 介绍几个Hive常用的函数吧!
介绍几个Hive常用的函数吧!
咳咳,今天来介绍一下几个Hive函数吧,先放一张我登哥划水的照片,希望大家也做一只自由的鱼儿,在知识的海洋里游呀游,嘻嘻!
今天我们来介绍几个Hive常用的函数吧!
首先我们产生我们的数据,使用spark sql来产生吧:
valdata=Seq[(String,String)](("{"userid":"1","action":"0#222"}","20180131"),("{"userid":"1","action":"1#223"}","20180131"),("{"userid":"1","action":"2#224"}","20180131"),("{"userid":"1","action":"1#225"}","20180131"),("{"userid":"1","action":"2#225"}","20180131"),("{"userid":"1","action":"0#226"}","20180131"),("{"userid":"1","action":"1#227"}","20180131"),("{"userid":"1","action":"2#228"}","20180131"),("{"userid":"2","action":"0#223"}","20180131"),("{"userid":"2","action":"1#224"}","20180131"),("{"userid":"2","action":"1#225"}","20180131"),("{"userid":"2","action":"2#228"}","20180131")).toDF("info","dt").write.saveAsTable("test.sxw_testRowNumber")
为了模拟我们的hive函数,我们特地将info字段写成了一个json格式,info中有两个键值对,一个是user_id,另一个是用户的行为,行为中有两个数据,用#隔开,分别是动作的类型和动作发生的时间。我们可以这样认为,0代表百度首页,1代表进行了一次搜索的搜索结果页,2代表查看搜索结果中国年的某个详情页。从一次动作0 到 下一次动作0,我们可以认为这是用户和百度一次完整的交互,即一次session,从一次动作1到下一次动作1,可以认为是一次完整的搜索操作。另一个字段是dt,即我们的分区字段。
我们用简单的查询语句来看一下我们的数据效果:
select*fromtest.sxw_testRowNumberwheredt=20180131
结果如下:

get_json_object
我们使用get_json_object来解析json格式字符串里面的内容,格式如下:
get_json_object(字段名,'$.key')
这里,我们来解析info中的userid和action:
selectget_json_object(info,'$.userid')asuser_id,get_json_object(info,'$.action')asactionfromtest.sxw_testRowNumberwheredt=20180131
结果如下:

字符串替换函数
字符串替换函数格式如下:
regexp_replace(字段名,被替换的内容,替换为的内容)
这里我们是可以写正则表达式来替换的,比如我们想把#和数字都替换成大写字母Y:
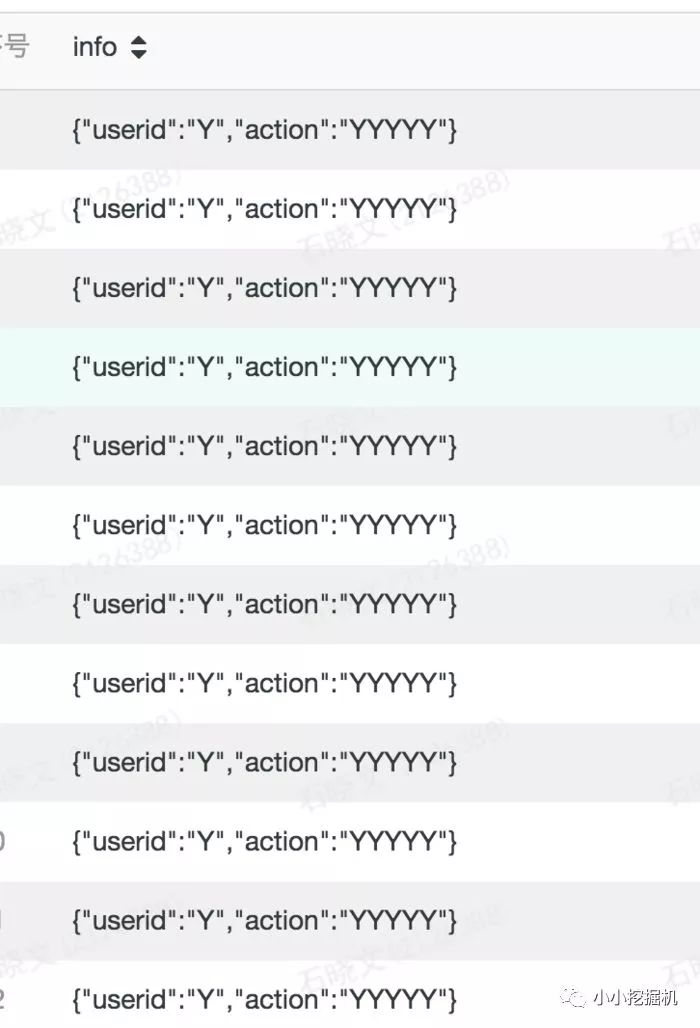
selectregexp_replace(info,'[\d#]','Y')asinfofromtest.sxw_testRowNumberwheredt=20180131
在上面的语句中,我们用了两个,因为这里需要进行转义。结果为:
字符串切分函数
字符串切分函数split,很像我们java、python中写的那样,格式如下:
split(字段名,分割字符)
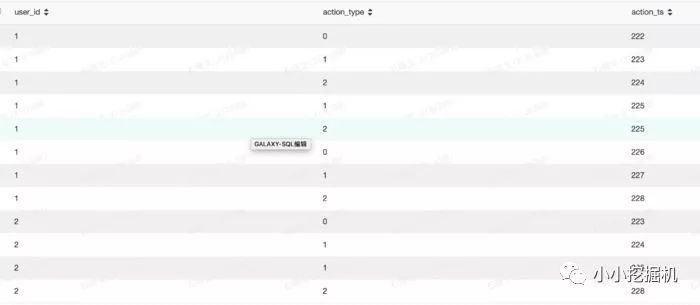
split分割后返回一个数组,我们可以用下标取出每个元素。我们把action里面的动作类型和动作时间使用split分割开,语句如下:
selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131
结果如下:
取字串
取字串使用substring方法,格式如下:
substring(字段名,开始位置,提取长度)
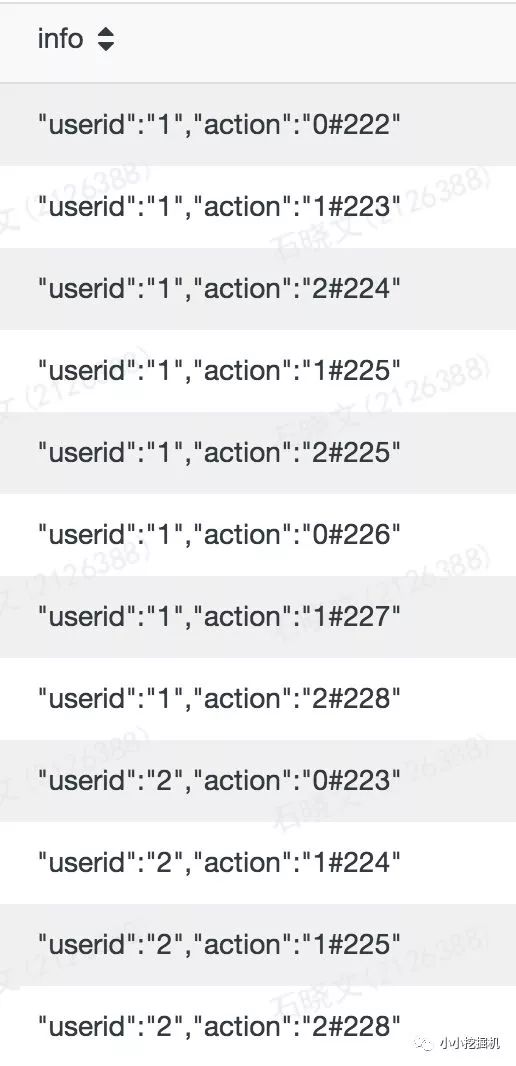
这里,如果我们想吧info中前后的大括号去掉,可以使用substring,语句如下:
selectsubstring(info,2,length(info)-2)asinfofromtest.sxw_testRowNumberwheredt=20180131
你可能会问,为什么开始位置是从2开始的而不是1,因为hive中字符串的索引是从1开始的而不是0,同时,我们谁用length方法来计算字符串的长度,结果如下:
有条件计数
有条件计数使用count函数结合case when then语法来实现,比如我们要计算每个用户有多少个session,语句如下:
selectget_json_object(info,'$.userid')asuser_id,count(casewhensplit(get_json_object(info,'$.action'),'#')[0]=='0'then1elsenullend)assession_countfromtest.sxw_testRowNumberwheredt=20180131groupbyget_json_object(info,'$.userid')
结果如下:

上面的几个函数都只是简单的开胃菜,接下来我们来介绍一下重头戏,分组排序函数以及它的两个衍生的函数,row_number() over的格式如下:
row_Number()OVER(partitionby分组字段ORDERBY排序字段排序方式asc/desc)
简单的说,我们使用partition by后面的字段对数据进行分组,在每个组内,使用ORDER BY后面的字段进行排序,并给每条记录增加一个排序序号。比如,我们根据每个用户每条记录的发生时间对用户的行为进行排序,并添加一个序号:
select*row_number()over(partitionbyuser_idorderbyaction_tsasc)astnfrom(selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131)ast
执行结果如下:
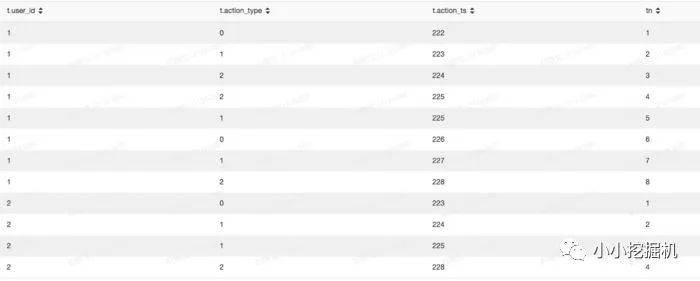
可以看到,我们已经成功给用户的行为添加了发生序号。
除了row_number以外,我们还有两个函数,分别是:
lag(字段名,N)over(partitionby分组字段orderby排序字段排序方式)lead(字段名,N)over(partitionby分组字段orderby排序字段排序方式)lag(字段名,N) over(partition by 分组字段 order by 排序字段 排序方式) lead(字段名,N) over(partition by 分组字段 order by 排序字段 排序方式)
lag括号里理由两个参数,第一个是字段名,第二个是数量N,这里的意思是,取分组排序之后比该条记录序号小N的对应记录的指定字段的值,如果字段名为ts,N为1,就是取分组排序之后上一条记录的ts值。
lead括号里理由两个参数,第一个是字段名,第二个是数量N,这里的意思是,取分组排序之后比该条记录序号大N的对应记录的对应字段的值,如果字段名为ts,N为1,就是取分组排序之后下一条记录的ts值。
比如,我们用lag和lead分别记录用户上一次行为和下一次行为的发生时间,语句如下:
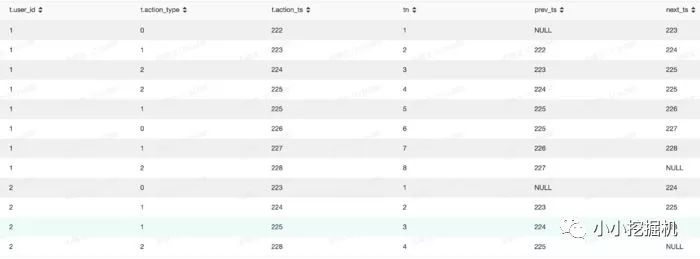
select*,row_number()over(partitionbyuser_idorderbyaction_tsasc)astn,lag(action_ts,1)over(partitionbyuser_idorderbyaction_tsasc)asprev_ts,lead(action_ts,1)over(partitionbyuser_idorderbyaction_tsasc)asnext_tsfrom(selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131)ast
结果如下:
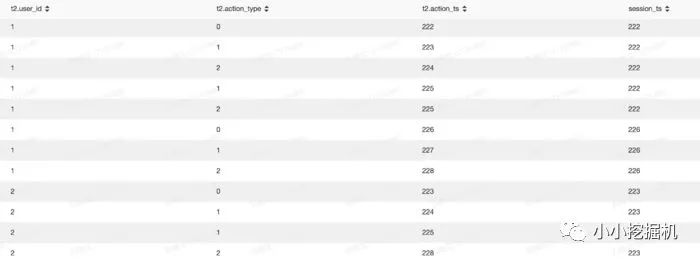
接下来,我们想实现下面的功能:给每条记录添加一列,该列代表此次session的开始时间。
前面我们介绍过,我们这里认为一次session是从一个action_type为0开始,到下一次action_type为0结束,也就是说,我们这里的数据有三个session,前5条记录是一个session,这五条记录的新列的值应给为222,同理,中间三条记录的新列的值应改为226,而最后四条记录的值应为223,那么如何实现这个功能呢,这就需要我们的lag和lead函数啦。
语句如下:
selectt2.user_id,t2.action_type,t2.action_ts,t1.action_tsassession_tsfrom(select*,lead(action_ts,1)over(partitionbyuser_idorderbyaction_tsasc)asnext_tsfrom(selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131andsplit(get_json_object(info,'$.action'),'#')[0]=='0')ast)t1innerjoin(selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131)t2ont1.user_id=t2.user_idwhere(t2.action_ts>=t1.action_tsandt2.action_ts< t1.next_ts)or ( t2.action_ts >=t1.action_tsandt1.next_tsisnull)
我们来一步步剖析一下该过程的实现,首先,我们在子查询中实现了两个表的内链接。第一个子查询查询出所有session开始的action_ts以及它对应的下一个session开始的action_ts,使用lead实现:
select*,lead(action_ts,1)over(partitionbyuser_idorderbyaction_tsasc)asnext_tsfrom(selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131andsplit(get_json_object(info,'$.action'),'#')[0]=='0')ast
第二个子查询,将简单的进行一下解析:
selectget_json_object(info,'$.userid')asuser_id,split(get_json_object(info,'$.action'),'#')[0]asaction_type,split(get_json_object(info,'$.action'),'#')[1]asaction_tsfromtest.sxw_testRowNumberwheredt=20180131
随后,我们根据两个表的user_id进行内链接,但是内链接之后会多出很多数据,我们要从中取出满足条件的,这里的条件有两个,满足其一即可,即记录的ts在两个session开始的ts之间,要么就没有后一个session:
where(t2.action_ts>=t1.action_tsandt2.action_ts< t1.next_ts)or ( t2.action_ts >=t1.action_tsandt1.next_tsisnull)
最终的结果如下:
-
函数
+关注
关注
3文章
4345浏览量
62867 -
数组
+关注
关注
1文章
417浏览量
26000
原文标题:来学习几个简单的Hive函数啦
文章出处:【微信号:atleadai,微信公众号:LeadAI OpenLab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
常用SQL函数及其用法
Python常用函数大全
大数据从业者必知必会的Hive SQL调优技巧
labview中常用的字符串函数有哪些?
简述socket编程中的常用函数
shell基本介绍及常用命令之shell介绍
cnn常用的几个模型有哪些
函数信号发生器怎么调频率
MATLAB信号处理常用函数详解
函数信号发生器按键介绍
分享几个嵌入式中常用的GUI






 工商网监
工商网监
评论