 对NAS任务中强化学习的效率进行深入思考
对NAS任务中强化学习的效率进行深入思考
神经网络结构搜索(Neural Architecture Search, NAS)是自动机器学习(AutoML)中的热点问题之一。通过设计经济高效的搜索方法,自动获得泛化能力强、硬件友好的神经网络结构,可以大量节省人工,解放研究员的创造力。经典的NAS方法[1]中,一个agent在trial and error中通过强化学习(Reinforcement Learning)的方式学习搭建网络结构。本文作者对NAS任务中强化学习的效率进行了深入思考,从理论上给出了NAS中强化学习收敛慢的原因。作者进一步重新建模了NAS问题,提出了一个更高效的方法,随机神经网络结构搜索(Stochastic NAS, SNAS)。
1)与基于强化学习的方法(ENAS[2])相比,SNAS的搜索优化可微分,搜索效率更高,可以在更少的迭代次数下收敛到更高准确率。
2)与其他可微分的方法(DARTS[3])相比,SNAS直接优化NAS任务的目标函数,搜索结果偏差更小,可以直接通过一阶优化搜索。
3)而且结果网络不需要重新训练参数。
4)此外,基于SNAS保持了概率建模的优势,作者提出同时优化网络损失函数的期望和网络正向时延的期望,扩大了有效的搜索空间,可以自动生成硬件友好的稀疏网络。
1. 背景
1.1 NAS中的MDP
图1展示了基于人工的神经网络结构设计和NAS的对比。完全基于人工的神经网络结构设计一般包括以下关键流程:
1)由已知的神经变换(operations)如卷积(convolution)池化(pooling)等设计一些拓扑结构,
2)在所给定训练集上训练这些网络至收敛,
3)在测试集上测试这些网络收敛结果,
4)根据测试准确率选择网络结构,
5)人工优化拓扑结构设计并回到步骤1。
其中,步骤5需要消耗大量的人力和时间,而且人在探索网络结构时更多的来自于经验,缺乏明确理论指导。将该步骤自动化,转交给agent在trial and error中不断优化网络结构,即是NAS的核心目的。
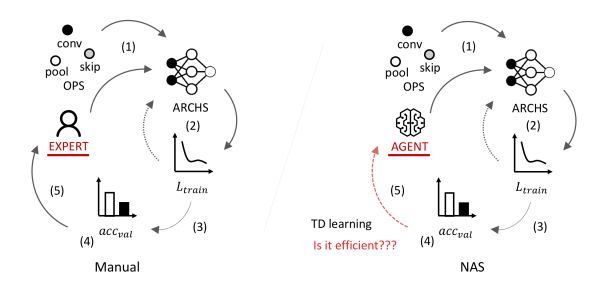
图1: 人工神经网络结构设计vs自动神经网络结构搜索
在人的主观认知中,搭建神经网络结构是一个从浅层到深层逐层选择神经变换(operations)的过程。 比如搭建一个CNN的时候需要逐层选择卷积的kernel大小、channel个数等,这一过程需要连续决策,因而NAS任务自然的被建模为一个马尔科夫决策过程(MDP)。
简单来说,MDP建模的是一个人工智能agent和环境交互中的agent动作(action,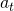 环境即是对网络结构的抽象,状态(state,
环境即是对网络结构的抽象,状态(state,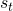 动作表示的是在下一层中要选怎样的卷积。
动作表示的是在下一层中要选怎样的卷积。
在一些情况下,我们会用策略函数(policy,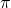 总得分,也就是搭建的网络在测试集上的精度(accuracy),通过强化学习(Reinforcement Learning)这种通用黑盒算法来优化。然而,因为强化学习本身具有数据利用率低的特点,这个优化的过程往往需要大量的计算资源。
总得分,也就是搭建的网络在测试集上的精度(accuracy),通过强化学习(Reinforcement Learning)这种通用黑盒算法来优化。然而,因为强化学习本身具有数据利用率低的特点,这个优化的过程往往需要大量的计算资源。
比如在NAS的第一篇工作[1]中,Google用了1800 GPU days完成CIFAR-10上的搜索。虽然通过大量的平行计算,这个过程的实际时间(wallclock time)会比人工设计短,但是如此大计算资源需求实际上限制了NAS的广泛使用。[1]之后,有大量的论文从设计搜索空间[4]、搜索过程[2]以及model-based强化学习[5]的角度来优化NAS效率, 但“基于MDP与强化学习的建模”一直被当作黑盒而没有被讨论过。
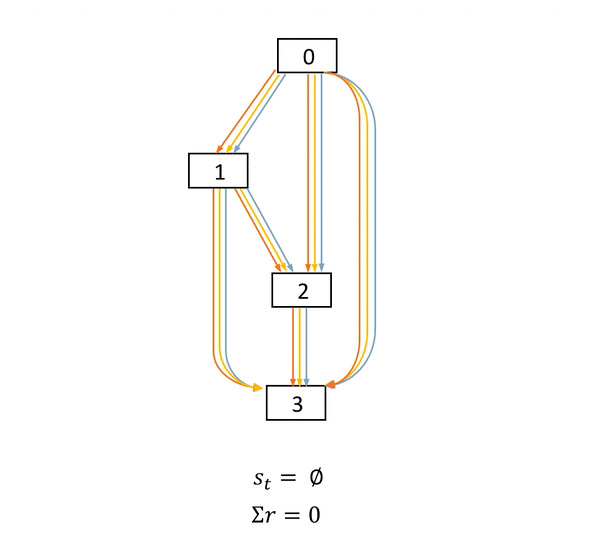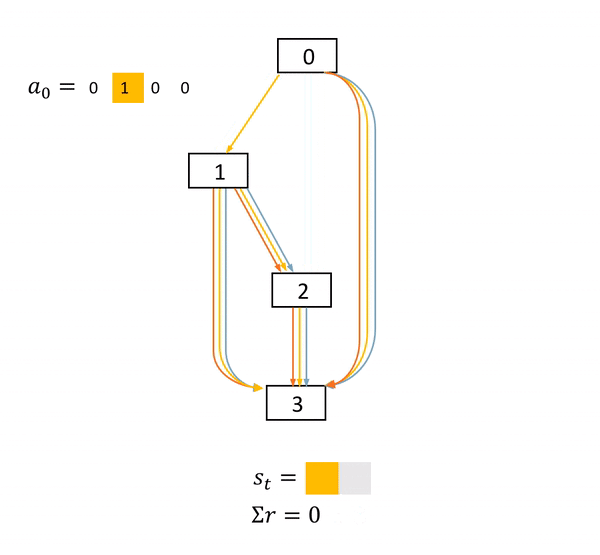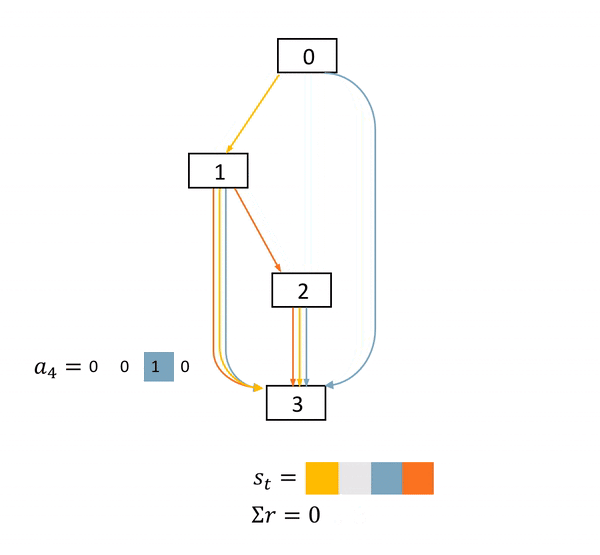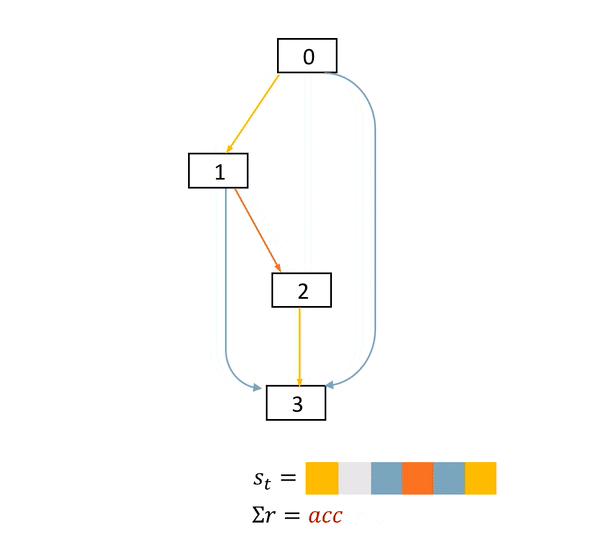
图2: NAS是一个确定环境中的完全延迟奖励任务。在这个DAG中,方框表示节点,具体的物理意义是feature map。不同颜色的箭头表示不同的operations。s表示当前网络结构状态,a表示每一步的动作,r表示得分。只有在网络结构最终确定后,agent才能获得一个非零得分acc
本文作者的关键insight来自于发现了NAS任务的MDP的特殊性。图2展示了一个NAS的MDP的完整过程。可以看到的是,在每一个状态(state)中,一旦agent产生了动作,网络结构状态的改变是确定的。而在一个网络被完全搭建好并训练及测试之前,agent的每一个动作都不能获得直接的得分奖励。agent只会在整一条动作序列(trajectory)结束之后,获得一个得分。
我们简单总结一下,就是,NAS是一个确定环境中的完全延迟奖励的任务。(A task with fully delayed reward in a deterministic environment.)如何利用网络结构状态改变的确定性,将在下一个章节被讨论。
在本章节接下来的部分,我们先介绍一些强化学习领域的背景,解释一条动作序列的得分是如何被分配到每一次动作上的,以及延迟奖励为什么造成了这种得分分配的低效。
1.2 TD Learning与贡献分配
强化学习的目标函数,是将来得分总和的期望。从每一个状态中动作的角度来说,agent应该尽量选择长期来说带来最大收益的动作。然而,如果没有辅助的预测机制,agent并不能在每一个状态预测每一个动作将来总得分的期望。TD Learning就是用来解决这个问题,预测每一个动作对将来总得分的贡献的。TD(0),一种最基本的计算每一个状态上的总得分期望(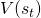 )的TD Learning,如以下公式所示:
)的TD Learning,如以下公式所示:
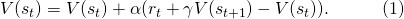
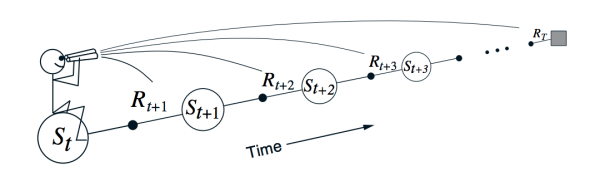
图3: 在TD Learning中,agent对于某一状态价值的评估基于它对将来状态的评估,图片来自 [6]
可以看出,以一种基于动态规划的方式,agent对于每一个状态的将来总得分的期望,从将来的状态向过去传播。Sutton在[6]中用一张图来表现了这种得分从后向前的传播,如图3所示。
也就是说,agent对于某一状态的价值的评估基于它对该状态将来状态的评估。值得注意的是,(1)中TD的回传是一个局部的回传,并不会在一个回传就实现将最后一个状态的信息传递到之前的每一个节点。这是一个很极端的例子,agent对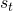 的价值评估,完全取决于
的价值评估,完全取决于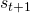 ,在一次更新中,信息只会向前传递一步。根据动态规划,如果只有这一条trajectory是可能的,这个传递的总时间就是这条trajectory的长度。当可能出现trajectory超过一条时,就需要根据出现的概率来取期望。
,在一次更新中,信息只会向前传递一步。根据动态规划,如果只有这一条trajectory是可能的,这个传递的总时间就是这条trajectory的长度。当可能出现trajectory超过一条时,就需要根据出现的概率来取期望。
像(1)这种动态规划的局部信息传递带来的风险就是,当将来某些状态的价值评估出现偏差时,它过去的状态的价值评估也会出现问题。而这个偏差只能通过更多次的动态规划来修复。
当一个任务趋向于复杂,状态空间的维度越来越高时,上面说到的将来状态价值评估的偏差基本不可避免,TD learning的收敛时间大大增加。
经典的强化学习领域中有很多方法尝试解决这个问题。比如放弃TD直接通过蒙特卡洛(Monte Carlo,MC )采样来做价值评估。此外,也可以通过eligibility trace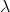
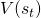 出现偏差的风险被将来更多的
出现偏差的风险被将来更多的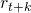 分摊。这里我们不继续发散,感兴趣的读者可以查阅Sutton的textbook[6]。
分摊。这里我们不继续发散,感兴趣的读者可以查阅Sutton的textbook[6]。
1.3 延迟奖励中的贡献分配
在1.1中,我们介绍到,NAS是一个完全延时奖励的任务。运用我们在1.2中介绍的数学模型,我们可以把这个发现表达为:
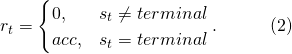
当我们把(2)代入(1)之中,我们会发现,基于TD Learning的价值评估,在TD learning的早期,当正确的贡献分配还没有从最终网络结构状态传到决定浅层网络的动作时,因为环境本身没有反馈给这一步的得分,浅层网络被分配到的贡献接近于0,这是一个天然的偏差。当然,如1.2中介绍,这个偏差也可以通过设计各种方式结合Monte Carlo的预测来弥补,但是完全延迟奖励对于MC方法来说又会带来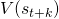
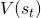 的收敛。
的收敛。
对于延迟奖励,RUDDER[7]经过一系列严格的证明,得到了如下结论:
1)延迟奖励会指数级延长TD的收敛需要的更新次数;
2)延迟奖励会给指数级多的状态的MC价值评估带来抖动。
他们提出的解决方式是用一个神经网络来拟合每条trajectory的总得分,并通过这个神经网络里的梯度回传来将得分分配到输入层的所有状态中,绕过TD和MC。我们继续回到搭建CNN的例子,如果要实现这个方法,就需要构建一个新的神经网络,它的输入是表达网络结构的编码(encoding),输出是预测的该网络结构的精度。
在[7]的实验中,这种通过额外训练一个可微分的总得分函数来分配贡献的方法,表现出了非常明显的收敛速度提升,如图4。然而,这个额外的神经网络需要额外的数据和额外的训练,而且它能否收敛到真实的总得分并没有保证。更重要的是,这个神经网络回传的梯度分配的贡献是否合理,在普通延迟奖励的任务中只能有一个现象级的评估,可解释性有限。
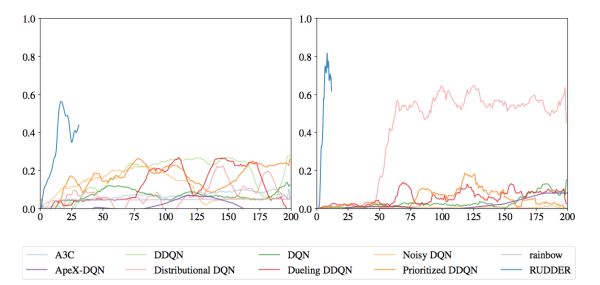
图4: 在延时奖励的游戏Bowling和Venture中,基于微分的贡献分配方法RUDDER收敛速度明显快于基于TD和MC的方法,图片来自 [7]
2. 方法
2.1 重新建模NAS
本文作者的第一条关键insight是,当我们用损失函数(loss function)来替代准确率,不需要像RUDDER一样额外拟合一个得分函数,NAS问题的总得分就已经不是一个来自环境的常数而是一个可微函数了。基于1.3的介绍,这很可能大幅提高NAS的搜索效率。又因为损失函数和准确率都可以表达一个网络学习的结果,这一替换并没有在本质上改变NAS问题原本的“优化网络结构分布以使得它们的期望性能最好”的目标(objective)。于是我们有
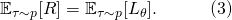
其中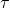 表示的是trajectory,
表示的是trajectory, 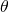 是网络参数,或者更具体的说是所有可能神经变换的参数。
是网络参数,或者更具体的说是所有可能神经变换的参数。
而第二条insight来自于我们在1.1中介绍的,NAS任务的状态转移是确定的。在确定性的环境中,一条状态动作序列出现的概率可以表达为策略函数概率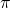 的连乘
的连乘
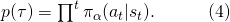
将(3)和(4)结合起来看,我们发现
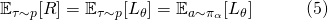
这是一个非常常见的生成式模型(generative model)的目标函数。因而我们可以使用生成式模型中的一些方法,重新表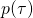 . 比如将
. 比如将 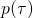 建模成一个fully factorizable的分布
建模成一个fully factorizable的分布
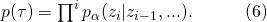
如果我们假设每一次动作是相互独立的,这个分解可以写成
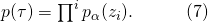
其中,为了与MDP的建模区分开,我们用决策 来替换动作
来替换动作 。将(6)或者(7)带入(5)中,我们得到了一个新的目标函数
。将(6)或者(7)带入(5)中,我们得到了一个新的目标函数
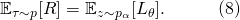
2.2 用随机神经网络表达NAS任务
在经典的基于强化学习的NAS方法中,agent的损失函数和网络本身的损失函数并不连通:
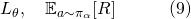
因而他们的计算图也不需要连通。图五展示了一个基于强化学习的NAS中agent和网络交互前向(forward)及各自后向(backward)更新的过程。

图5: 基于强化学习的NAS的前向和后向,网络结构策略的后向需要利用TD来做贡献分配,收敛速度不能保证,资源消耗大
与(9)不同的是,在本文作者重新建模的目标函数(8)中,表达网络结构分布的参数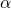 和网络变换的参数
和网络变换的参数 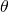 被统一在了一起,这就为一次后向同时更新
被统一在了一起,这就为一次后向同时更新 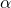 和
和 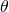 提供了可能,也就是说有可能实现在更新
提供了可能,也就是说有可能实现在更新 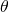 的同时将可微的总得分分配到每一条边的决策上。然而,要达到这个目的,我们首先需要将网络结构分布
的同时将可微的总得分分配到每一条边的决策上。然而,要达到这个目的,我们首先需要将网络结构分布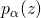 构建进神经网络的计算图里,以在一次前向中实现对子网络结构的采样。
构建进神经网络的计算图里,以在一次前向中实现对子网络结构的采样。
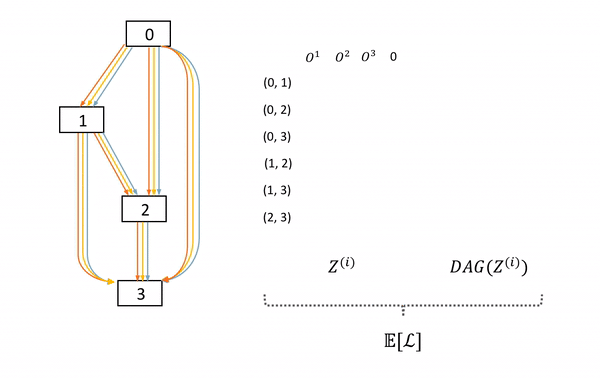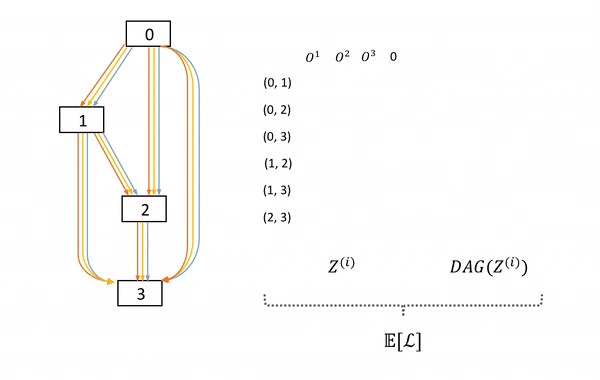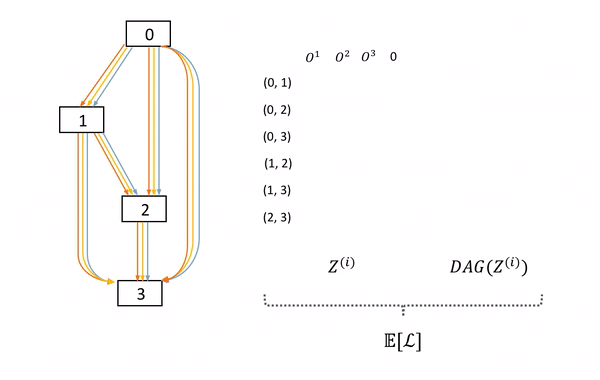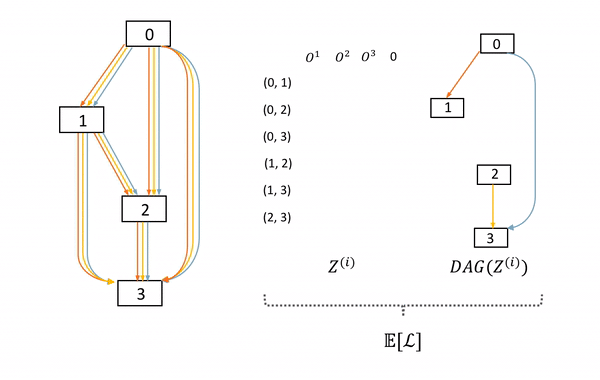
图6: SNAS中子网络的采样及前向过程。左边DAG为母网络,中间的矩阵表示每次在母网络每条边上采样的决策z,右边为这次采样的子网络。
本文作者提出,这一采样过程可以通过将网络结构分布融合到母网络以形成随机神经网络(Stochastic Neural Network, SNN)来实现。具体来说,从母网络中产生子网络,可以通过在母网络的每一条边的所有可能神经变换的结果后乘上一个one-hot向量来实现。而对于子网络的采样,就因此自然转化为了对一系列one-hot随机变量的采样
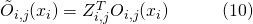
其中表示节点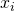
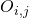
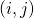 上选择的神经变换(operations),
上选择的神经变换(operations), 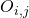 表示在边
表示在边 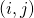 上所有的神经变换,
上所有的神经变换,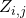 表示在边
表示在边 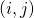 上的one-hot随机变量。图6展示了这种SNN中一个cell的采样方法。
上的one-hot随机变量。图6展示了这种SNN中一个cell的采样方法。
因为SNAS被定位为通用神经网络结构搜索方法,在构建母图时,作者采用了与ENAS及DARTS相同的方法。这体现在:
1)在模块(cell)基本母图中,设计了超过一个输入节点(input node),表示该cell的输入来自于之前哪些模块的输出,因而包含了产生cell之间的skipping和branching的可能;
2)在设计每个cell中的中间节点(intermediate node)的输入时考虑了所有来自cell内所有之前中间节点的输入边(input edge),并在每条输入边上提供的神经变换(operation)中包括了Identity的变换和0的变换,用以表达skip和直接删除这条输入边。因此考虑了所有之间skipping和branching的可能。
将(10)与这种母网络结合,我们可以获得每一个节点的实际数学表达
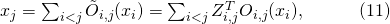
这是一个在之前确定神经层上的一个随机的线性变换。将它考虑进来,我们可以进一步完善SNAS的目标函数
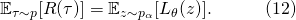
2.3 可微化近似
经过2.1和2.2,我们获得了一个表达NAS任务的随机神经网络,定义了它的损失函数。接下来我们要解决的问题就是,如何计算这个损失函数对网络结构参数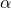
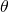 的梯度。
的梯度。
对一个如(12)的目标函数的求导,特别是对期望项的求导,最经典的方法是likelihood ratio trick,它在强化学习中策略梯度(policy gradient)的推导中被使用。然而,这一方法的主要问题是由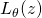 抖动带来的较大的梯度方差(variance),并不利于整个优化过程的收敛。特别是考虑到
抖动带来的较大的梯度方差(variance),并不利于整个优化过程的收敛。特别是考虑到 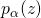 本身的维度比较高(其维度等于所有输入边的总数),如何降低likelihood ratio trick带来的梯度方差本身就仍然是一个未解决的问题(open question)。
本身的维度比较高(其维度等于所有输入边的总数),如何降低likelihood ratio trick带来的梯度方差本身就仍然是一个未解决的问题(open question)。
在这里,作者选择了另一种可微化近似方法,重参数法(reparameterization)。这是一种在当前深度生成式模型(Deep Generative Model)中被验证有效的方法。具体来说,在实现一个离散分布时,有一种方法是先采样与该one-hot vector维度相同数量的连续均匀分布(uniform distribution)的随机变量,将他们经过Gumbel变换转为Gumbel随机变量,并从中选择最大的那一维度(argmax)取为1,其他维度为0。这个变换被称为Gumbel-max。这样采样的随机变量的分布与该离散分布相同,而离散分布的参数也就转化为了Gumbel max中的参数,实现了对该离散分布的重参数化。
但是因为argmax这个操作本身不可微,[8,9]提出将max近似为softmax,
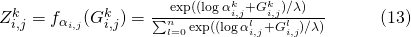
他们同时证明了当softmax的温度(temperature)趋近于0时,该方法产生的随机变量趋近于该离散分布。 作者在论文中给出了近似后的损失函数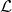
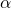

图7: SNAS中的前向和后向,通过构建随机神经网络和可微化近似,保证了前向的采样能够估计NAS的优化目标,后向可以将梯度回传到网络结构分布的参数上,因此无偏而高效。
2.4 网络正向时延惩罚与网络稀疏化
除了从开始就一直提的搜索效率问题之外,经典的NAS方法还有一个更加实际的问题,就是设计出的网络往往为了追求精度而过于复杂。具体体现在agent最终学会搭建一个有复杂拓扑结构的网络,这导致在训练中需要消耗比较多的时间,就算是在实际的使用中,网络前向的时延也非常长。
本文作者的第三条insight是,agent对于这些复杂网络的偏好,一方面来自于在优化目标中并没有一个对于前向时延的限制,另一方面来自于在最终网络的选取中依然有不在优化目标中的人工操作(如在DARTS中,每个中间节点强制要求选择top-2权重的输入边上的top-1权重的非0神经变换),因此在整个网络结构搜索的过程中并不能自动实现网络的稀疏化,也就是说有一些搜索空间在最后被放弃了。
鉴于在2.2中介绍到的母网络的设计中实际已经包含了直接删除某条输入边的可能,本文作者尝试从补充优化目标入手,以期达到不需要在子网络的选取中加入人工就能自动获得稀疏网络的目的。这个目的被建模为“在给定的网络正向时延预算下优化网络准确率”的问题
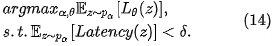
通过拉格朗日变换(Lagrangian transformation),我们可以将(14)转化为对网络正向时延的惩罚
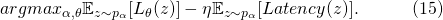
其中,如果每个网络的正向时延可以在具体部署的硬件上测得,对于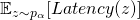
这些量值包括参数量、浮点计算数(FLOPs)以及需要的内存。使用这些量的一大优势在于,采样出的子网络的这些值的总量计算是与(11)一样是一个对于各个备选神经变换的一些常量(如长、宽、通道数)的随机线性变换。与(11)相似,我们有
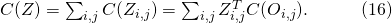
因而相较于在每一条输入边上优化一个全局的网络正向时延,我们只需要优化每条边上自己对时延的贡献量。如果回到之前贡献分配的语境,全局的时延惩罚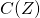 被线性分配到了每一条边的决策
被线性分配到了每一条边的决策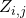 上,这有利于提高收敛效率。又因为(16)是一个线性的变换,我们既可以用重参数化计算
上,这有利于提高收敛效率。又因为(16)是一个线性的变换,我们既可以用重参数化计算 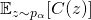 的期望,也可以用策略梯度的方法。
的期望,也可以用策略梯度的方法。
3. 深度探究
3.1 SNAS中的贡献分配
在之前的介绍中,虽然在2.1中提到了SNAS中使用了得分的可微性可以解决1.3中提到的在NAS这个完全延时奖励任务中TD Learning可能会遇到的问题,这种得分分配仍然是一个黑盒。为了提高方法的可解释性,作者通过数学推导,证明了SNAS中用来更新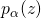 的梯度
的梯度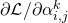 的期望在策略梯度中的等价形式,每一条输入边
的期望在策略梯度中的等价形式,每一条输入边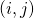 上的决策
上的决策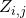 被分配到的得分为
被分配到的得分为
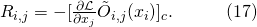
比较明显的是,这个得分可以被解释为一个对于得分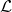 的一阶泰勒展开(Taylor Decomposition)。对于cell中的某一个节点
的一阶泰勒展开(Taylor Decomposition)。对于cell中的某一个节点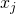 ,它会聚集所有从输出边回传的贡献
,它会聚集所有从输出边回传的贡献 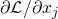 ,并把它按照的权重分配到它的所有输入边
,并把它按照的权重分配到它的所有输入边 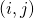 。又由(10)我们知道,分配在
。又由(10)我们知道,分配在 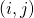 上的贡献会根据随机变量
上的贡献会根据随机变量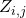 来进行分配,当
来进行分配,当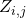 无限趋近于one-hot时,贡献会完全被分配到被选择的那个神经变换。
无限趋近于one-hot时,贡献会完全被分配到被选择的那个神经变换。
这种基于一阶泰勒展开的贡献分配,在[12]中被用来解释神经网络中每个神经元的重要性,是目前比较被接受的解释神经网络中不同模块重要性的方法。
在1.2中,我们介绍了MDP建模中,在搜索早期TD Learning因为价值评估还没来得及回传到浅层的动作,它们被分配的贡献并不合理。在1.3中,我们介绍到虽然这个不合理最终可以被修正,整个修正的过程却需要比较长的时间。而SNAS中的贡献分配从最开始就是合理的,而且每一步都是合理的,因而幸运的避开了这项时间成本。
这可以从一定程度上解释为什么SNAS的搜索比基于强化学习的搜索收敛快。与1.3中提到的RUDDER相比,SNAS利用了NAS任务的特殊性,搭建了一张连通网络结构分布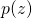 和任务环境也就是网络结构的计算图,使得总得分函数天然可微,而且贡献分配合理可解释。
和任务环境也就是网络结构的计算图,使得总得分函数天然可微,而且贡献分配合理可解释。
当与2.4中提到的网络正向时延向结合时,(17)中提到的得分会有一个惩罚项的补充,而这个惩罚项因为2.4中介绍的(16)的线性可分性同样可以解释为一种一阶泰勒展开。
3.2 SNAS与DARTS的关系
在SNAS之前,Liu et al. 提出了一种可微分的神经网络结构搜索,DARTS。不同于SNAS中通过完整的概率建模来提出新方法,DARTS将网络结构直接近似为确定性的连续权重,类似于注意力机制(attention)。在搜索过程中,表达这个softmax连续权重的参数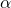 与网络神经变换的参数
与网络神经变换的参数 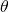 同时被更新,完全收敛之后选择
同时被更新,完全收敛之后选择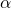 的argmax搭建子网络,再重新训练
的argmax搭建子网络,再重新训练 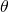 。
。

图8: DARTS中的前向和后向,因为并没有子网络采样的过程,优化的损失函数并不是NAS的目标函数
因为SNAS直接优化NAS的目标,作者从SNAS的建模出发,对DARTS的这一近似作出了概率建模下的解释:这种连续化的近似可以被理解为是将(12)中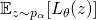 的全局期望
的全局期望
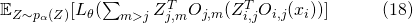 直接分解到每一条输入边上,计算了一个解析的期望
直接分解到每一条输入边上,计算了一个解析的期望
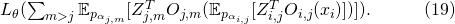
如果说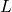 对于每一个
对于每一个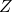 都是线性的,(19)与(18)就是等价的。但是因为设计了 ReLU-Conv-BN 的堆叠,带来了非线性,这两个目标并不等价。
都是线性的,(19)与(18)就是等价的。但是因为设计了 ReLU-Conv-BN 的堆叠,带来了非线性,这两个目标并不等价。
也就是说,在DARTS的连续化近似中带来了很大的偏差(bias)。这一方面带来了最终优化的结果并没有理论保证的问题,使得一阶优化(single-level optimization)的结果不尽人意;另一方面因为连续化近似并没有趋向离散的限制,最终通过删除较低权重的边和神经变换产生的子网络将无法保持训练时整个母网络的精度。
Liu et al. 提出用二阶优化(bi-level optimization)通过基于梯度的元学习(gradient-based meta learning)来解决第一个问题,但是对于第二个问题,并没有给出一个自动化的解法,而是人工定义了一些规则来挑选边和神经变换,构建子网络,再重新训练。
4. 实验
4.1 CIFAR-10上的搜索效率
从ENAS开始,在极致压缩搜索资源成本的方向上,比较常见的方法是先搜索少量的cell,再把它们堆叠起来,重新训练。为了和现有的通用NAS方法进行公平的对比,本文作者也采用了相同的方法,在一张GPU上针对CIFAR-10任务搜索cell结构。
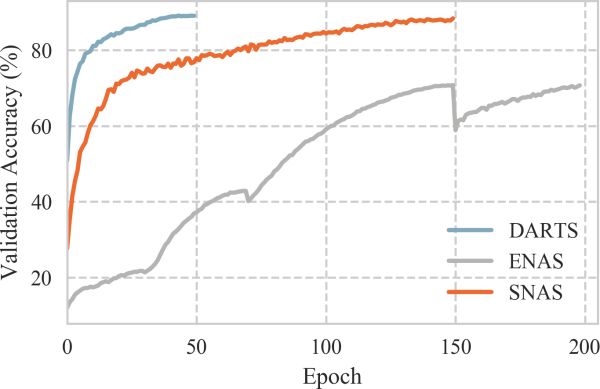
图9: SNAS, ENAS和DARTS在搜索中的validation accuracy随着训练epoch数的变化
图9展示了整个搜索过程中SNAS、ENAS和DARTS的测试准确率随着epoch数的变化。可以看到的是SNAS如作者理论预言的一样,收敛速度明显快于ENAS,而且最后收敛的准确率也远远高于ENAS。虽然从这张图里看起来DARTS的收敛速度快于SNAS,而且二者的收敛精度相似,但是这个准确率是整张母图的准确率,基于3.2中的分析,它并不能反应最终子网络的性能。
4.2 搜索结束直接产生子网络
为了直观表现3.2中提到的第二个问题,即DARTS最终获得的子网络并不能直接使用而一定需要参数的重新训练,并检测作者对于SNAS可以避免这个问题的理论预言,作者提供了上图搜索结束之后DARTS和SNAS按照各自的方式产生子网络的准确率。

图10: SNAS与DARTS在搜索收敛时的准确率和直接产生子网络的准确率对比
从图10可以看到,SNAS中产生的子网络可以保持搜索时的测试集准确率,而DARTS的结果并不能。Liu et al. 提出的解决方案是,重新训练子网络100个epoch。当把这部分时间同样算进去,再外加上DARTS没有最优的保证可能需要训练多个网络再进行选择,(如原文中Liu et al. 搜索了十次选择其中最好的,)SNAS的实际搜索效率远高于DARTS。
同时,在构建子网络的过程中,作者发现,同样训练150个epoch,SNAS的网络结构分布,相对于DARTS中的softmax,对每条边上的决策更加确定。图11展示了这两个分布的信息熵(entropy)的对比,SNAS的熵小于DARTS。
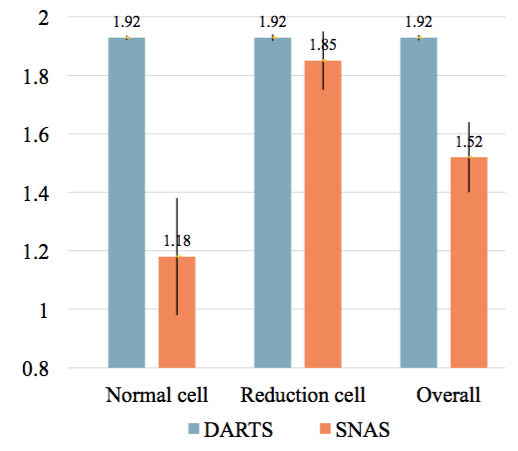
图11: SNAS与DARTS搜索收敛后网络结构分布的信息熵
4.3 搜索过程中的网络演化
在2.4中介绍到,除了重新建模NAS问题,SNAS的另一项创新点在于通过优化网络正向时延惩罚来自动实现网络稀疏化,避免搜索出正向时延过长的网络。在ENAS和DARTS中,最终的网络都是通过人工规则来挑选每个节点上的两条输入边的,在这个规则下的演化过程主要就是对每条边上神经变换的替换。而SNAS有可能在搜索过程中就出现网络本身拓扑结构的演化。
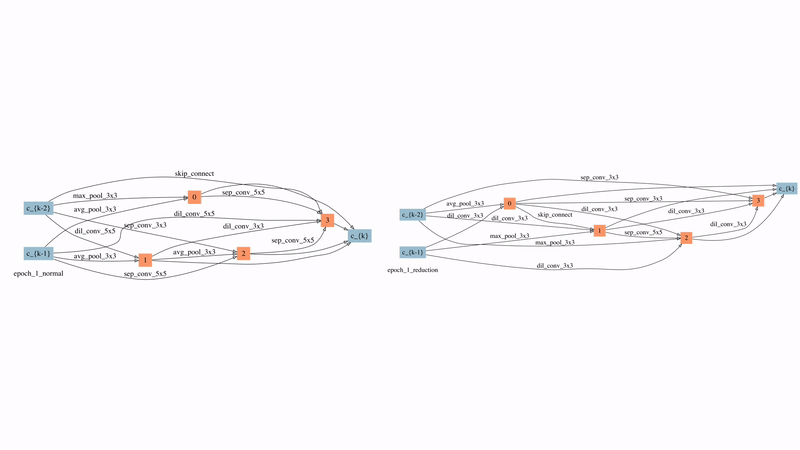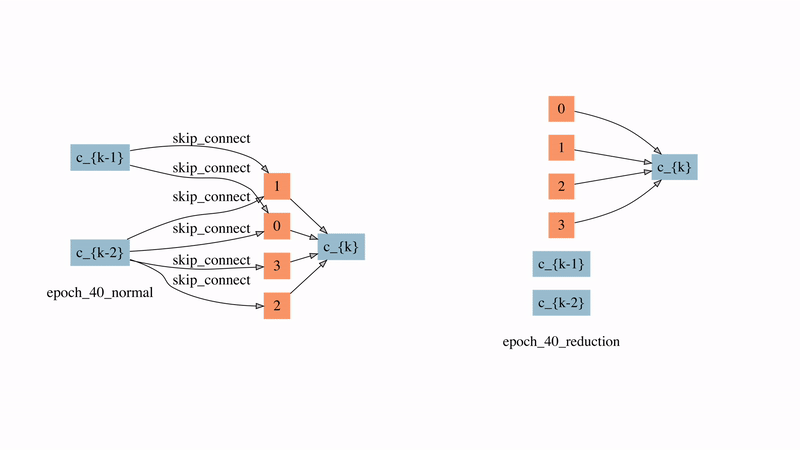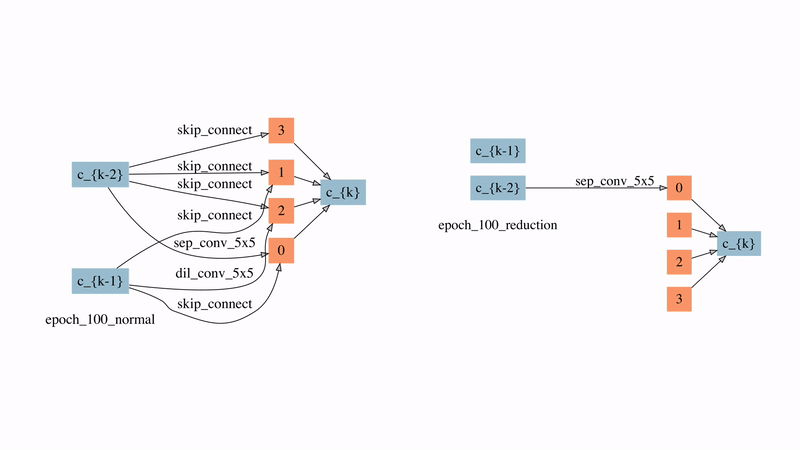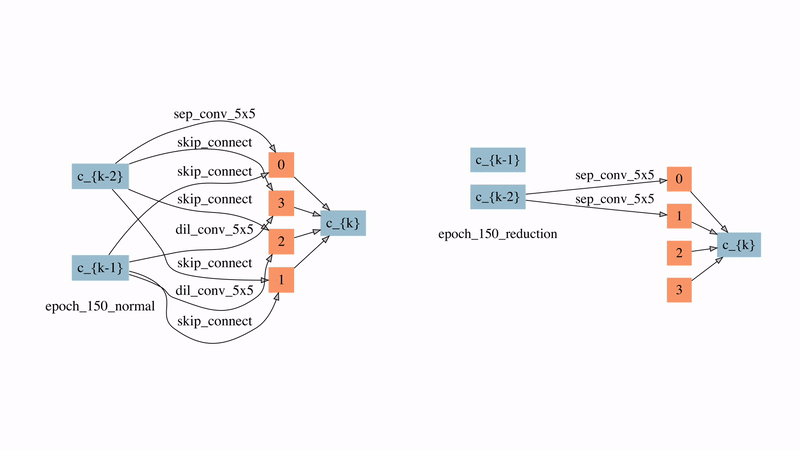
图12: 在较强时延惩罚下的normal cell和reduction cell的演化过程
图12展示了SNAS在较强延时惩罚下的normal cell和reduction cell的演化过程。可以看到的是,在搜索的非常早期,大部分的边就因此被自动删除了。有两点比较有意思的观察:
1)来自于蓝色节点即输入节点的边在reduction cell中直到80个epoch之后才出现,这意味着在前80个epoch中reduction cell都是被跳过的,直到需要时它才被引入。
2)在normal cell中最后学习的结果是自动产生了每个节点有且仅有两条输入边的拓扑结构,这说明ENAS和DARTS中做top-2的选择有一定的合理性。但在reduction cell中最后的结果是有一半的节点没有被使用,这对之前人工设计的子网络生成规则提出了挑战。
4.4 不同程度延时惩罚的影响
作者在实验中尝试了三种不同程度的时延惩罚:
1)较弱时延惩罚是一个时延惩罚的边界值,由它搜出的网络会出现边的自动删除,搜索结果如图13。当时延惩罚小于这个值时,时延惩罚更多的体现在对每条边上的简单神经操作的偏好上。
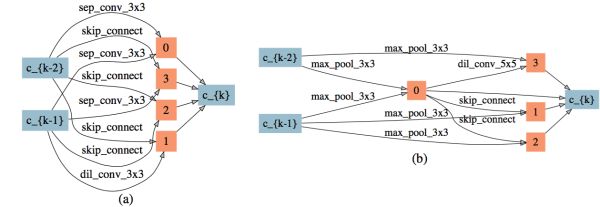
图13: 较弱时延惩罚下搜索出的网络结构,(a): normal cell,(b): reduction cell
2)中等时延惩罚与较弱时延惩罚相比降低了网络的深度和网络参数量,并且带来了更高的准确率(见4.5章),表现出了一定的正则效果。搜索结果如图14。
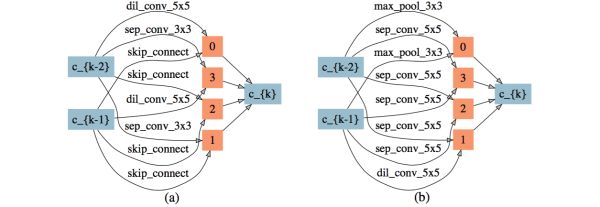
图14: 中等延时惩罚下搜索出的网络结构,(a): normal cell,(b): reduction cell
3)较强时延惩罚下可以直接删除中间节点,搜索结果如图15。可以看到节点2、3的输入边被完全删除。同时,因为输入节点 k-1 无输出边,整个cell的拓扑结构被大大简化。
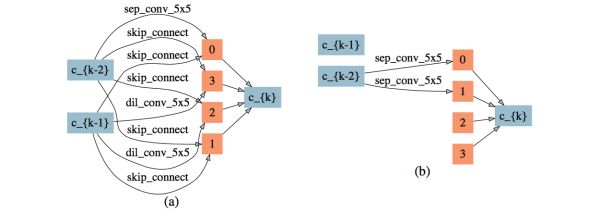
图15: 较强延时惩罚下搜索出的网络结构,(a): normal cell,(b): reduction cell
4.5 CIFAR-10搜得结果网络的评估
与DARTS相同,作者将SNAS搜得的cell堆叠起来,在CIFAR-10上重新训练参数,获得了state-of-the-art的精度,如图16所示。
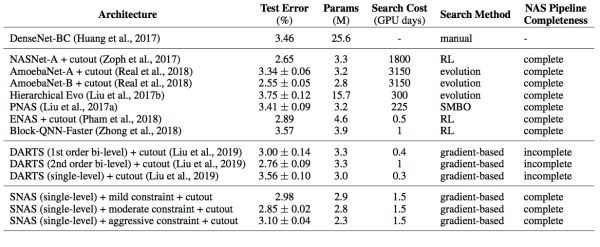
图16: SNAS搜得的cell与其他NAS方法及人工设计结构在CIFAR上的对比
值得注意的是,一阶优化的DARTS的结果并不如不优化网络结构分布产生完全均匀分布产生的结果,而一阶优化的SNAS达到了DARTS二阶优化获得的准确率。而且因为前向时延惩罚的加入,SNAS搜得的网络在参数量上小于其他网络,却获得了相近的准确率。特别是在中等时延惩罚下,SNAS的子网络在使用更少参数的情况下准确率超过了较弱时延惩罚获得的网络,表现出了时延惩罚的正则效果。
4.6 CIFAR-10搜得结果网络对ImageNet的拓展
与DARTS相同,作者提供了将SNAS搜得的cel拓展到tiny ImageNet上获得的结果,如图17所示。尽管使用更少的参数量和FLOPs,子网络可以达到state-of-the-art的准确率。
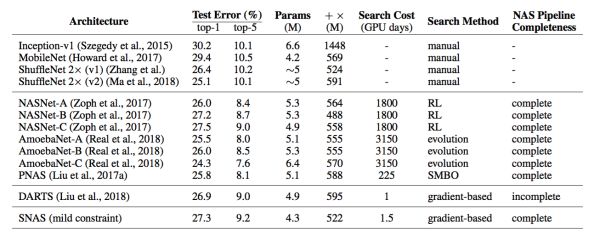
图17: SNAS搜得的cell与其他NAS方法及人工设计结构在ImageNet上的对比
5. 结语
随机神经网络结构搜索(SNAS)是一种高效率、低偏差、自动化程度高的神经网络结构搜索(NAS)框架。作者通过对NAS进行重新建模,从理论上绕过了基于强化学习的方法在完全延迟奖励中收敛速度慢的问题,直接通过梯度优化NAS的目标函数,保证了结果网络的网络参数可以直接使用。
相较于其他NAS方法中根据一定规则产生子网络的方式,作者提出了一套更加自动的网络拓扑结构演化方法,在优化网络准确率的同时,限制了网络结构的复杂度和前向时延。相信随着这一研究的不断深入,我们会看到更多SNAS在大数据集、大网络以及其他任务中的发展。
-
神经网络
+关注
关注
42文章
4775浏览量
100918 -
机器学习
+关注
关注
66文章
8428浏览量
132807 -
强化学习
+关注
关注
4文章
268浏览量
11272
原文标题:一文详解随机神经网络结构搜索 (SNAS)
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

什么是深度强化学习?深度强化学习算法应用分析

将深度学习和强化学习相结合的深度强化学习DRL
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

用PopArt进行多任务深度强化学习
强化学习在智能对话上的应用介绍
机器学习中的无模型强化学习算法及研究综述

NeurIPS 2023 | 扩散模型解决多任务强化学习问题

通过强化学习策略进行特征选择






 工商网监
工商网监
评论