 揭秘星际2人工智能AlphaStar:DeepMind科学家回应一切
揭秘星际2人工智能AlphaStar:DeepMind科学家回应一切
25 日凌晨,人工智能 AlphaStar 与职业玩家 MaNa 进行了一场史无前例的「人机大战」:虽然之前在内部比赛中 AI 十战十胜,但现场比赛中,MaNa 机智地戏耍了对手,为人类取得了一场胜利。赛后,DeepMind 科学家、AlphaStar 项目的领导者 Oriol Vinyals 和 David Silver 在 Reddit 上回答了人们关心的很多问题。与此同时,曾与人工智能交手的两位职业玩家,Liquid 战队的 TLO 与 MaNa 也作为嘉宾回答了一些有趣的问题。
例如:对于 AI 研究者来说,打星际 2 的能力是不是应该写进简历里?
网友 NexYY:我应该把会打星际争霸 2 作为一项技能写在简历里证明我是一个有抱负的 AI 开发者吗?有时我沉迷于打星际,而不是提高写代码的能力,我常常因此感到迷茫……
Oriol Vinyals:在比赛那天我打了好多盘星际,我得说这是非常好的体验——特别是考虑到它塑造了我在人工智能、学习计算机科学等方面的动力。所以如果你想完成一个好简历,请把星际争霸 2 当做一个爱好写进去,祝你好运!
1 月 25 日,AlphaStar 与 MaNa 的人机大战,以及此前对战的一些精彩镜头。现场比赛从 10:30 开始。
问:从 pysc2 的早期版本(和目前的 master 版本)来看,似乎 DeepMind 开发的方法是基于对人类游戏过程的完全模仿,如 bot 无法获得屏幕视角外任何东西的信息。而这个版本似乎放开了这些限制,因为要素图层现在是「全地图大小」,而且添加了新的要素。是这样吗?如果是,那这与从 API 中获取原始数据并将其简单抽象成结构化数据来作为神经网络的输入有什么真正的不同呢?DeepMind 博客中甚至表明,直接将原始数据和属性以列表形式的数据输入神经网络,这似乎表明你们不再真正使用要素图层了?
Oriol Vinyals:事实上,有了基于镜头的(和不基于镜头的)输入界面,智能体知道已经构建了什么,因为我们将其作为列表(由神经网络 Transformer 进一步处理)输入。一般来说,即使你没有那种列表,智能体也会知道已经构建了什么,因为智能体的记忆会跟踪所有之前发生的动作,以及过去访问的所有视图的位置。
问:当我使用 pysc2 时,我发现要了解已经构建、正在进行、已经完成的事物是一件非常困难的事,因为我必须一直平移相机视图来获取这些信息。camera_interface 方法是如何保存这些信息的?即使在 camera_interface 模式下,通过原始数据访问(如 unitTypeID、建筑物等的计数),大量数据仍是完全可用的?
Oriol Vinyals:是的,我们的确放开了智能体的视角,主要是因为算力原因——没有屏幕移动的游戏大约会有 1000 步,而有屏幕移动的游戏步数会是前者的 2-3 倍。我们的确为迷你地图使用了要素图层,但是对于屏幕,你可以认为要素列表「转换」了那些信息。实际上,事实证明,即使是在处理图像上,将每个像素单独作为一个列表效果也很好!
问:达到当前水平需要玩多少把游戏?换句话说,在你们的案例中,200 年游戏时间一共打了多少把游戏?
Oriol Vinyals:如果平均每场比赛持续 10 分钟,这相当于大约 1000 万场比赛。不过请注意,并不是所有智能体的训练时间都相当于 200 年的游戏时间,这只是接受训练最多的智能体的训练量。
问:所学知识迁移到其它地图效果如何?Oriol 在 discord 上提到它在其它地图上「有效」。我们都很好奇在哪个地图上最有效,所以现在可以揭露答案吗?根据我的个人观察,AlphaStar 似乎很大程度依赖于记忆中的地图信息。它有可能在没见过的地图上执行很好的 wall-off 或 proxy cheese 吗?在全新地图上玩时,MMR 的估计差异是什么?
Oriol Vinyals:参考以上答案。
David Silver(图中黑衣者)与 Oriol Vinyals 在线回答人们有关 AlphaStar 的问题。
问:智能体对「save money for X」这个概念了解得怎么样?这不是一个小问题,因为如果你们从回放中学习,并考虑玩家的无作为行动(NOOP),强化学习算法通常会认为 NOOP 是在游戏中非理想点时的最佳决策。所以你们怎么处理「save money for X」,以及在学习阶段是否排除了 NOOP?
David Silver:实际上,作为其行动的一部分,AlphaStar 会提前选择执行多少 NOOP。最开始这是从监督数据中学到的,以便反映人类游戏玩法,也就是说 AlphaStar 通常以人类玩家相似的速度「点击」。然后通过强化学习来完善,选择减少或增加 NOOP 次数。所以,「save money for X」可以通过提前决定实施几个 NOOP 来轻松实现。
问:你们最终使用的步长是多少?在博客中你们写道,星际的每帧视频被用作输入的一步。然而,你们也提到过平均处理时长是 50 毫秒,而这会超过实际时间(给定 22.4fps,需要<46 毫秒)。所以你们是否要求每 1 步,或每 2 步、3 步是动态的?
Oriol Vinyals:我们要求每一步是动态的,但由于延迟,该操作将仅在某一步结束后处理(即我们是异步操作)。另一个选择是锁定该步,但这样会造成玩家的游戏体验不佳。
问:APM 是怎么回事?我印象中 SC2 LE 被强行限制在 180 WPM,但是我看你们的比赛中,AS 的平均 APM 似乎在很长一段时间内都远远超过这个水平。DeepMind 的博客上展示了相关图表和数字,但没有解释为什么 APM 如此之高。
Oriol Vinyals:这个问题问得好,这也是我们打算解释的。我们咨询了 TLO 和暴雪关于 APM 的意见,并对其增加了一个硬性限制。具体来说,我们在 5 秒内设置 APM 最大为 600,15 秒内为 400,30 秒内为 320,60 秒内为 300。如果智能体在此期间发出了更多动作,我们会删除/忽略那些动作。这些值取自人类玩家的统计数据。暴雪在其 APM 计算中对某些动作进行了多次计算(前面提到的数字是指 pysc2 中「智能体的动作」)。同时,我们的智能体还使用模仿学习,这意味着我们经常看到一些非常「垃圾」的动作。也就是说,并非所有动作都是有效动作。有些人已经在 Reddit 上指出了这一点——AlphaStar 的有效 APM(或 EPM)相当低。我们很高兴能够听到社区的反馈,因为我们只咨询了少数人。我们将考虑所有的反馈。
问:PBT 中需要多少不同的智能体来保持足够的多样性以防止灾难性遗忘?这是如何随着智能体数量的增加而扩展的?还是只需要几个智能体就能保持稳健性?这与历史 checkpoint 的有效通常策略有什么可比性吗?
David Silver:我们保留了每个智能体的旧版本作为 AlphaStar 联赛的竞争对手。当前的智能体通常根据对手的胜率与这些竞争者比赛。这样能够很好地防止灾难性遗忘,因为智能体必须一直打败所有以前的版本。我们也尝试了一些其他的多智能体学习策略,发现这个方法非常稳健。此外,增加 AlphaStar 联赛的多样性非常重要。关于扩展我们很难给出精确的数字,但根据我们的经验,丰富联赛的策略空间有助于使终版的智能体更加强大。
问:从 TPU 和 CPU 的角度来看,总计算时间是怎样的?
David Silver:为了训练 AlphaStar,我们用谷歌的 TPU v3 构建了一个高度可扩展的分布式训练系统,该系统支持很多智能体从星际 II 的数千个并行示例中学习。AlphaStar 联赛运行了 14 天,每个智能体使用 16 个 TPU。最终的 AlphaStar 智能体由发现的最有效策略组成,然后在单个桌面 GPU 上运行。
问:看起来 AI 的反应速度不太稳定。神经网络是在 GPU 上以 50 毫秒或者 350 毫秒运行吗?还是说这些是指不同的东西(前向传递 VS 行动限制)?
David Silver:神经网络本身大概要花 50 毫秒来计算一个动作,但这只是游戏事件发生和 AlphaStar 对该事件做出反应期间的部分处理过程。首先,AlphaStar 平均每 250 毫秒才观察一次游戏,这是因为神经网络除了本身的动作(有时被称为时间抽象动作)之外,还会等待一些其他的游戏动作。观察结果必须从星际争霸 2 传到 AlphaStar,然后再将 AlphaStar 的动作传回到星际争霸 2,这样除了神经网络选择动作的时间之外,又增加了另外 50 毫秒的延迟时间,导致平均反应时间为 350 毫秒。
问:有做过泛化测试吗?可能这些智能体无法玩其他种族(因为可用的单位/动作完全不同,甚至架构也不尽相同),但它们至少可以泛化至其它地图吧?
Oriol Vinyals:我们的确做了这种测试。我们有 AlphaStar 的内部排行榜,我们没有将该榜单的地图设置为 Catalyst,而是留白了。这意味它会在所有目前的天梯地图上运行。令人惊讶的是,智能体仍然表现很好,虽然没到昨天看到的那种水平。
问:看起来人工智能不擅长打逆风?如果落后的话它就会不知所措,这和 OpenAI 在 Dota2 上的 AI 很相似。这是否是人工智能自我博弈所导致的问题?
David Silver:实际上有很多种不同的学习方法。我们发现单纯的自我博弈经常会陷入特定的策略中,有时也会让人工智能忘记如何击败此前了解的战术。AlphaStar 联赛也是基于让人工智能进行自我博弈的思路,但多个智能体进行动态学习鼓励了与多种战术之间的对抗,并在实践中展现了对抗不寻常战术的更强大实力。
问:在去年 11 月 Blizzcon 访谈中,Vinyals 曾经说过会把星际争霸 2 bot 开放到天梯上,现在还有这样的计划吗?
Oriol Vinyals:非常感谢社区的支持,它会纳入我们的工作中,我们已经把这十场比赛的 Replay 公开,让大家观看。未来如有新计划随时会公开。
问:它如何处理不可见的单位?人类玩家在非常靠近隐身单位时会发现它(注:在星际争霸 2 中,隐身单位在对手的屏幕上显示为类似水波纹的模糊轮廓)。但如果 AI 可以看到的话,那隐身几乎没有什么用。但如果它看不见的话,又会给大规模隐形单位策略带来很大优势,因为观察者必须在场才能看到东西。
Oriol Vinyals:非常有趣的问题。一开始我们忽略了不可见单位的「水波纹」。智能体仍然可以玩,因为你可以制造检测器,这样单位会像往常一样显示出来。但我们后来又增加了一个「shimmer」功能,如果某个位置有隐形装置,这个功能就会激活。
问:从这次经历中,你们是否获得了一些可以用到其他人机交互强化学习任务中的经验?
Oriol Vinyals:当我们看到高 APM 值或点错键这种问题时,我们觉得这些可能是来自模仿。其实,我们经常看到智能体的某些动作出现冗余行为(滥发移动命令、在游戏刚开始时闪烁镜头)。
David Silver:就像星际争霸一样,多数人类与 AI 交互的现实应用都有信息不完全的问题。这就意味着没有真正意义上的最佳行为,智能体必须能够稳健地应对人类可能采取的一系列不可预测的行为。也许从星际争霸中学到的最有用的一点是,我们必须非常谨慎,确保学习算法能够覆盖所有可能出现的状况。另外,我认为我们学到了很多关于如何将 RL 扩展到真正复杂问题中的经验,这些问题都有很大的动作空间和长远的视野。
问:很多人认为 AlphaStar 在最后一局中的失败是因为该算法在最后一场比赛中受到了视力限制。我个人认为这种说法没有说服力,因为折跃棱镜在战争迷雾中进进出出,AI 相应地指挥其部队前进撤退。这看起来绝对像是理解上的差距,而不是操作的局限。AlphaStar 以这种方式落败,对此您有什么看法?
David Silver:很难说清我们为什么输掉(或赢了)某场比赛,因为 AlphaStar 的决策非常复杂,是一个动态多智能体训练进程导致的结果。MaNa 游戏打得很棒,似乎发现并利用了 AlphaStar 的弱点——但很难确定这一弱点究竟是什么造成的:视角?训练时间不够?还是对手和其它智能体不一样?
问:Alphastar 的「记忆」有多大?它在玩游戏时需要接收多少数据?
Oriol Vinyals:每个智能体使用一个深度 LSTM,每个 LSTM 有 3 个层和 384 个单元。AlphaStar 在游戏中每做出一个动作,该记忆就会更新一次。平均每个游戏会有 1000 个动作。我们的网络大约有 7000 万个参数。
问:像 AlphaGo 和 AlphaZero 这样的智能体是使用完美信息游戏进行训练的。对于不完美信息游戏如星际争霸来说,智能体的设计会有什么不同?AlphaStar 是否有之前与人类对决的「记忆」?
David Silver:有趣的是,像 AlphaGo 和 AlphaZero 这样的基于搜索的方法更难适应不完美信息博弈。例如,基于搜索的***算法(比如 DeepStack 和 Libratus)通过信念状态推测对手的手牌。
与之不同的是,AlphaStar 是一种无模型的强化学习算法,可以间接地推理对手状态,即通过学习行为这一最有效击败对手的方法,而不是试图给对手看到什么建模。可以认为,这是应对不完整信息的一个有效方法。
另一方面,不完美信息游戏没有绝对最佳的游戏方式,而是取决于对手的行为。这就是星际争霸如此让人着迷的原因,就像「石头剪刀布」一样,所有决策都有优势劣势。这就是我们使用 AlphaStar 联赛,以及为什么策略空间的所有角落都如此重要的原因——在围棋这样的游戏里这是不重要的,掌握了最优策略就可以击败所有对手。
问:星际争霸 2 之后的下一个里程碑会是什么?
Oriol Vinyals:人工智能还面临着一些重要而令人兴奋的挑战。我最感兴趣的是「元学习(Meta Learning)」,它与更少的数据点和更快速的学习有关。这种思想自然可以应用在星际争霸 2 上——它可以减少训练智能体所需的数据量,也可以让 AI 更好地学习和适应新的对手,而不是「冻结」AlphaStar 的权重。
问:AlphaStar 的技术可以应用到哪些其他科学领域?
Oriol Vinyals:AlphaStar 背后的技术可以应用在很多问题上。它的神经网络架构可以用于超长序列的建模——基于不完美信息,游戏时间可以长达一个小时,而步骤有数万个。星际争霸的每一帧都被算作一步输入,神经网络会在每帧之后预测游戏剩余时间内的预期行动顺序。这样的方式在天气预报、气候建模、语言理解等需要对长序列数据进行复杂预测的领域非常有前景。
我们的一些训练方法也可以用于提高人工智能系统的安全性与鲁棒性,特别是在能源等安全关键领域,这对于解决复杂的前沿问题至关重要。
职业玩家的看法
两位与 AlphaStar 交手的星际争霸 2 职业玩家,TLO 与 MaNa (图中居右)。
问:对于职业玩家来说,你们就像在指导 AlphaStar,在你们看来它在比赛中展现出了哪些优缺点?它获得胜利的方式来自决策还是操作?
MaNa:它最强的地方显然是单位控制。在双方兵力数量相当的情况下,人工智能赢得了所有比赛。在仅有的几场比赛中我们能够看到的缺点是它对于技术的顽固态度。AlphaStar 有信心赢得战术上的胜利,却几乎没有做任何其他事情,最终在现场比赛中也没有获得胜利。我没有看到太多决策的迹象,所以我说人工智能是在靠操作获得胜利。
问:和 AlphaStar 比赛是什么样的体验?如果你不知道对手是谁的话,你能猜出它是机器吗?人工智能的引入会为星际争霸 2 带来哪些变化?
MaNa:与 AlphaStar 比赛过程中我非常紧张,特别因为它是一台机器。在此之前,我对它所知甚少。由于缺乏信息,我不得不以一种不熟悉的方式进行比赛。如果没有被告知对手是谁,我会质疑它是否是人类。它的战术和人类很像,但微操不是任何人类都能实现的。我肯定会发现它不是人类,但可能需要不止一场游戏的信息。我对 AlphaStar 的未来非常期待,我迫不及待地想要和它进行更多游戏。
星际争霸 2 人机大战赛事回顾
昨天是 DeepMind 星际争霸 2 智能体 AlphaStar 首秀。DeepMind 放出了 AlphaStar 去年 12 月与星际争霸 2 职业玩家 LiquidTLO、MaNa 的比赛视频,AlphaStar 均以 5:0 的战绩战胜星际争霸 2 职业玩家。目前,AlphaStar 只能玩神族,不过它依然战胜了神族最强十人之一的 MaNa!
昨天,DeepMind 还组织了一次 MaNa 和 AlphaStar 的现场对决。MaNa 在赛前称,自己要来一场「复仇之战」。事实证明,他成功了。
所有 11 场比赛的 Replay:https://deepmind.com/research/alphastar-resources/
在这场比赛中,我们可以看到 AI 的一个缺陷:除了特定的分兵战术,并没有灵活的兵力分配概念。这让我们想起打星际 1 电脑的远古时代,开局派出一个农民去攻击电脑的基地,电脑就会派出所有农民去一直追杀你这个农民。这场 MaNa 也是利用的相似的办法,棱镜带着两不朽在 AI 的基地不停骚扰,AlphaStar 一旦回防立刻飞走,等 AI 兵力出门又立刻继续骚扰。
开局不久后,AlphaStar 便逐渐占据优势,正面利用追猎者袭扰 MaNa 的二矿,背面则用两个先知不断进犯矿区。人工智能展现的压迫力让场面变得非常紧张。
虽然人工智能在兵力对等的情况下每次都能占到便宜,但人类的偷袭战术逐渐吸引了 AlphaStar 的主要兵力,帮助 MaNa 成功扛过 AI 的正面进攻。随后,MaNa 的大军在对手二矿位置获得了决定性胜利。到了第 12 分钟,人类打爆了 AI 的所有建筑,获得了胜利。
AlphaStar 官方解读
AlphaStar 的行为是由一种深度神经网络生成的,该网络从原数据界面(单位列表与它们的特性)接收输入数据,输出构成游戏内行为的指令序列。具体来说,该神经网络在单元中使用了一个 transformer 作为躯干,结合了一个深度 LSTM 核、一个带有 pointer 网络的自动回归策略 head 以及一个中心价值基线。
AlphaStar 也使用到了全新的多智能体学习算法。神经网络最初通过暴雪公开的匿名人类游戏视频以监督学习进行训练。这让 AlphaStar 能够通过模仿进行学习天梯玩家的基础微操与宏观操作策略。
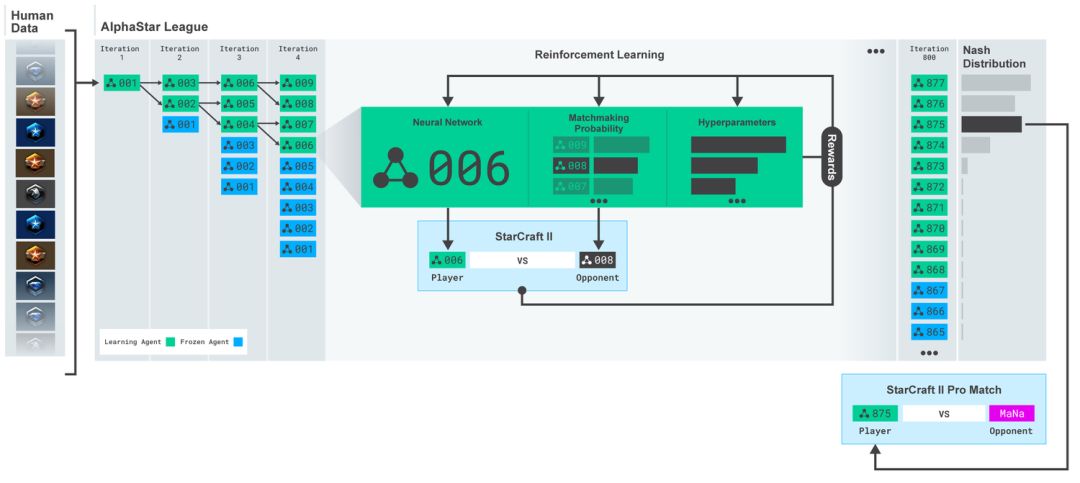
AlphaStar 联盟。最初是通过人类玩家的游戏回放视频进行训练,然后与其他对手对抗训练。每次迭代就匹配新的对手,冻结原来的对手,匹配对手的概率和超参数决定了每个智能体采用的的学习目标函数,保留多样性的同时增加难度。智能体的参数通过强化学习进行更新。最终的智能体采样自联盟的纳什分布(没有更换)。

随着自我博弈的进行,AlphaStar 逐渐开发出了越来越成熟的战术。DeepMind 表示,这一过程和人类玩家发现战术的过程类似:新的战术不断击败旧的战术。
为了训练 AlphaStar,DeepMind 使用了谷歌最先进的深度学习芯片 TPU v3 构建了一个高度可扩展的分布式训练配置,支持数千个对战训练并行运算。AlphaStar 联赛运行了 14 天,每个人工智能体使用 16 块 TPU。在训练时间上,每个智能体相当于训练了人类的 200 年游戏时间。最后成型的 AlphaStar 采用了各个智能体中获胜概率最高战术的组合,并可以在单个 GPU 的计算机上运行。
-
神经网络
+关注
关注
42文章
4771浏览量
100756 -
人工智能
+关注
关注
1791文章
47274浏览量
238449 -
DeepMind
+关注
关注
0文章
130浏览量
10859
原文标题:揭秘星际2人工智能AlphaStar:DeepMind科学家回应一切
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的技术支撑学习心得
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
名单公布!【书籍评测活动NO.44】AI for Science:人工智能驱动科学创新

报名开启!深圳(国际)通用人工智能大会将启幕,国内外大咖齐聚话AI
前OpenAI首席科学家创办新的AI公司
本源量子参与的国家重点研发计划青年科学家项目启动会顺利召开







 工商网监
工商网监
评论