 我们最新的一个开源项目:SimpleDet
我们最新的一个开源项目:SimpleDet

今天很开心给大家介绍我们最新的一个开源项目:SimpleDet。
SimpleDet是一套简单通用的目标检测与物体识别的框架。整套框架基于MXNet的原生API完成。这篇文章不仅仅想介绍一下这样一个新的框架有什么与众不同的feature,更想去介绍一下我们为什么决定做这么一件事情以及我们的初衷是什么。
为什么还要再造一次锤子?
这个问题其实也是我们在开始这个项目之前自问了很多次的问题。如果大家有心留意下的话,Ross在产出RCNN和Fast RCNN的那两三年,每年都会去参加一下ImageNet比赛。其实当初很不解,为什么要去这么做,尤其是基本都是很裸的方法,一定不可能拿到好的名次。后来有机会去抓住Kaiming问了一下这个问题,Kaiming给我的答案是,Ross其实并不关系这个名次,Ross关心的是借这个机会宣传他更好用的锤子给大家。
其实不同于很多人认为的那样,模型fancy,结果好才是一个好工作的体现。恰恰相反,简单可靠,越多的paper愿意以这个方法作为baseline,就越说明这个方法的经典。其实对我自己而言,我从读PhD开始就一直愿意去做这样的baseline和这样的锤子。从当年用HOG+LR超越绝大多数paper的Tracking到参与MXNet项目再到后来用5行代码做domain adaptation的AdaBN。虽然开始的时候都遭受了很多人包括reviewer的质疑,但是时间都证明了这些工作的价值。
对于目标检测和识别领域,今天我们发现了同样的问题。虽有很多开源的代码和框架,但是目前看下来仍有很大进步的空间。一方面现有的开源框架虽有各种冠军头衔加持,但因为各种各样的原因,复现出真正SOTA的结果仍然不是一件轻松的事情;另一方面,一些性能还不错的开源代码(如SNIP和SNIPER)却难以拓展和维护。所导致的结果就是目前仍然有很多论文仍然在一个很低的baseline上进行改进,就算取得了性能的提升也很难说明方法的有效性。我们建立SimpleDet就是为了对于Instance Recognition这一系列问题提供一个更好的baseline和更好的锤子。
如果去问一个同学你需要一个什么样的目标检测和识别框架,我相信性能好,速度快,好用这三个关键词可以覆盖99%的需求,下面我们一一展开来看看SimpleDet在这些方面的优势和与其他开源框架的区别。
什么叫性能好?
在SimpleDet中,最值得关注的一个算法是我们的TridentNet(不知道TridentNet的同学欢迎猛戳:https://zhuanlan.zhihu.com/p/54334986)。我们公布了在各个setting下的模型和训练代码。这也是目前已知的COCO上单模型最高的算法。除了一个干净的模型(testdev mAP=42.7)之外,我们还提供了一个加上了全部大礼包的setting(testdev mAP=48.4),包括Sync BN,multi-scale training/testing,deformable conv和softer NMS。虽然这些都是在很多paper和比赛中大家已经常用的技术了,但是仍然很难把所有的方法都直接正确打开。我们在SimpleDet中提供了一套开箱即用的方案,希望借此降低复现SOTA的门槛,从而提升下整个领域中baseline的水平。除此之外,为了方便大家进一步拓展,我们还提供了一些经典模型和算法,例如Mask(Faster) RCNN,FPN,RetinaNet,CascadeRCNN等。这个算法的结果都已经经过验证,能达到论文中和已有开源代码的结果。我们后续还会进一步补充一些经典和重要的工作,也欢迎大家积极贡献。
什么叫速度快?
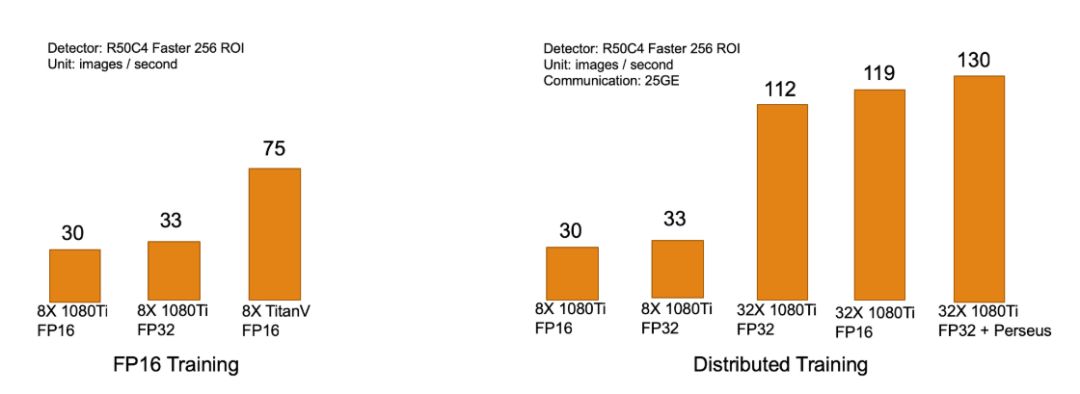
首先针对速度这个问题,我们一个独特的feature是FP16 training,FP16不仅可以节省一半的显存,在最新支持TensorCore的Volta和Turing系列GPU上还可以有一倍甚至更多的速度提升。如下左图,从1080Ti的30img/s可以提升到75img/s,展现了非常显著的提升。其次,对有不同资源的同学来说,对于速度的需求也是不同的。我们着重考虑了三种典型的用户:
1. 入门用户:这类用户可能由于实验室资源限制,或者单纯是因为个人兴趣,只能负担起小于4块GPU。针对这类用户,能够尽量复现出更多资源下的结果是第一优先级。核心的问题在于使用大的batchsize和BN batchsize。在这样的setting下,SimpleDet提供了Inplace ABN[1] (To be announced),结合上MXNet本身提供的memonger功能,再加上FP16,极限状态下训练的单卡batchsize可以达到8到16。虽然损失了一定的速度,但是在两到四卡上就能达到正常八卡训练的batchsize。
2.普通用户:这类用户应该占据绝大多数,可以独占一台8卡机器进行训练。这类用户对于速度会有着更高的需求,可以在入门用户的基础上关掉memonger这种对速度有一些影响的组件,以得到更好的训练速度。
3.土豪用户:手里有多台8卡机器,希望充分利用机器快速迭代模型。针对这部分用户,依托于MXNet优秀的分布式设计以及阿里云更进一步优化的Perseus通信框架,如下右图所示,我们在4机32卡的情况下可以做到线性加速(没有资源进行更大的测试了,更强大的土豪可以赞助点机器。。。)。这对于打比赛或者对模型迭代速度有很高要求的应用来说,无疑是个福音。
我们希望每一类用户都能各取所需,在SimpleDet中找到最适合自己资源的setting,极大化产出。
什么叫做好用?
虽然每个用户心里都会有一个好用的定义(心疼产品经理1s...),除了前面的性能和速度之外,我们认为是否容易拓展和方便清晰调参也会是两个重要的因素。我们针对一些常见需求,进行了高度模块化的设计,一个核心思想便是尽量抽象和隔离核心操作,使各种不同算法尽量复用,在这些核心操作之上拓展而无需修改。例如,我们抽象出了一整套干净通用的配置系统,除了可以配置所有常见参数之外,还将常用的预处理和数据扩充操作也都抽象出来。针对这些常见的变更,用户不需要修改核心代码即可完成调优。再比如,修改一个detection算法可能会遇到最复杂的逻辑就是在于data loader和pre-process,但是往往一个欠佳的实现会导致loader的效率大幅度下降,从而成为整个训练中的瓶颈,使得GPU利用率降低。在SimpleDet中,我们提取出了一个通用的多线程loader框架,并抽象出了在预处理中常见的操作。后续新算法的拓展可以很容易在这些通用工具的基础上同时保持简洁性和效率。更多的设计欢迎大家直接阅读源码,我们也给出了一个简单的对Faster RCNN和TridentNet代码结构的分析供大家参考。
以上便是SimpleDet的一个简要介绍,欢迎大家积极试用,提出宝贵意见。也欢迎大家一起来捉bug,贡献新的算法和feature,共同把SimpleDet打造成一套目标检测与物体识别的前沿试验平台。
-
框架
+关注
关注
0文章
404浏览量
18490 -
机器
+关注
关注
0文章
799浏览量
41932 -
开源框架
+关注
关注
0文章
33浏览量
9620
原文标题:SimpleDet: 一套简单通用的目标检测与物体识别框架
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
开源项目!教你如何制作一个开源教育机械臂
开源项目!Open Echo:一个开源的声纳项目
第一个DIY开源项目——带收音功能的插卡式移动小音箱制作
C语言开源项目
11个机器学习开源项目
一个名为“LeetCodeAnimation”的开源项目
优秀的 Verilog/FPGA开源项目介绍(一)
扒一个超棒的stm32的开源usb-can项目,canable及PCAN固件

ChatGPT了的七个开源项目
Open Echo:一个开源的声纳项目



评论