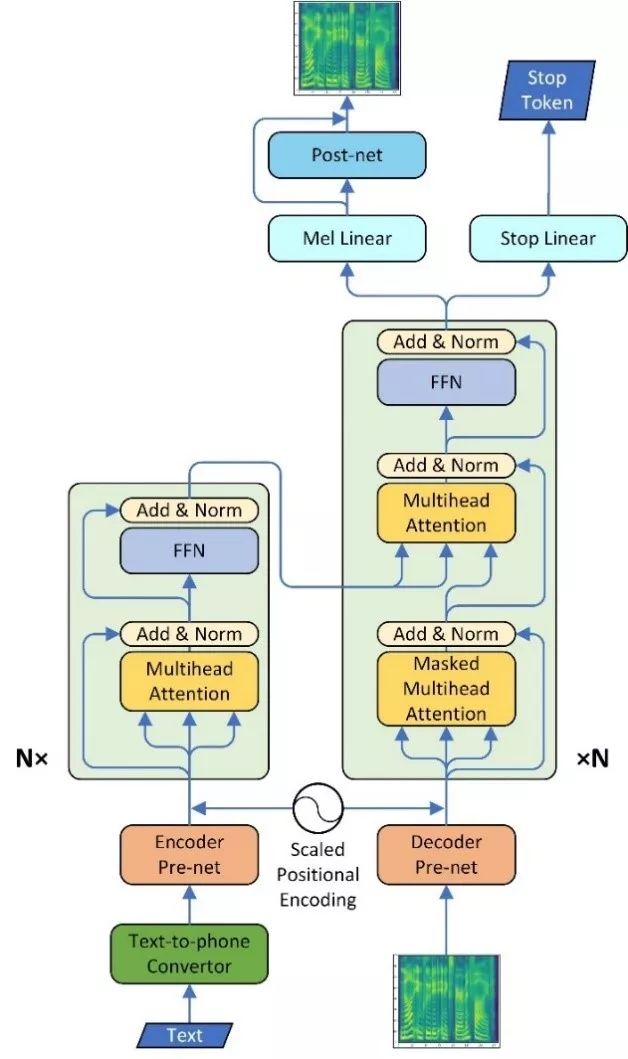
如上图,在 Tacotron2 的基础上,使用 Transformer 的 encoder 和 decoder 分别代替原有的双向 RNN 编码器和双层 RNN 解码器;另一方面原始的注意力机制被多头注意力机制取代从而能更好地对输入信息进行特征提取;除此之外我们还对其它的网络结构,如 positional encoding 进行了调整。在该模型中,由于有自注意力机制的存在,可以更好地建立长距离依赖,从而能对包括韵律在内的音频特征进行更好的建模。
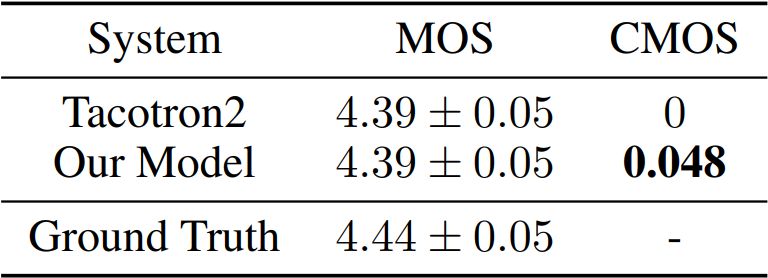
在 MOS 测试(满分 5 分)中, Tacotron2 和 Transformer TTS model 均能够得到很接近真实的人声录音(即 ground truth)的得分。在 CMOS 测试中(成对比较,得分 [-3,3] 分),我们的方法相比 Tacotron2 能够得到显著的性能提升。
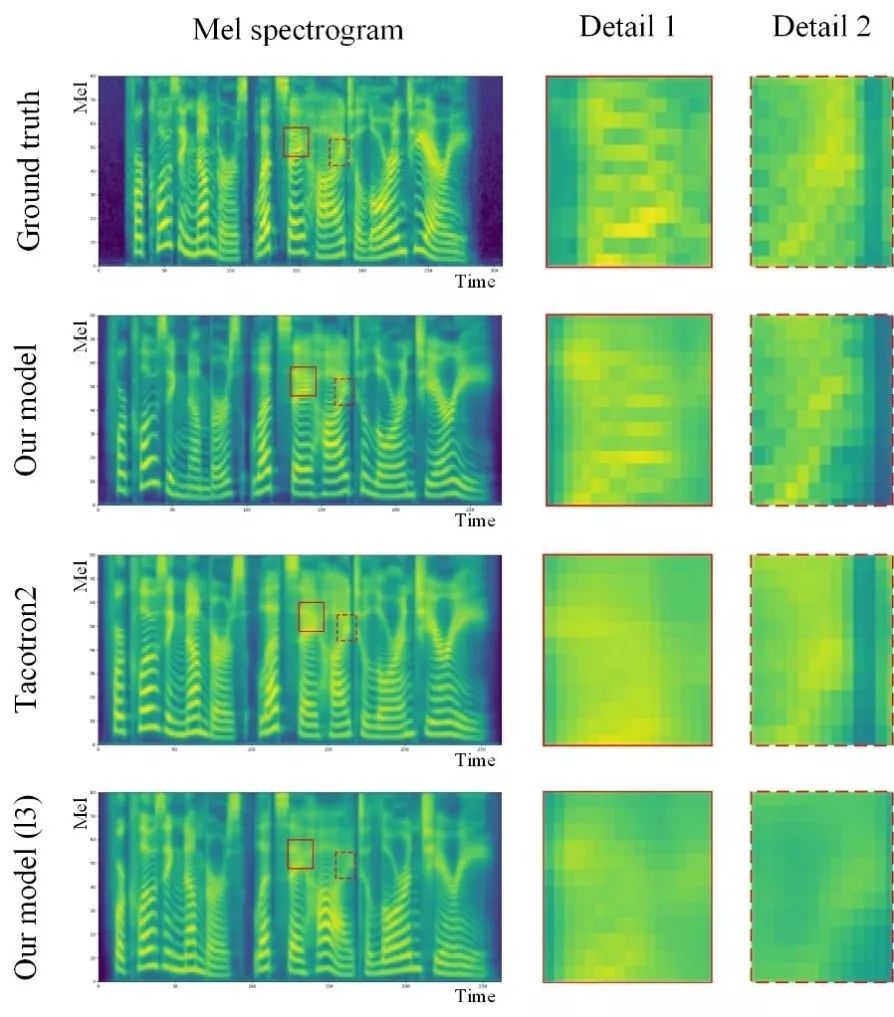
另一方面,对比 Transformer TTS model 和 Tacotron2 合成的 mel 谱,可以发现,在低频部分二者相近,都表现出了很强的能力;在高频部分,Transformer TTS model 能更好地还原频谱的纹理,从而使合成的音频有更高的质量。
基于改写的复述生成模型更高效
代表论文:Dictionary-Guided Editing Networks for Paraphrase Generation
论文链接:https://arxiv.org/pdf/1806.08077.pdf
在自然语言处理中,句子复述应用很广泛,例如被应用在信息检索、自动文摘、句子翻译等任务。句子复述(Paraphrase)是指换一种方式表达原句,同时要与原句意思相同。人在完成句子复述的时候,往往会使用同义词替换句子中的一些词语,然后对替换后的句子进行简单的修改。
以此为出发点,该论文提出了基于改写网络的复述生成模型。复述生成模型首先使用原句进行检索,得到一组词语级别的复述对;然后将检索得到的复述对进行编码,得到一组固定长度的向量;最后基于改写网络完成句子的复述。
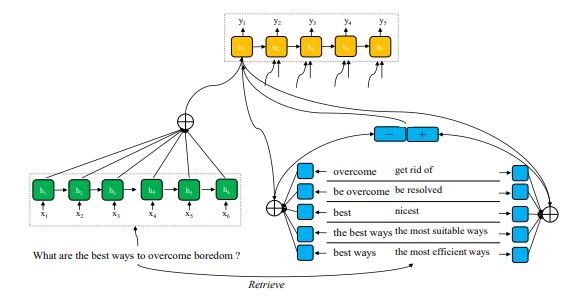
上图所示,复述生成模型建立在序列到序列模型(Seq2Seq)的框架下,进行解码的过程中,采用了注意力机制(attention mechanism),对检索得到的复述对进行权重组合,将加权之后的结果用于解码器。如模型在解码到 overcome 的时候,会更加侧重于使用(overcome,get rid of)这样的复述对。通过注意力机制让模型自己学习如何进行改写,在哪些地方需要进行替换和调整。
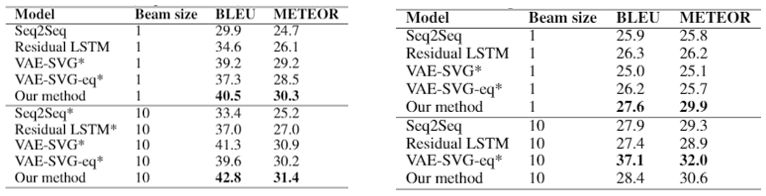
通过在 MSCOCO 和 Quora 两个公开数据集上实验,如上图所示,基于改写网络的复述生成模型在 MSCOCO 数据集上取得了最好的实验结果,在 Quora 数据集上,在贪婪搜索的条件下取得了最好的结果。
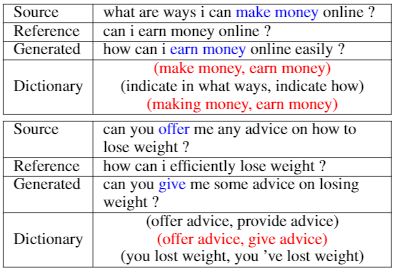
另外,通过分析实验结果显示,如上图,在生成的复述中,机器会基于检索得到的复述对进行改写和替换,采用这种方式既保证了复述结果与原句的区别,同时又不会改变原意。
计算机视觉
MonoGRNet:单张图像估测物体三维位置
在图像中,传统的物体定位或检测估计二维边界框,可以框住属于图像平面上物体的可见部分。但是,这种检测结果无法在真实的 3D 世界中提供场景理解的几何感知,这对很多应用的意义并不大。
代表论文:MonoGRNet:A Geometric Reasoning Network for Monocular 3D Object Localization
论文链接:https://arxiv.org/abs/1811.10247
该论文提出了使用 MonoGRNet,从单目 RGB 图像中通过几何推断,在已观察到的二维投影平面和在未观察到的深度维度中定位物体非模态三维边界框(Amodal Bounding Box, ABBox-3D),即实现了由二维视频确定物体的三维位置。
MonoGRNet 的主要思想是将 3D 定位问题解耦为几个渐进式子任务,这些子任务可以使用单目 RGB 数据来解决。网络从感知 2D 图像平面中的语义开始,然后在 3D 空间中执行几何推理。这里需要克服一个具有挑战性的问题是,在不计算像素级深度图的情况下准确估计实例 3D 中心的深度。该论文提出了一种新的个体级深度估计(Instance Depth Estimation, IDE)模块,该模块探索深度特征映射的大型感知域以捕获粗略的实例深度,然后联合更高分辨率的早期特征以优化 IDE。
为了同时检索水平和垂直位置,首先要预测 3D 中心的 2D 投影。结合 IDE,然后将投影中心拉伸到真实 3D 空间以获得最终的 3D 对象位置。所有组件都集成到端到端网络 MonoGRNet 中,其中有三个 3D 推理分支,如下图。最后通过联合的几何损失函数进行优化,最大限度地减少 3D 边界在整体背景下的边界框的差异。

MonoGRNet 由四个子网络组成,用于 2D 检测(棕色),个体深度估计(绿色),3D 位置估计(蓝色)和局部角落回归(黄色)。在检测到的 2D 边界框的引导下,网络首先估计 3D 框中心的深度和 2D 投影以获得全局 3D 位置,然后在本地环境中回归各个角坐标。最终的 3D 边界框基于估计的 3D 位置和局部角落在全局环境中以端到端的方式进行优化。
根据对具有挑战性的 KITTI 数据集的实验表明,该网络在 3D 物体定位方面优于最先进的单眼方法,且推理时间最短。

3D 检测性能,KITTI 验证集上的 3D 边界框的平均精度和 每张图像的推理时间。注意不比较基于 Stereo 的方法 3DOP,列出以供参考。
MVPNet:单张图像重建物体三维模型
在相同的图像中,由于形状、纹理,照明和相机配置的不同,若想从单幅 RGB 图像重建三维物体,这是一个强不适定的问题。但深度学习模型让我们重新定义这个任务,即从一个特定的分布生成实际样本。深度卷积神经网络得益于规则的表达形式、数据采样密度高、权重共享等等。
三角网格(triangular mesh)是表面(surface)的主要表示形式,但它的不规则结构不易编码和解码;大多数现存的深网使用三维体素网格(3D volumetric grid),但是稠密采样计算复杂性高;最近的一些方法提倡无序点云表示,但无序属性需要额外的计算才能为点对点建立一一对应的映射,这各高代价的映射算法,通常会使用较少的点来表示,从而产生稀疏的表面。
代表论文:MVPNet: Multi-View Point Regression Networks for 3D Object Reconstruction from A Single Image
论文链接:https://arxiv.org/abs/1811.09410
为了描绘稠密的表面,该论文引入了一种有效的基于多视图(multi-view)的表现形式,通过用多个视点可见的稠密点云并集来表示表面,分配视点时覆盖尽量多的表面。
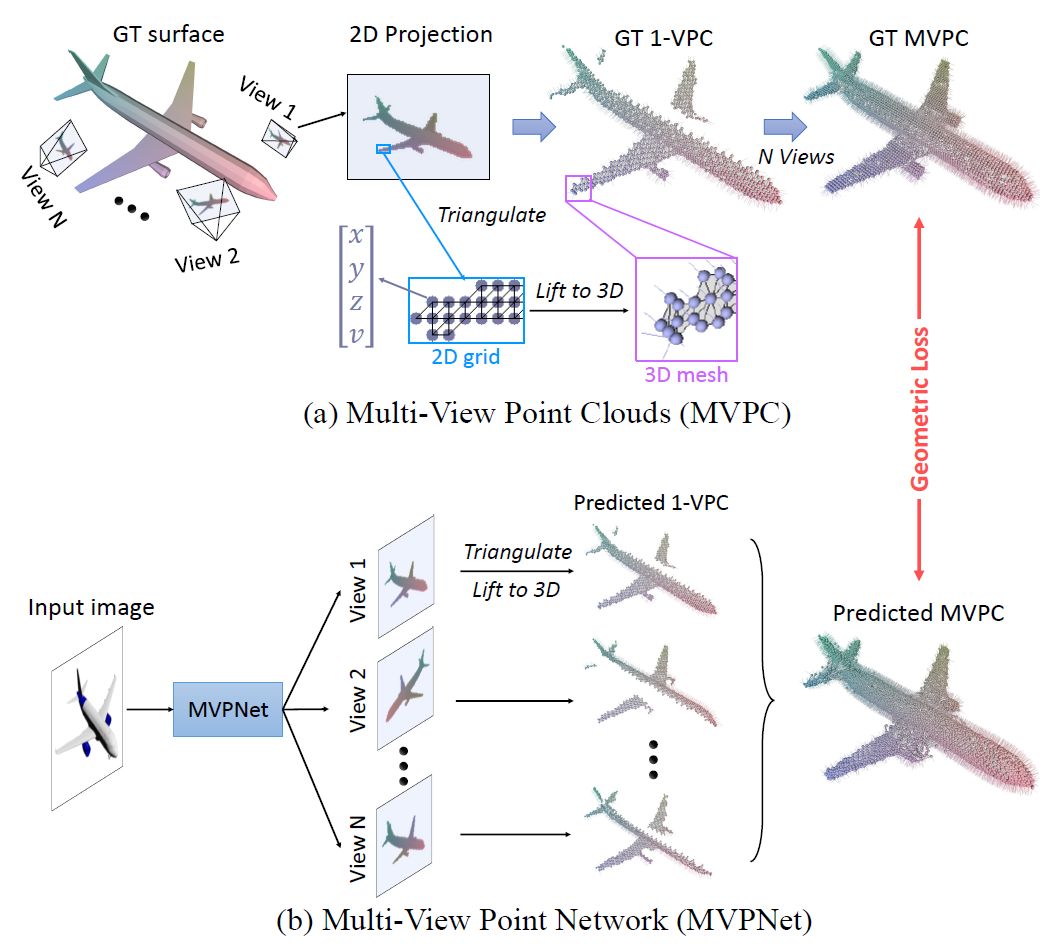
(a)MVPC 表示。1-VPC 中的每个像素都存储来自该像素的反投影表面点(x,y,z)及其可见性 v 。存储的三维点根据图像平面上的二维网格进行三角化,此图显示网格三角形的法线以指示表面的方向。(b)给定 RGB 图像,MVPNet 生成一组 1-VPC,它们的联合形成了预测的 MVPC。几何损失函数用来测量预测和真实的 MVPC。
上图描绘了多视图点云(MVPC)。每个点云存储在嵌入视图像平面中的二维网格中。单视点云(1-VPC)看起来像深度图,但每个像素存储三维坐标和可见性信息,而不是来自该像素的反投影表面点的深度。反投影变换提供了 1-VPC 中具有相等摄像机参数的点集的一对一映射。同时,该论文从二维网格引入三维点的局部连通性,促使基于这些反投影点形成三角形网格表面。至此,表面重建问题被转化为回归存储在 MVPC 中的三维坐标和可见性信息。
通过使用编码器 - 解码器网络作为条件采样器来生成 MVPC,上图(b)所示。编码器提取图像特征并分别将它们与不同的视点特征组合。解码器由多个权重共享分支组成,每个分支生成一个视图相关的点云。所有 1-VPC 的联合构成了最终的 MVPC,如下图。
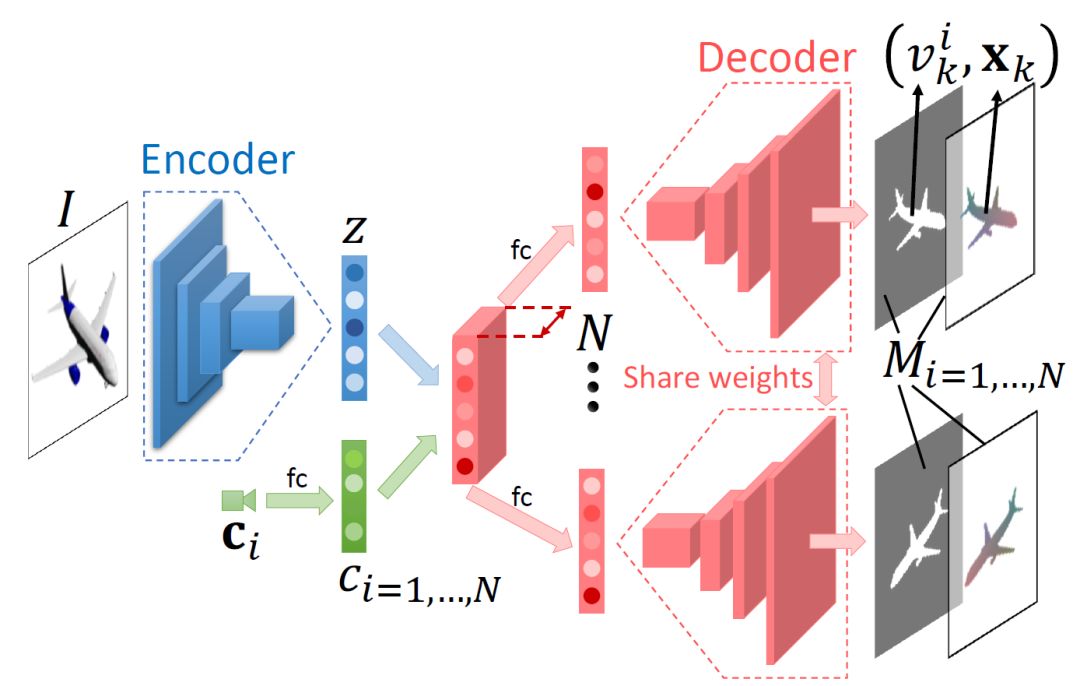
给定输入图像 I,由编码器和解码器组成的 MVPNet 对 N 个视点 c _i 的 1-VPC 进行回归。 N 个特征(z,c_i)被馈送到解码器的 N 个分支中,其中分支共享权重。
这里提出了一种新颖的几何损失函数,如下图,来衡量真实三维表面与二维平面相比的差异。与先前基于视图的方法不同,他们间接计算二维投影空间(即图像平面)中的特征而且忽略了由于从三维到二维的降维而导致的信息损失,这里 MVPC 允许我们在构造的三角形网格上作离散表面变化的积分,即直接计算了三维表面。几何损失函数整合了三维体积变化,预测置信度和多视图一致性,大大提高了三维重建的精确度。
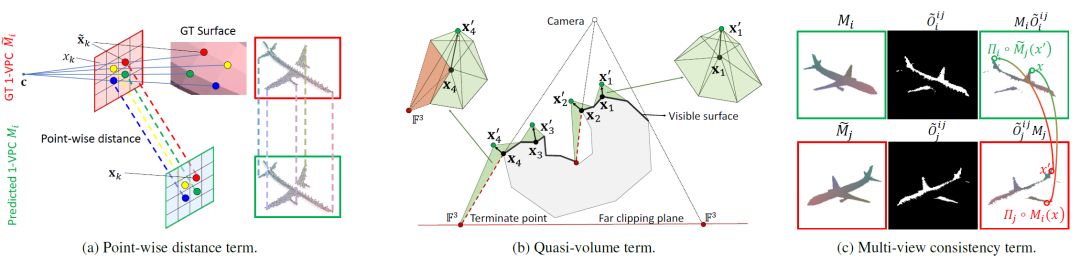
损失函数(a)1-VPC 的逐点距离(b)准量三维体积差异(c)多视图一致性
下图展示了在公共数据集 ShapeNet 和真实图像的结果,可见这个方法可以生成稠密的三维表面。另外,使用两个学到的特征作线性差值后再用解码器生成的三维重建模型,MVPNet 学到的特征空间具有较好的表达性和连续性。


ShapeNet 数据集结果比较

真实图像三维重建结果

学习到的特征线性插值生成的三维重建结果
微软亚洲研究院全部被接受论文列表如下:
Active Mini-Batch Sampling using Repulsive Point Processes
Balanced Sparsity for Efficient DNN Inference on GPU
Capacity Control of ReLU Neural Networks by Basis-path Norm
Deep Single-View 3D Object Reconstruction with Visual Hull Embedding
Detect or Track: Towards Cost-Effective Video Object Detection/Tracking
Dictionary-Guided Editing Networks for Paraphrase Generation
DRr-Net: Dynamic Re-read Network for Sentence Semantic Matching
Explainable Recommendation Through Attentive Multi-View Learning
FANDA: A Novel Approach to Perform Follow-up Query Analysis
Learning Basis Representation to Refine 3D Human Pose Estimations
Leveraging Web Semantic Knowledgein Word Representation Learning
LiveBot: Generating Live Video Comments Based on Visual and Textual Contexts
MonoGRNet:A Geometric Reasoning Network for Monocular 3D Object Localization
MVPNet: Multi-View Point Regression Networks for 3D Object Reconstruction from A Single Image
Neural Speech Synthesis with Transformer Network
Non-Autoregressive Machine Translation with Auxiliary Regularization
Non-Autoregressive Neural Machine Translation with Enhanced Decoder Input
Popularity Prediction on Online Articles with Deep Fusion of Temporal Process and Content Features
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
Regularizing Neural Machine Translation byTarget-bidirectional Agreement
Response Generation by Context-aware Prototype Editing
Sentence-wise Smooth Regularization for Sequence to Sequence Learning
Session-based Recommendation with Graph Neural Network
TableSense: Mask R-CNN for Spreadsheet Table Detection
Tied Transformers: Neural Machine Translation with Shared Encoder and Decoder
Trust Region Evolution Strategies
Unsupervised Neural Machine Translation with SMT asPosterior Regularization
-
微软
+关注
关注
4文章
6590浏览量
104024 -
机器学习
+关注
关注
66文章
8406浏览量
132558 -
论文
+关注
关注
1文章
103浏览量
14956
原文标题:AAAI 2019:一文看全微软亚洲研究院 27 篇重点论文
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工智能方向在哪里?看微软亚洲研究院四任院长的建言
中马研究院正式挂牌成立
中科院海西研究院泉州装备制造研究所现代电机控制与电力电子实验室招聘公告
英特尔研究院与联想研究院签署研究院合作框架协议
微软将在上海设立微软亚洲研究院
微软亚洲研究院被誉为AI黄埔军校,覆盖了国内高科技领导的半壁江山
ICLR 2019最佳论文日前揭晓 微软与麻省等获最佳论文奖项
微软亚洲研究院"创新汇": AI为数字化转型注入动能
微软亚洲研究院开发出了一种超级凤凰人工智能系统
微软亚洲研究院的研究员们提出了一种模型压缩的新思路
为什么中国移动3个月成立了三个研究院?
微软亚洲研究院把Transformer深度提升到1000层
微软亚洲研究院否认撤离中国,但确认部分 AI 科学家将迁至温哥华
科学匠人 | 边江:在研究院的七年“技痒”,探寻大模型助力AI与产业融合之道






 工商网监
工商网监
评论