 Facebook研究者扩展并增强LASER工具包,并在近期开源这个项目
Facebook研究者扩展并增强LASER工具包,并在近期开源这个项目
为了加速自然语言处理 (NLP) 在更多语言上实现零样本迁移学习 (zero-shot transfer learning),Facebook 研究者扩展并增强了 LASER (Language-Agnostic Sentence Representations) 工具包,并在近期开源了这个项目。
增强版的 LASER 是首个能够成功探索大型多语种句子表征的工具包,共包含 90 多种语言,由 28 种不同的字母表编写。这项庞大的工作也引发了整个 NLP 社区的广泛关注。该工具包将所有语言联合嵌入到单个共享空间,而不是为每个语言单独建立模型。目前,Facebook 官方免费提供多语言编码器和 PyTorch 代码(链接:https://github.com/facebookresearch/LASER),以及 100 多种语言的多语言测试集方便社区使用。
研究者表示,通过零样本迁移学习,LASER 能够将 NLP 模型从一种语言 (如英语) 迁移到其他语言 (包括训练集中的有限语种)。此外,LASER 工具也是第一个使用单一模型来处理不同语种的自然语言处理库,包括处理那些稀有语种如卡拜尔语、维吾尔语以及中国的吴语等方言。研究者相信,有朝一日这项工作能够帮助 Facebook 及其他公司上线特定的 NLP 功能,如用一种语言将电影评论分类为正面或负面,然后再部署到其他 100 多种语言上去。
下面让我们一睹 LASER 工具包的风采。
性能和功能亮点
在包含 14 种语种的 XNLI 语料库中,LASER 工具通过零样本迁移学习,为其中 13 种语言实现跨语种的自然语言处理,并获得当前最佳的推断准确率。此外,它还在跨语言文档分类 (MLDoc 语料库) 中取得了极有竞争力的结果。在句子嵌入方面,该工具包在并行语料库挖掘任务中也展现了强大的功能,并在 BUCC 共享任务中为其四种语言对中的三种建立了当前最佳的基准。值得一提的是,BUCC 是 2018 年建立和使用可比较语料库的研讨会,代表了当前该领域的最新进展。
除了 LASER 工具包,研究者还基于 Tatoeba 语料库共享一组 100 多种全新语言对齐语句的测试集。通过该数据集,在多语言相似性搜索任务上,句子嵌入功能取得了非常优秀的结果,即便是对那些稀有语种也是如此。
此外,LASER 工具包还具有如下一些优点:
极快的性能和极高的处理效率:在 GPU 上每秒处理多达 2000 个句子。
通过 PyTorch 中实现句子编码器具有最小的外部依赖性。
稀有语种可以从多种语言的联合训练中收益。
该模型支持在一个句子中使用多种语言。
随着新语言的添加,模型性能也会有所提高,因为系统能够自动学习并识别语言族的特征。
通用的语言无关性句子嵌入
LASER 中的句子向量表征对于输入语言和 NLP 任务都是通用的。该工具将任何语种的句子映射到高维空间中的一个点,目的是将各语种的语句最终聚合在同一邻域附近,而这种句子表征可被视为是语义向量空间中的通用语言。如下图所示,可以看到该空间中的距离与句子语义的接近度是非常相关的。
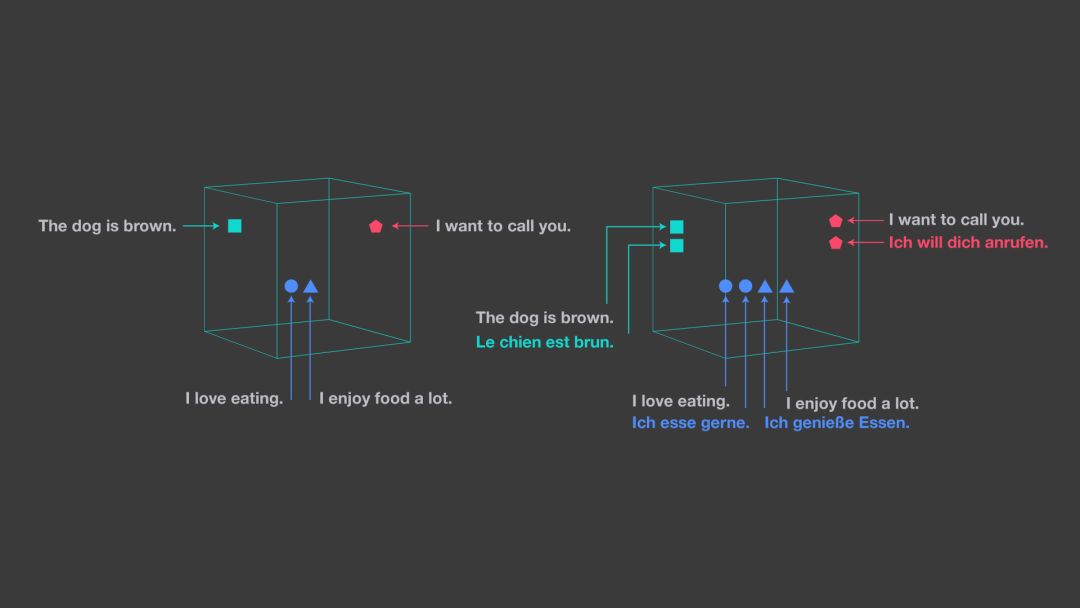
左图展示的是单个语言的嵌入空间,而右图显示的是采用 LASER 工具包方法,它能将所有语言嵌入到同一共享空间中。
LASER 的这种方法是基于神经机器翻译的基础技术:即编码器/*** (encoder/decoder),也称为序列到序列处理 (sequence-to-sequence)。它为所有的输入语言设计一个共享编码器,并使用共享解码器生成输出语言。编码器由五层双向连接的 LSTM 网络 (长短期记忆) 组成。
与神经机器翻译的方法不同的是,LASER 中不引入注意力机制,而是使用 1024 维、固定大小的向量来表示输入句子。该向量是通过对 BiLSTM 最后状态进行最大池化操作后得到的,这使我们能够比较句子表征的差异,并将它们直接输入到分类器中。
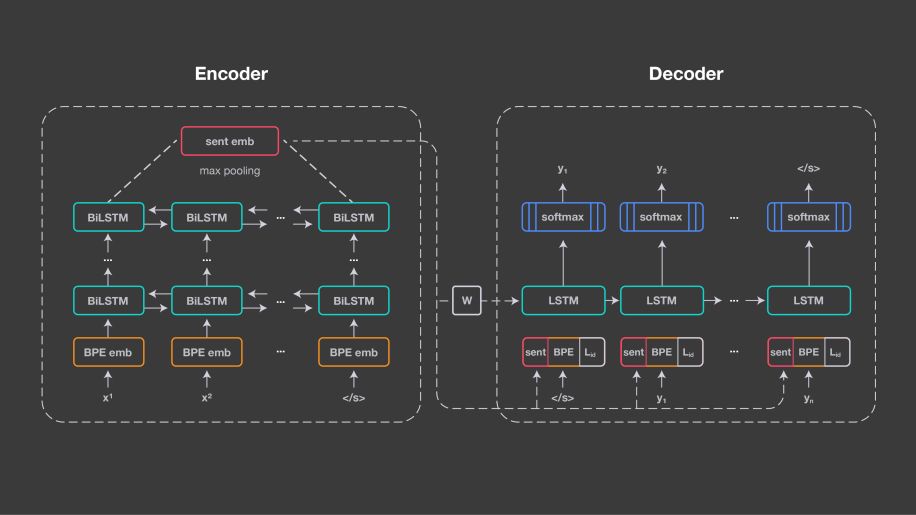
图中描述了 LASER 的基本架构
这些句子嵌入是通过线性变换的方式初始化解码器 LSTM,并且还在每个时间步骤与其输入嵌入相连接。为了通过句子嵌入来捕捉输入序列的所有相关信息,在架构中编码器和解码器之间没有设置其他连接。
对于解码器部分,由于它需要一个语言标识嵌入,因此需要清楚地知道需要生成哪种语言,并在每个时间步骤连接输入及其句子嵌入。研究者使用具有 50000 个操作的联合字节对编码词汇表 (BPE),并在所有训练语料库的连接上进行训练。由于编码器没有显式地指示输入语言信号,因此该方法鼓励它学习与语言无关的表征。
不仅如此,研究者还使用英语或西班牙语对公共并行数据中 2.23 亿条句子进行了系统的训练。对于每个小批量,随机选择一种输入语言并训练模型,使其将句子翻译成英语或西班牙语中的一种,而不需要让大多数语言都与目标语言保持一致。
这项工作的开始只是训练不到 10 种的欧洲语言,所有语言都使用相同的拉丁文字;随后逐渐增加到 21 种语言,这些都是在 Europarl 语料库中出现的。
实验结果表明,随着所添加的语言数量的增多,多语言间的迁移性能也得到了提高,而该系统也能够学习到语言族的通用特征。正因为如此,部分稀有语言也能够受益于同一语言族的一些高频语言的资源。
通过使用在连接所有语言的数据库上训练共享的 BPE 词汇表,这是完全有可能做到的。对每种语言的 BPE 词汇表分布之间对称的 Kullback-Leiber 距离进行分析和聚类结果表明,其与语言家族之间存在几乎完美的相关性。

图中显示了 LASER 能够自动挖掘各种语言之间的关系,这与语言学家手动定义的语言类别是高度吻合的。
研究者意识到,单个共享的 BiLSTM 编码器能够处理多个脚本。他们逐渐扩展到那些可用的并行文本中的所有语言,并将 93 种语言并入到 LASER 工具包中,这些语言包括 subject-verb-object (SVO) order (如英语),SOV order (如孟加拉语和突厥语),VSO order (如塔加路语和柏柏尔语),以及 VOS order (如马达加斯加语)。
该编码器能够推广到一些未使用的语言,甚至是单语言文本。在训练阶段,可以观察到它在一些地区语言中展现了突出的能力,包括阿斯图里亚斯语、法罗语、弗里斯兰语、卡舒比语、北摩鹿加语马来语、皮埃蒙特语、斯瓦比亚语和索布语等。这些语言与那些主要语言在不同程度上都有一定的相似之处,但不同语言有其特定的语法或特定词汇。
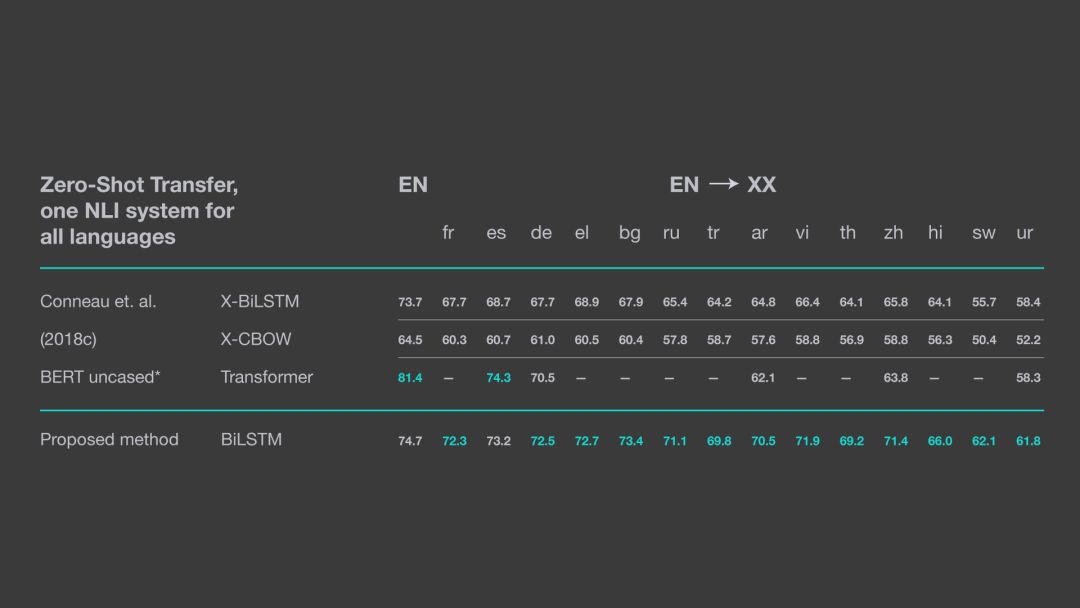
上表展示了 LASER 在 XNLI 语料库上进行零样本迁移学习的性能表现。其中,BERT 模型的结果是从其他 github 项目中提取的。值得注意的是,这些结果都是通过 Pytorch1.0 实现的,因此在具体数值方面可能与原论文中的有所不同,论文中使用的是 Pytorch0.4。
零样本、跨语言的自然语言推理
该模型在跨语言的自然语言推理任务上 (NLI) 取得了优异的成绩,表明模型具有极强的句意表征能力。研究者采用零样本迁移学习的方法,即先在英语上训练 NLI 分类器,在没有任何模型微调或其他目标语言数据的情况下,将训练好的分类器应用于其他目标语言。对于 14 种语言的 8 种,零样本学习在诸如英语、俄语、中文和越南语等语言上能够取得 5%以内的表现。
此外,研究者还在斯瓦希里语和乌尔都语等稀有语言上进行试验,同样取得了很好的结果。最后,LASER 方法在 14 种语言中有 13 种语言都取得了优于其他零样本迁移学习方法的表现。
相较于先前研究中至少需要一个英语句子进行学习的方法,LASER 是一种完全跨语种、并支持不同语言间任何组合的自然语言处理方法。
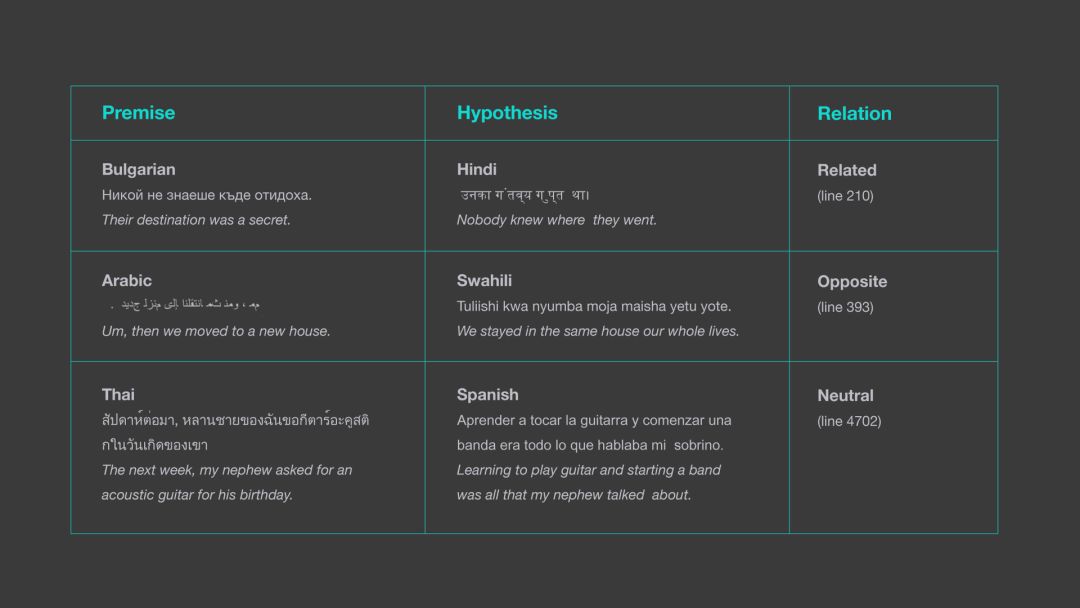
上图展示了 LASER 是如何确定 XNLI 数据集中不同语言句子间的关系,而先前研究中的方法都只能考虑同一种语言的前提和假设。
此外,LASER 也可用于挖掘大型单语言文本数据集中的并行数据信息。研究表明,只需要计算所有句子对之间的距离并选择最接近的句子对,就能够提取文本数据中的数据信息。更进一步地说,通过考虑相近句子及其最近邻居之间的边界能够改进该方法的表现,而通过使用 Facebook 的 FAISS 库就能够高效完成这一改进。
在共享 BUCC 任务上,LASER 的表现都远远超过当前最佳的技术水平。具体来说,该模型将德语/英语的 F1 得分从 85.5 提高到 96.2,将法语/英语的 F1 得分从 81.5 提高到 93.9,俄语/英语的 F1 得分从 81.3 提高到 93.3,中/英语的表现从 77.5 提高到 92.3。正如这些示例所反映的,该模型在各种语言任务上所取得结果都是高度同质的。
更多详细的内容介绍可以查看相关的论文:《Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond》(论文链接:https://arxiv.org/abs/1812.10464)。
最后,研究者表明,对于任意语言对,都可以通过相同的方法来挖掘 90 多种语言的并行数据。在未来,这将显著改善许多依赖于并行数据训练的 NLP 应用程序,包括那些稀有语言的神经机器翻译应用。
未来的应用
LASER 可以应用于广泛的自然语言处理任务。例如,多语言语义空间的属性可用于解析句意或搜索具有相似含义的句子,可以通过使用相同语言或通过 LASER 所支持的其他 93 个语句中的任何一个就能实现。未来,研究人员表示将继续添加其他的语言支持。
-
Facebook
+关注
关注
3文章
1432浏览量
55131 -
Laser
+关注
关注
0文章
22浏览量
9323 -
迁移学习
+关注
关注
0文章
74浏览量
5599
原文标题:Facebook增强版LASER开源:零样本迁移学习,支持93种语言
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Facebook开源了增强版的NLP工具包LASER
Facebook推出ReAgent AI强化学习工具包
java开源工具包-Jodd框架
CapSense用这个工具包来处理使用I2C和UART的工具箱?
AUTOSCOPE开发者工具包
微软在GitHub开源深度学习工具包
开发工具包加速亚千兆赫项目

NVIDIA发布65个全新及更新的软件开发工具包
NPOI WEG报表工具包简介





 工商网监
工商网监
评论