 实现通用语言智能我们还需要什么
实现通用语言智能我们还需要什么
DeepMind新年力作《学习和评估通用语言智能》,从全新的角度对跨任务NLP模型进行了评估,探讨了要实现“通用语言智能”现如今的研究还缺失什么,以及如何实现通用语言智能。
2014年11月,那时候还没有被广泛认知为“深度学习教父”的Geoffrey Hinton,在国外网站Reddit回答网友提问的活动“AMA” (Ask Me Anything) 中表示,他认为未来5年最令人激动的领域,将是机器真正理解文字和视频。
Hinton说:“5年内,如果计算机没能做到在观看YouTube视频后能够讲述发生了什么,我会感到很失望。”
幸好,现在计算机已经能够在观看一段视频后简述其内容,但距离Hinton所说的“真正理解文字和视频”,还有很远的距离。
无独有偶,统计机器学习大神Michael I. Jordan在2014年9月Reddit AMA中也提到,如果他有10亿美金能够组建研究项目,他会选择构建一个NASA规模的自然语言处理 (NLP) 计划,包括语义学、语用学等分支。
Jordan说:“从学术上讲,我认为NLP是个引人入胜的问题,既让人专注于高度结构化的推理,也触及了‘什么是思维 (mind)’ 这一核心,还非常实用,能让世界变得更加美好。”
一直以来,NLP/NLU (自然语言理解) 都被视为人工智能桂冠上的明珠,不仅因其意义重大,也表示着目标距我们遥不可及。
总之,NLP是个大难题。
前段时间在业内广泛流传的一篇“人工智障”的文章,本质上讲的就是目前NLP领域的困境。纵使有谷歌BERT模型所带来的各项指标飞跃,但要让计算机真正“理解”人类的语言,需要的恐怕不止是时间。
在最近一篇发布在Arxiv上的论文中,DeepMind的研究人员对“通用语言智能” (General Linguistic Intelligence) 做了定义,并探讨了机器如何学习并实现通用语言智能。

DeepMind新年力作《学习和评估通用语言智能》
实现通用语言智能,首先需要统一的评估标准
DeepMind的研究人员从语言的角度出发,根据近来不断发展的“通用人工智能”(AGI)的配套能力,也即能够让智能体与虚拟环境实现交互而发展出通用的探索、规划和推理能力,将“通用语言智能”定义为:
能够彻底应对各种自然语言任务的复杂性;
有效存储和重用各种表示 (representations)、组合模块 (combinatorial modules, 如将单词组成短语、句子和文档的表示),以及先前获得的语言知识,从而避免灾难性遗忘;
在从未经历过的新环境中适应新的语言任务,即对领域转换的鲁棒性。
作者还指出,如今在NLP领域存在一种非常明显且不好的趋势,那就是越来越多的数据集通过众包完成,量的确是大了,特别是在体现人类语言的“概括” (generalization) 和“抽象” (abstraction) 能力方面大打折扣,并不贴近现实中的自然分布。
此外,对于某一特定任务(比如问答),存在多个不同的数据集。因此,单独看在某个数据集上取得的结果,很容易让我们高估所取得的进步。
所以,要实现通用语言智能,或者说朝着这个方向发展,首先需要确定一个统一的评估标准。在本文中,为了量化现有模型适应新任务的速度,DeepMind的研究人员提出了一个基于在线前序编码 (online prequential coding) 的新评估指标。
接下来,就让我们看看现有的各个state-of-the-art模型性能如何。
对现有最先进模型的“五大灵魂拷问”
作者选用了两个预训练模型,一个基于BERT,一个基于ELMo。其中,BERT(base)拥有12个Transformer层,12个自注意力指针和768个隐藏层,这个预训练模型中有1.1亿个参数。另一个则基于ELMo(base),这个预训练模型有将近1亿个参数,300个双向LSTM层,100个输出层。
另有BERT/ELMo(scratch),表示没有经过预训练,从头开始的模型。
首先,作者考察了需要多少与领域知识相关的训练样本,两个模型才能在SQuAD阅读理解和MNLI自然语言推理这两个任务上取得好的表现。
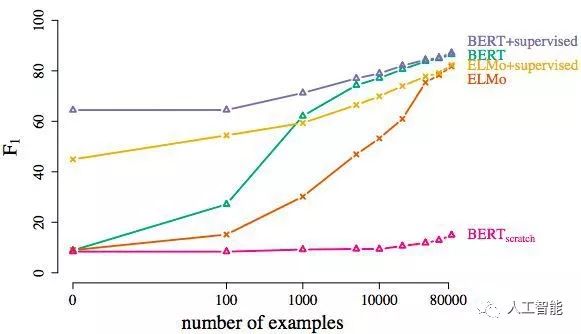
纵轴F1代表在SQuAD阅读理解数据集上的得分函数,横轴代表训练样本量的对数值
答案是4万。而且,与领域知识相关的训练样本量超过4万以后,两个模型的提升都不明显,非要说的话,BERT模型在两项任务中比ELMo稍好一点。
那么,改用在其他数据集上预训练过的模型,同样的任务性能又能提高多少呢?答案是一点点。但在代码长度上,预训练过的模型要显著优于没有经过预训练的模型。
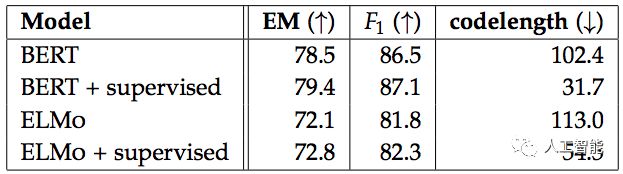
预训练模型(+supervised)与非预训练模型性能比较
作者考察的第三点是这些模型的泛化能力。实验结果表明,在SQuAD数据集上表现最好的模型,移到其他数据集,比如Trivia、QuAC、QA-SRL、QA-ZRE后,仍然需要额外的相关训练样本。这个结果在意料之中,但再次凸显了“学会一个数据集”和“学会完成一项任务”之间存在的巨大鸿沟。

在SQuAD数据集上性能最优的模型(得分超过80),在其他数据集上分数大幅降低
最后是有关学习课程 (curriculum) 和灾难性遗忘的问题。模型忘记此前学会的语言知识有多快?学习课程的设计与模型的性能之间有什么影响?
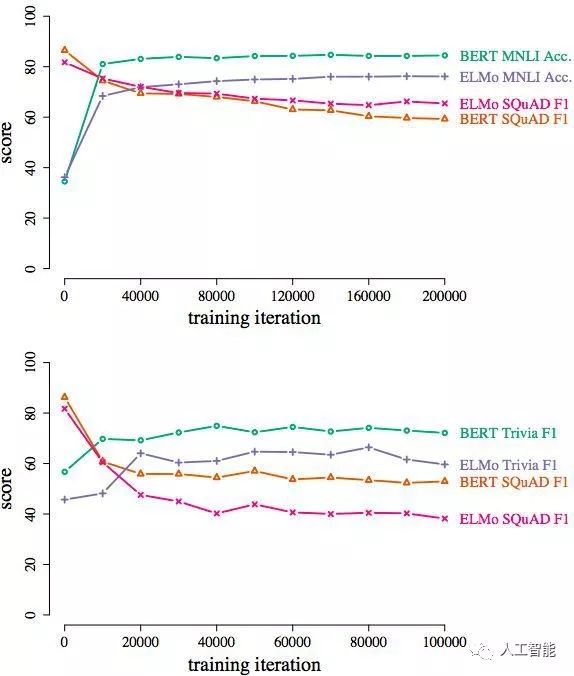
(上)将在SQuAD数据集上训练好的模型改到MNLI上;(下)将在SQuAD数据集上训练好的模型改到TriviaQA。两种情况模型的性能都大幅下降。
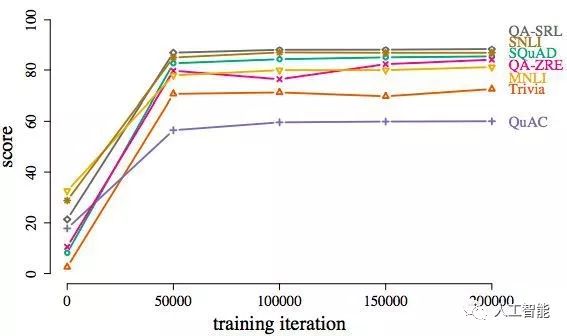
BERT模型用随机训练课程在各种数据集上取得的结果。实际上经过5万次迭代后,模型就能基本完成各项任务(超过60分)。
从实验结果看,在SQuAD数据集上训练好的模型改到MNLI或TriviaQA这些不同数据集后,模型性能很快出现大幅下降,说明灾难性遗忘发生。
虽然采用连续学习的方法,随机初始化,5万次迭代后,两个模型尤其是BERT,基本上能在各个数据集上都达到差强人意的表现。

通过随机训练,20万次迭代以后,BERT和ELMo在多项任务上的得分
但缺点是,这样的随机训练模型在开始不需要样本,转换新任务以后也不需要保留此前学会的东西。因此,在连续学习的过程中,知识迁移究竟是如何发生的,目前还不得而知。
综上,对一系列在各个不同NLP任务上取得当前最佳性能的模型进行实证评估后,DeepMind的研究人员得出结论:虽然NLP领域如今在模型设计方面取得了令人瞩目的进展,而且这些模型在很多时候都能同时完成不止一项任务,但它们仍然需要大量与领域知识相关的训练样本 (in-domain training example),并且很容易发生灾难性遗忘。
实现通用语言智能,我们还需要什么?
通过上述实验可以发现,现有的state-of-the-art NLP模型几乎全部都是:
拥有超大规模参数的深度学习模型;
事先以监督或非监督的的方式在训练样本上经过训练;
通常包含了多个针对某项特定任务的构件以完成多项任务;
默认或者说假设某项任务的数据分布是平均的。
这种方法虽然合理,但仍旧需要大量与领域知识相关的训练样本,并且非常容易发生灾难性遗忘。
因此,要实现通用语言智能,DeepMind研究人员在论文最后的讨论中指出,我们还需要:更加复杂的迁移学习和连续学习方法 (transfer and continual learning method),能让模型快速跨领域执行任务的记忆模块 (memory module),训练课程 (training curriculum) 的选择对模型性能的影响也很重要,在生成语言模型 (generative language models) 方面的进展,也将有助于实现通用语言智能。
-
DeepMind
+关注
关注
0文章
131浏览量
10988 -
nlp
+关注
关注
1文章
489浏览量
22131
原文标题:DeepMind:实现通用语言智能我们还缺什么?
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
hyper内存条,hyper-v 添加虚拟机还需要硬盘吗

ADS1293EVM如果用ubs连接电脑,还需要外部供电吗?
DAC5681z从FPGA读数据,为什么还需要一个DCLKP/N呢?
为什么FPGA属于硬件,还需要搞算法?

想用OPA134单电源放大MIC信号,单电源3.3V供电,帮忙看看哪里还需要修改一下?
有了MES、ERP,为什么还需要QMS?
AI智能眼镜都需要什么芯片






 工商网监
工商网监
评论