 fast.ai上线2019深度学习新课程啦,100%全新前沿实战
fast.ai上线2019深度学习新课程啦,100%全新前沿实战
从 2017 年开始,fast.ai 创始人、数据科学家 Jeremy Howard 以每年一迭代的方式更新“针对编程者的深度学习课程”(Practical Deep Learning For Coders)。这场免费的课程可以教大家如何搭建最前沿的模型、了解深度学习的基础知识。直到今年已经是第三个年头了。

1 月 24 日,fast.ai 上线 2019 版深度学习新课程。据介绍,该课程 100% 全新,包括以前从未涵盖过的深度学习入门课程,甚至其中某些技术成果还尚未发表学术论文。
如以往一样,Jeremy Howard 公开了本次课程将涵盖的所有细节内容。他表示,本次课程共有七节,每节课大约 2 小时,当然,预计完成课后作业的时间将有 10 小时。

课程将涉及的应用案例
本次课程设计关键应用包括:
计算机视觉(例如按品种分类宠物照片)
图像分类
图像定位(分割和激活图)
图像关键点
NLP(如电影评论情绪分析)
语言建模
文档分类
表格数据(如销售预测)
分类数据
连续数据
协作过滤(如电影推荐)
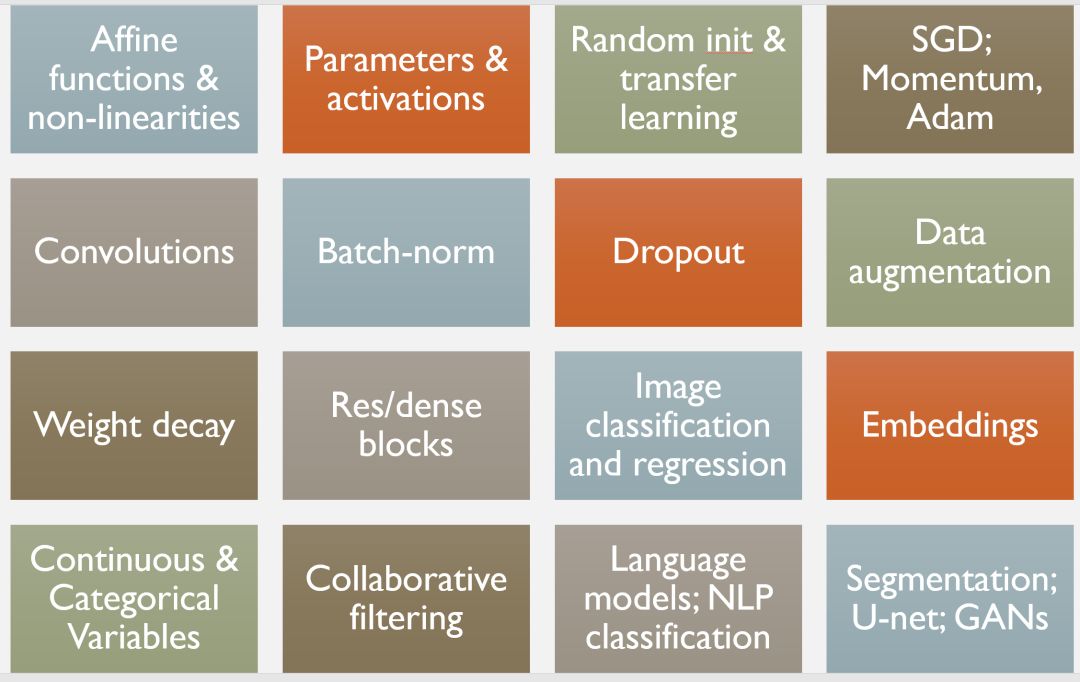
课程涵盖的基础
课程链接传送:https://course.fast.ai
目标人群:至少有一年的编程经验,且最好是 Python,fast.ai 还提供了Python 相关的学习资源。
第 1 课:图像分类
该系列课程第一课,是训练一个能以最高精准度识别宠物品种的图像分类器。其中,迁移学习的使用时本次课程的基础。我们将了解如何分析模型,以了解其失效模型,或许还能发现,模型出错的地方与育种专家犯了相同的错误。
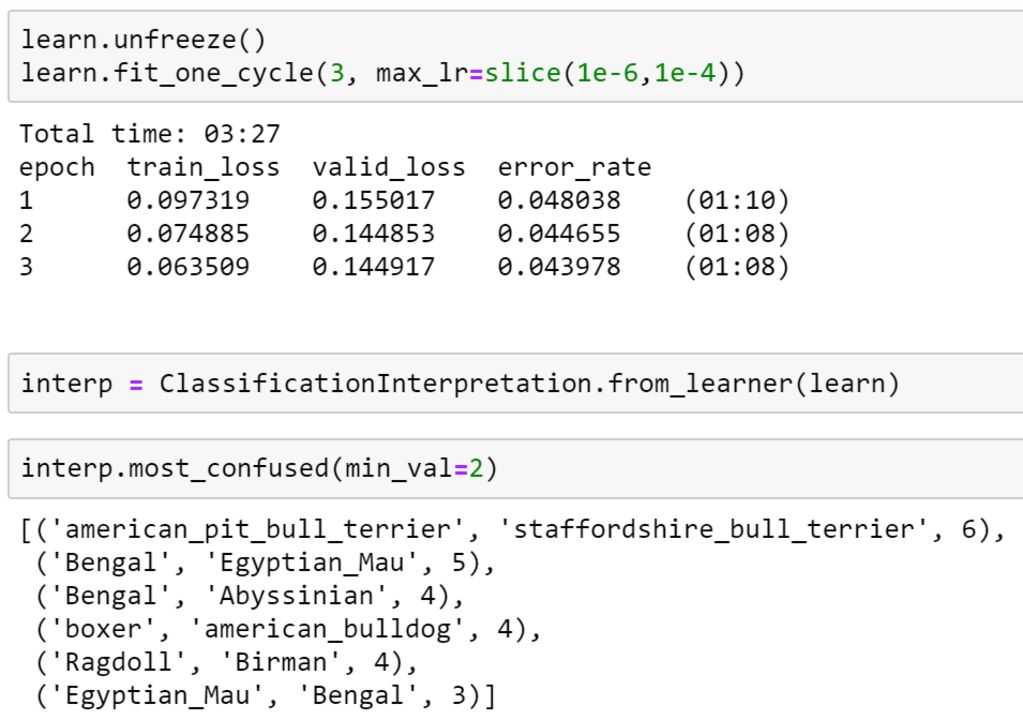
训练和分析宠物品种分类器
我们将讨论课程的整体方法,这与先理论再实际应用的方式不同,课程旨在先进行实际应用再深入研究。
我们还将讨论如何在训练神经网络时设置最重要的超参数:学习率(这主要基于 Leslie Smith 的 learning rate finder)。最后,还会介绍“标签”的问题,并了解 fast.ai 所提供的功能,如可以轻松将标签添加到图像中。
第 2 课:数据清洗与构建;梯度下降法(SGD)
本节课程将学习如何使用自己的数据构建图像分类模型,主要包括以下几方面:
图像收集
并行下载
创建验证集
数据清洗,通过模型找到数据问题
如下图所示,我们可以创建一个可区分泰迪熊和灰熊任务的模型。
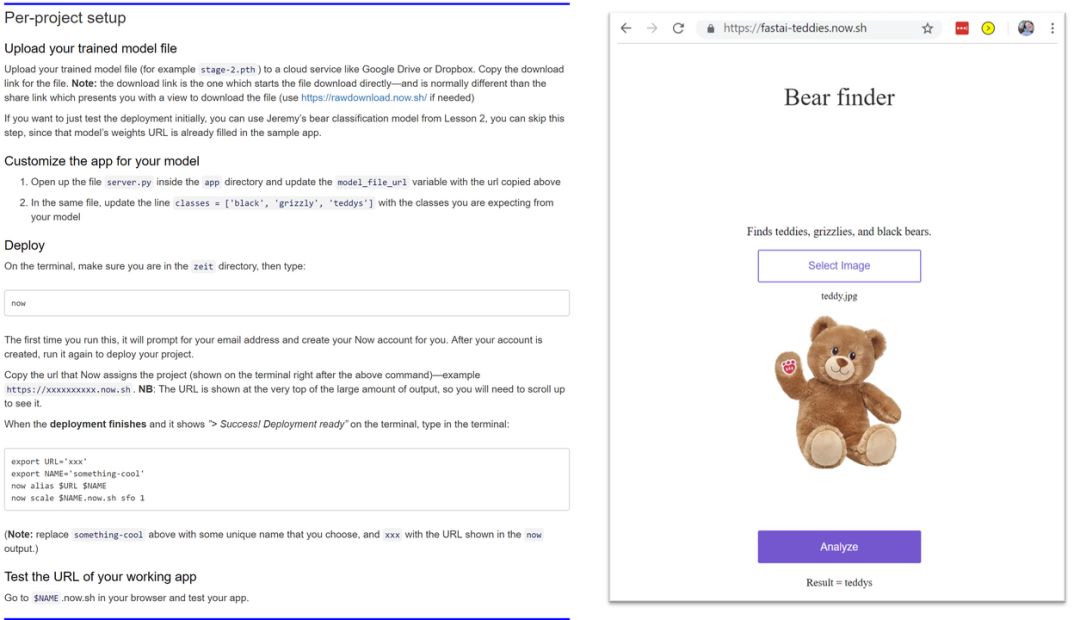
将模型投入生产
课程后半部分,将完整训练一个较为简单的模型,同时创建一个梯度下降循环。(注:在此过程中,将学习到很多新的术语,所以请确保做好笔记,因为在整个课程中都会引用这个新术语。)
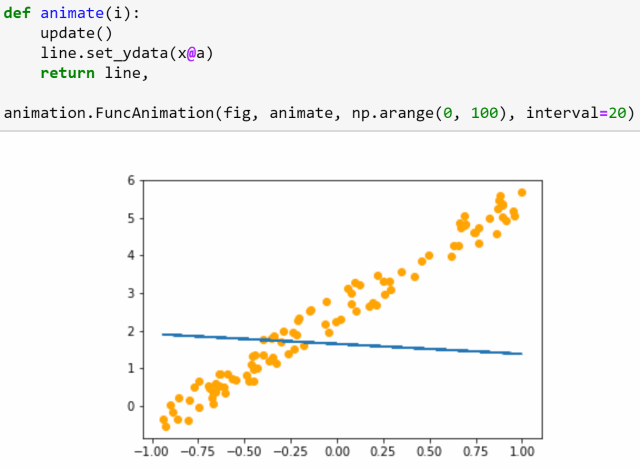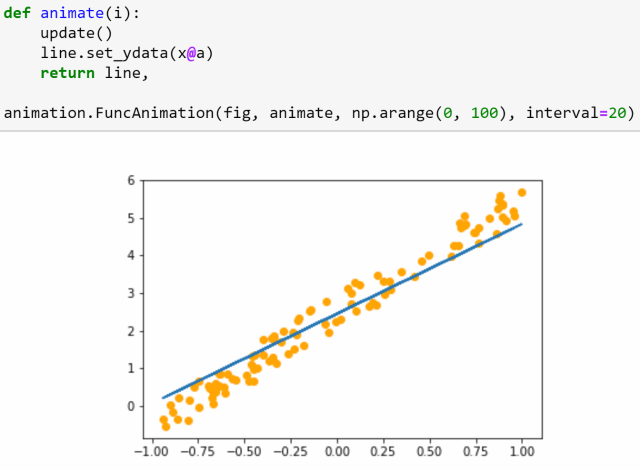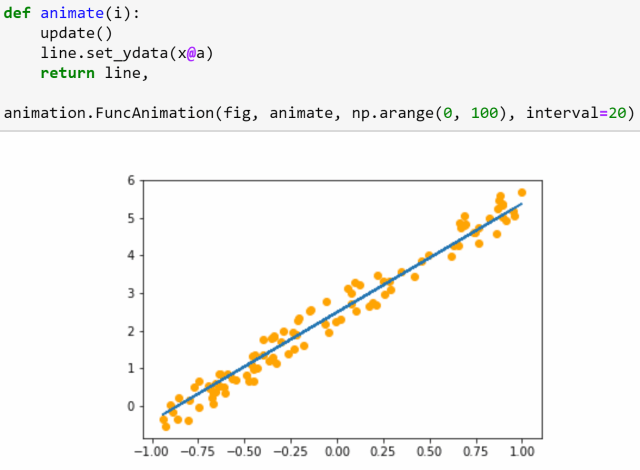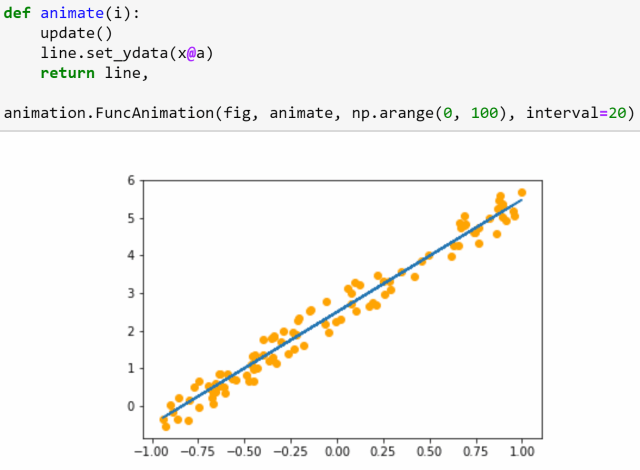
第3课:数据块;多标签分类;分割
本节课开始将主要研究一个有趣的数据集,叫做“Planet’s Understanding the Amazon from Space”。为了将这些数据转化为模型需要的形式,将使用 fast.ai 工具之一的数据块 API。
Planet 数据集的一个重要特征是,它是一个多标签数据集。也就是说,每个Planet图像可包含多个标签,而之前看过的数据集,每个图像只有一个标签。此外,可能还需要对多标签数据集进行修改。
图像分割模型的结果
接下来的图像分割,是一个标记图像中每个像素的过程,其中一个类别显示该像素描绘的对象类型。将使用与早期图像分类类似的技术,所以不需要太多调整。
本课程中还会使用到 CamVid 数据集,该模型误差远低于在学术文献中找到的任何模型。
假设:如果你的因变量是连续值而不是类别怎么办?我们将重点回答这个问题,查看关键点数据集,并构建一个精准预测面部关键点的模型。
第 4 课:NLP;表格数据;协同过滤;嵌入(Embeddings)
使用 IMDb 电影评论数据集深入研究自然语言处理(NLP)。在这项任务中,目标是预测电影评论是积极的还是消极的,这称为“情绪分析”。此前,在 fast.ai 2018 课程里提到的 ULMFit 算法,对 NLP 的发展起着重要作用。纽约时报曾报道:“新系统开始瓦解自然语言的代码。”ULMFiT 被认为是当今最准确的情绪分析算法。
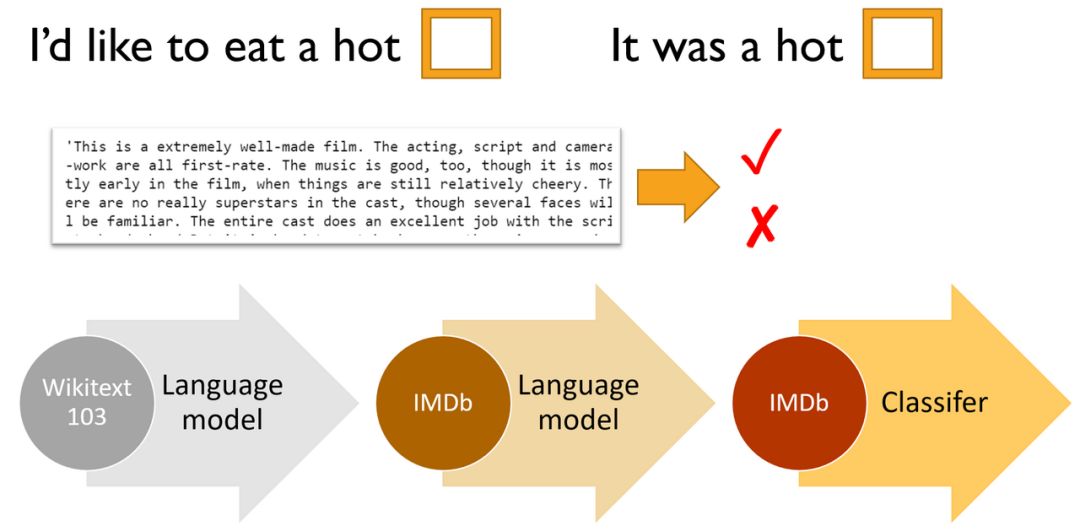
基本步骤如下:
(首选)创建(或下载预训练的)语言模型,该模型在大型语料库(如维基百科)上训练。(“语言模型”指的是学习预测句子下一个单词的任意一种模型。)
使用目标语料库(案例为 IMDb 电影评论)微调该语言模型。
在微调语言模型中删除编码器,并用分类器进行替换。然后对微调该模型以完成最终分类任务(情绪分类)。
在学习 NLP 的过程中,我们将通过覆盖表格数据(如电子表格和数据库表格)以及协作过滤(推荐系统)来完成使用的编码器深度学习的实际应用。
对于表格数据,我们还将看到如何使用分类变量和连续变量,以及如何使用 fast.ai. tabular 模块来设置和训练模型。
在课程中期,我们主要研究了如何在每个关键应用领域中构建和解释模型,包括:计算机视觉、NLP、表格数据、协同过滤等。
在课程的后半部分,我们将了解这些模型如何真正起作用、如何从头开始创建的过程,会涉及以下几部分:
激活
图层(仿射和非线性)
损失函数
第 5 课:反向传播;加速SGD;构建神经网络
本节课程中,将所有的训练融合在一起,以便讨论反向传播时准确理解发生了什么,并利用这些只是从头构建一个简单的神经网络。
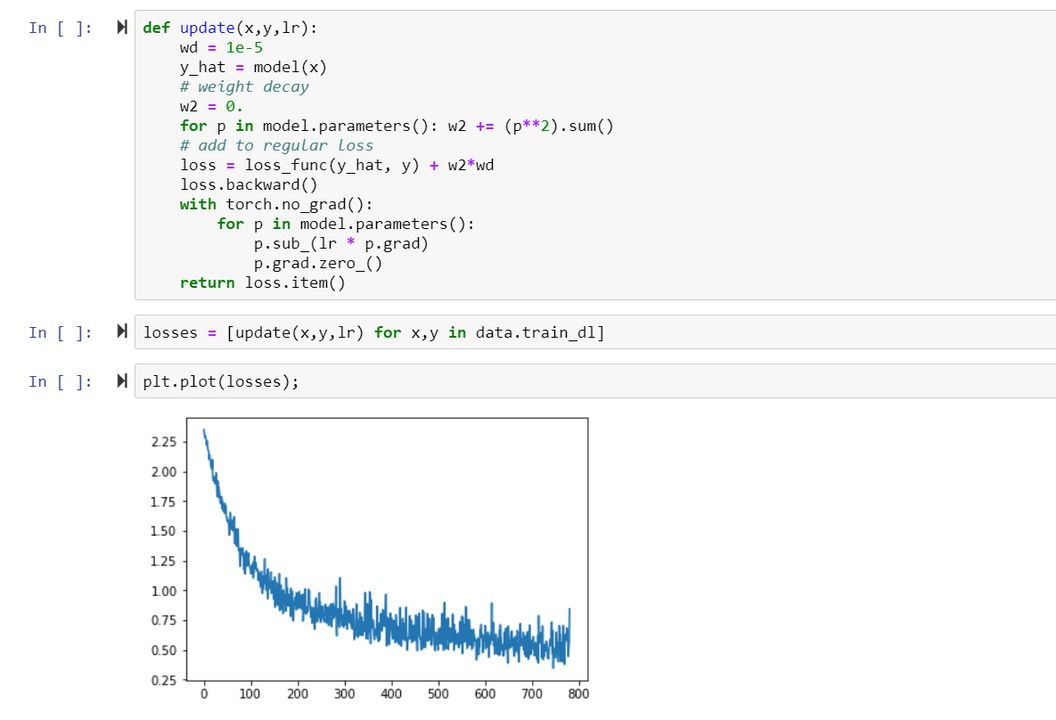
在这个过程中,可以看到嵌入层的权重,以找出模型从分类变量的中学到了什么。
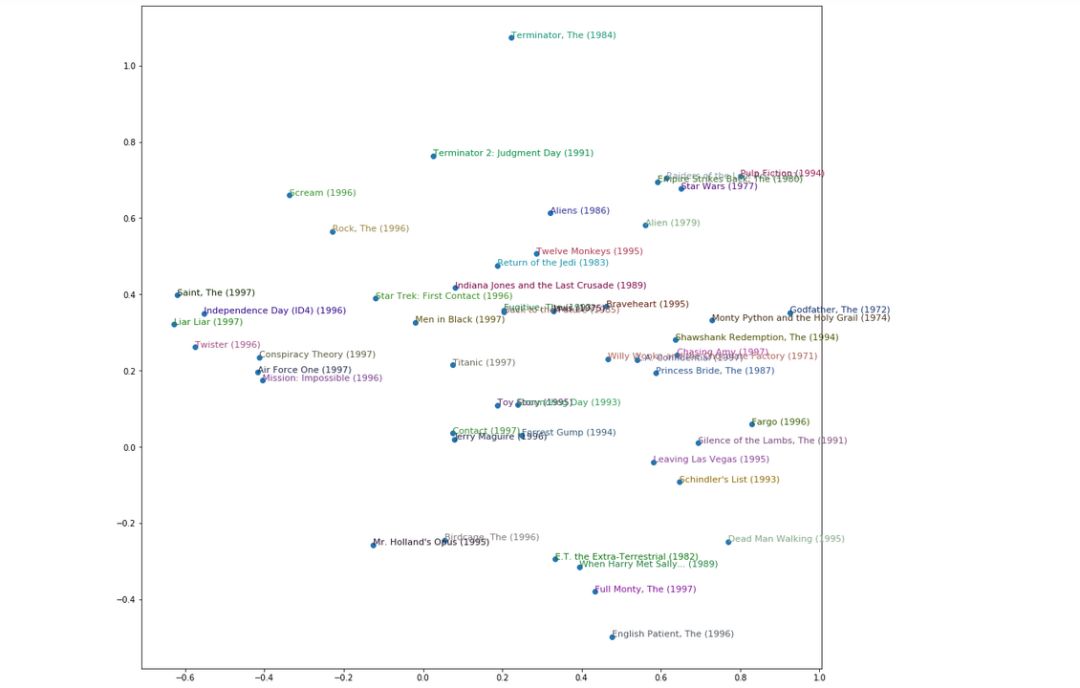
尽管嵌入在 NLP 的单词嵌入环境中最广为人知,但它们对一般的分类变量也同样重要,例如表格数据或协同过滤。它们甚至可以与非神经模型一起使用并取得巨大成功。
第 6 课:正规化;卷积;数据伦理
本节课主要讨论一些改进训练和避免过度拟合的技术:
Dopout:在训练期间随机删除激活,使模型正规化
数据增强:在训练期间修改模型输入,以便有效增加数据大小
批量标准化:调整模型的参数化,使损失表面更加平滑
单个图像的数据增强示例
接下来,我们将学习有关卷积的所有内容,卷积可被视为矩阵乘法的一种变体,也是现代计算机视觉模型的核心操作基础。
我们将创建一个类激活图。这是一个热图,显示图像的哪些部分在进行与测试时最重要。
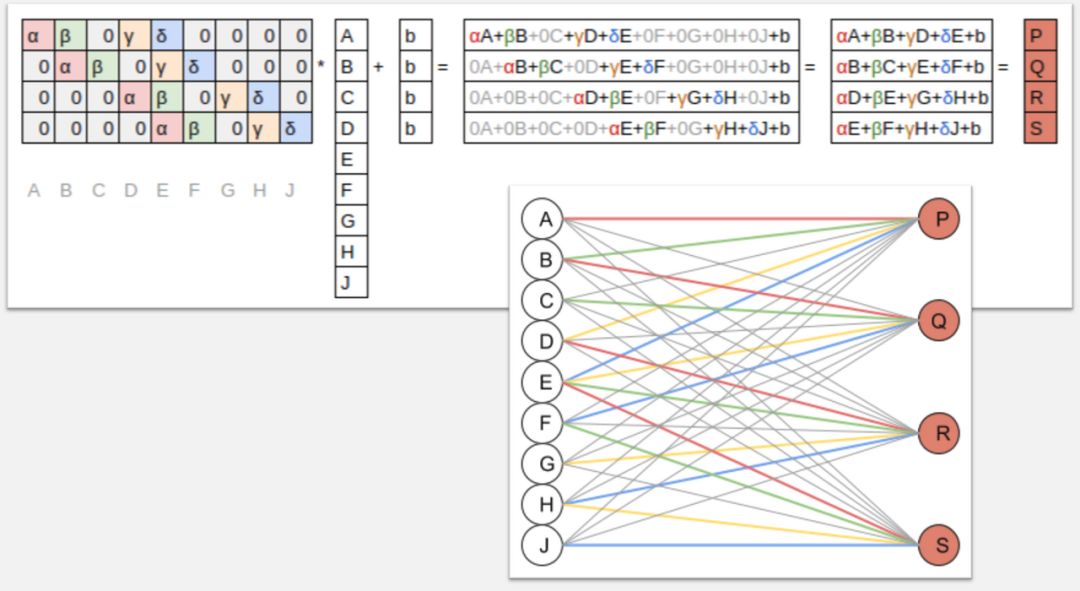
卷积如何运作
最后,我们还将提到:数据伦理。同学们将了解到模型出错的一些方法,尤其是反馈循环,其原因以及如何避免这些问题。我们还将研究数据偏差可能导致偏向算法的方式,并讨论数据科学家可以而且应该提出的问题,以确保他们的工作不会导致意外的负面结果。

美国司法系统中算法偏差的例子
第 7 课:构建 ResNet、U-Net;生成对抗网络
在最后一讲中,我们将研究现代架构中最重要的技术之一:跳跃连接(skip connection)。跳跃连接是 ResNet 最重要的应用,其主要在课程中用于图像分类,同样它还是很多前沿成果的基石。
我们还将研究 U-Net 架构,使用不同类型的跳跃连接极大改善了分段结果。
ResNet跳跃连接对损失表面的影响
然后,使用 U-Net 架构来训练超分辨率模型。这是一种可以提高低质量图像分辨率的模型,该模型不仅会提高分辨率,还会删除 jpeg 图片上伪迹和文本水印。
为了使我们的模型产生高质量的结果,需要创建一个自定义损失函数,其中包含特征损失(也称为感知损失)以及 gram 损失。这些技术可用于许多其他类型的 图像生成模型,例如图像着色。
使用特征损失和 gram 损失的超分辨率结果
我们将了解到一种称为生成性对抗性损失(用于生成性对抗性网络 GAN)的损失函数,可以在某些情况下以牺牲速度为代价来提高生成模型的质量。
例如,上文提到的还未发表的一些论文中所涉及的应用:
利用迁移学习,更快更可靠地训练 GAN
将架构创新和损失函数方法以前所未有的方式进行结合
结果令人惊叹,只需要几个短短几小时便可进行训练(与以前需要几天的方法相比)。
一个循环神经网络
最后,我们还将学到如何从头开始创建递归神经网络(RNN)。实际上,RNN 不仅是整套课程中 NLP 应用的基础模型,还被证明是规则的多层神经网络的一个简单重构。
课前须知:
1、Google Cloud 和微软 Azure 作为赞助方,已将课程所需的全部功能集成到基于 GPU 的平台上,并且提供“一键式”平台服务,如 Crestle 和Gradient 服务。
2、完成第一堂课后,学生可以在自己的数据上训练图像分类模型。整个上半部分重点是实用技术,仅展示在实践中用到的技术相关理论知识;课程的后半部分,将深入研究理论。直到最后一节课,将学习构建和训练一个 Resnet 的神经网络,以求接近最佳准确性。
3、 课程使用 PyTorch 库进行教学,可更轻松访问推荐的深度学习模型最佳实践,同时也可以直接使用所有底层的 PyTorch 功能。
4、学习内容同样适用于 TensorFlow/keras、CNTK、MXnet 或者任何其他深度学习库的任何任务。
5、电脑需要连接到安装了 fast.ai 库的云 GPU 供应商服务,或设置一个适合自己的 GPU。同时,还需要了解运行深度学习训练的 Jupyter Notebook 环境的基础知识。
6、课程笔记本提供了新的交互式GUI,用于使用模型查找和修复错误标记或错误收集的图像。
7、(强烈)建议学院参加该课程的在线社区。
-
图像分类
+关注
关注
0文章
90浏览量
11914 -
计算机视觉
+关注
关注
8文章
1696浏览量
45959 -
深度学习
+关注
关注
73文章
5497浏览量
121076
原文标题:2019最新实战!给程序员的7节深度学习必修课,最好还会Python!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
HarmonyOS开发宝典震撼来袭,卓越应用开发之旅一触即发,轻松启程!

【免费领取】AI人工智能学习资料(学习路线图+100余讲课程+虚拟仿真平台体验+项目源码+AI论文)

【全新课程资料】正点原子《基于GD32 ARM32单片机项目实战入门》培训课程资料上线!
【全新课程资料】正点原子《ESP32基础及项目实战入门》培训课程资料上线!
【全新课程资料】正点原子《ESP32物联网项目实战》培训课程资料上线!
课程上线 - RT-Thread应用开发实践课程上线慕课平台啦!

NVIDIA推出全新深度学习框架fVDB
基于AI深度学习的缺陷检测系统
泰禾智能携AI智选深度学习系列新品亮相临沂花生展
HDC2024华为发布鸿蒙原生智能:AI与OS深度融合,开启全新的AI时代






 工商网监
工商网监
评论