 OpenAI新NLP模型,刷新了7大数据集的SOTA
OpenAI新NLP模型,刷新了7大数据集的SOTA
史上最强“通用”NLP模型来袭:今天OpenAI在官博介绍了他们训练的一个大规模无监督NLP模型,可以生成连贯的文本段落,刷新了7大数据集基准,并且能在未经预训练的情况下,完成阅读理解、问答、机器翻译等多项不同的语言建模任务。
OpenAI今天在官博上介绍了他们的新NLP模型,刷新了7大数据集的SOTA(当前最佳结果),并且能够在不进行任何与领域知识相关数据训练的情况下,直接跨任务执行最基础的阅读理解、机器翻译、问答和文本总结等不同NLP任务。
无需预训练就能完成多种不同任务且取得良好结果,相当于克服了“灾难性遗忘”,简直可谓深度学习研究者梦寐以求的“通用”模型!
如果说谷歌的BERT代表NLP迈入了一个预训练模型的新时代,OpenAI便用这一成果证明,只要拥有超凡的数据量和计算力,就能实现以往无法想象的事情。
例如计算力,根据参与OpenAI强化学习研究的Smertiy透露,新模型使用了256块谷歌TPU v3(没有公布具体的训练时间),训练价格每小时2048美元。
OpenAI的这个NLP模型基于Transformer,拥有15亿参数,使用含有800万网页内容的数据集训练,只为一个目的:
根据当前已有的信息,预测下一个单词是什么。
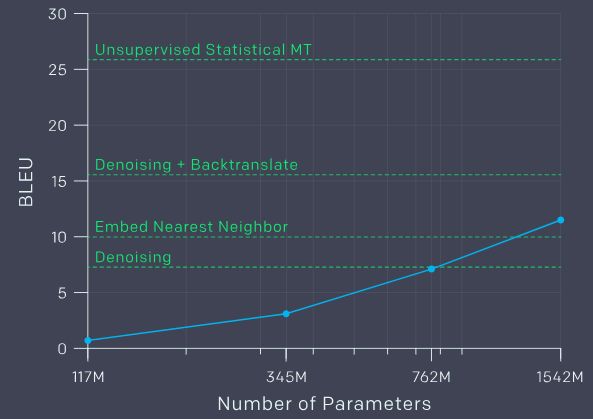
新模型的名字叫GPT-2,是OpenAI去年发布的无监督NLP模型GPT的直接拓展,新模型用到的参数和训练数据,都增长了超过10个数量级。
由于模型容量足够大,并且训练数据足够多,GPT-2在拥有40GB网络数据的测试集上,仅是简单“预测下一个单词是什么”,就足以完成各种不同的NLP任务,展示出了强大的泛化能力。
当前,构建机器学习系统的主流方法是监督学习——收集数据,也即喂给模型一套“理想的”输入和输出组合,让模型模仿“套路”,在新的测试数据集上也给出类似的结果。这种方法在特定领域任务上表现很好,但缺点是一旦改为其他任务,比如将在问答数据集上表现很好的模型用到阅读理解上,模型就无法适应,也即泛化能力很差。
对此,OpenAI的研究人员大胆推测:当前机器学习系统泛化能力差的原因,恰恰是因为让模型局限在特定领域的数据集上做特定任务的训练。
同时,现有的多任务模型研究证明,单纯依靠训练样本的增加,难以实现有效的任务扩展;NLP研究人员正越来越多地使用自注意力模块迁移学习来构建多任务学习模型。
于是,OpenAI的研究人员结合上述两种思路,在更通用的数据集基础上,使用自注意力模块迁移学习,然后得到了一个无需调整任何参与或模型结构,在 zero-shot 情况下能够执行多项不同NLP任务的模型,也即上文所说的GPT-2。
有鉴于其强大的能力和可能被滥用的危险,OpenAI并没有公布GPT-2模型及代码,只公布了一个仅含117M参数的样本模型及代码,供有兴趣的研究人员学习和参考:https://github.com/openai/gpt-2
当然,GPT-2的具体模型结构OpenAI这次也没有详述,他们预留了半年的时间向学界征集意见。在公布的论文“Language Models are Unsupervised Multitask Learners”中,OpenAI的研究人员介绍了模型构建的思路和方法。
至于具体的计算力,论文中没有提及,根据上文Twitter上的数据,他们的模型使用了256个谷歌云TPU v3,尽管没有公布训练时间。TPU v3在Google之外只提供单独使用版本(尽管OpenAI可能得到了特别的许可),这意味着他们要支付8 * 256 = 2048美元/小时。
下面,就是OpenAI展示其成果的时间——你也可以直接拉到文末,点击“阅读原文”查看论文。
无需预训练,8个数据集7个刷新当前最佳纪录
我们对四个语言模型进行了训练和基准测试,它们的大小如下表所示:

4个模型大小的架构和超参数
其中,最小的模型等价于原始的GPT,次小的等价于最大的BERT模型。我们的最大模型是GPT-2,它的参数比GPT多一个数量级。
GPT-2在各种领域特定的语言建模任务上取得了state-of-the-art 的成绩。我们的模型没有针对任何特定于这些任务的数据进行训练,只是作为最终测试对它们进行了评估;这就是被称为“zero-shot”的设置。
当在相同的数据集上进行评估时,GPT-2比在特定领域数据集(如Wikipedia、新闻、书籍)上训练的模型表现更好。
下表显示了我们所有最先进的zero-shot结果。
(+)表示该项分数越高越好。(-)表示分数越低越好。
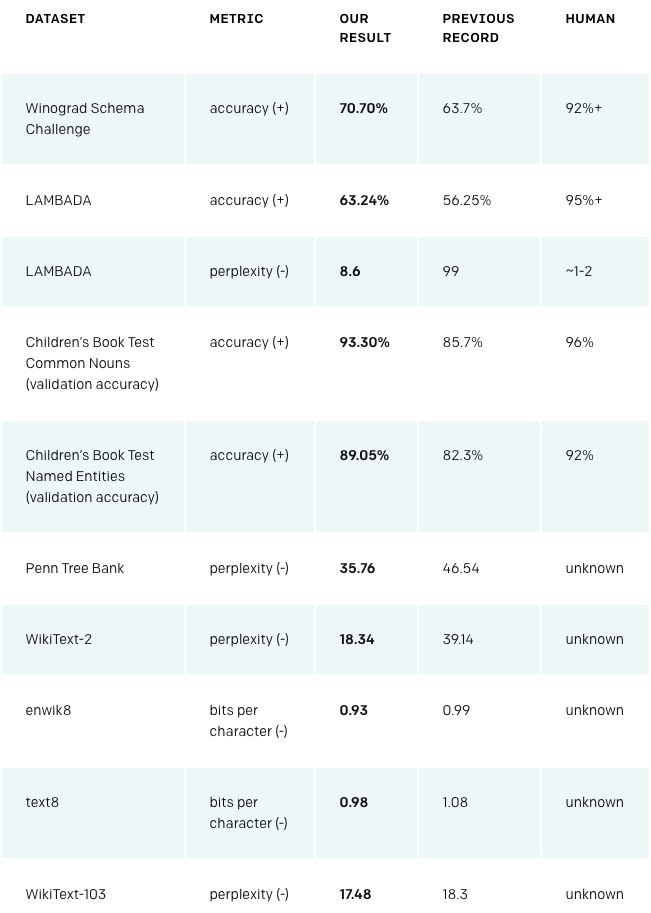
GPT-2在这些数据集中均获得SOTA结果
GPT-2在Winograd Schema、LAMBADA以及其他语言建模任务上实现了state-of-the-art 的结果。
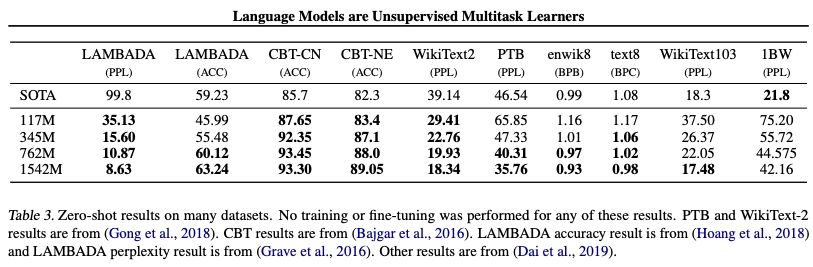
在各数据集上,四种不同参数大小模型的Zero-shot结果。
可以看到,WebText LMs可以很好地跨域和数据集传输,在zero-shot设置下将8个数据集中的7个的state of the art结果进一步提升了。
在Penn Treebank和WikiText-2等只有100万到200万个训练token的小型数据集上,可以看到改进很大。在用于测量长期依赖关系的数据集上,如LAMBADA和the Children’s Book Test,也有很大的改进。
我们的模型在One Billion Word Benchmark上仍然明显比之前的工作要差。这可能是由于它既是最大的数据集,又有一些最具破坏性的预处理——1BW的句子级变换消除了所有的远程结构。
其他任务:问答、阅读理解、摘要总结和翻译
在其他语言任务,如问题回答、阅读理解、摘要总结和翻译,我们在没有对模型进行任何微调的情况下获得了极好的结果,只需要以正确的方式提示训练模型(下面的例子展示了具体做法和结果),但在这些任务还达不到专业系统的SOTA水平。
1、阅读理解:回答关于给定段落的问题
数据集:CoQA
示例
The 2008 Summer Olympics torch relay was run from March 24 until August 8, 2008, prior to the 2008 Summer Olympics, with the theme of “one world, one dream”. Plans for the relay were announced on April 26, 2007, in Beijing, China. The relay, also called by the organizers as the “Journey of Harmony”, lasted 129 days and carried the torch 137,000 km (85,000 mi) – the longest distance of any Olympic torch relay since the tradition was started ahead of the 1936 Summer Olympics.
After being lit at the birthplace of the Olympic Games in Olympia, Greece on March 24, the torch traveled to the Panathinaiko Stadium in Athens, and then to Beijing, arriving on March 31. From Beijing, the torch was following a route passing through six continents. The torch has visited cities along the Silk Road, symbolizing ancient links between China and the rest of the world. The relay also included an ascent with the flame to the top of *** on the border of Nepal and Tibet, China from the Chinese side, which was closed specially for the event.
Q: What was the theme?A: “one world, one dream”.
Q: What was the length of the race?A: 137,000 km
Q: Was it larger than previous ones?A: No
Q: Where did the race begin?A: Olympia, Greece
Q: Is there anything notable about that place?A: birthplace of Olympic Games
Q: Where did they go after?A: Athens
Q: How many days was the race?A: seven
Q: Did they visit any notable landmarks?A: Panathinaiko Stadium
Q: And did they climb any mountains?
A:
Target answers:unknownoryesModel answer:Everest
性能表现:
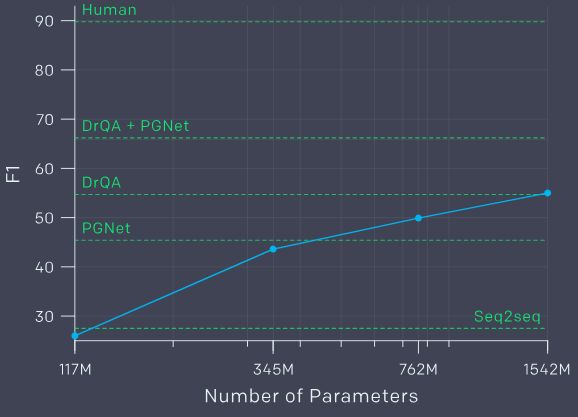
在阅读理解任务中,GPT-2比DrQA+PGNet要差,也远低于人类水平
2、常识推理:解决含义模糊的代词
数据集:Winograd Schema Challenge
示例
The trophy doesn’t fit into the brown suitcase because it is too large.
Correct answer:it = trophyModel answer:it = trophy
The trophy doesn’t fit into the brown suitcase because it is too small.
Correct answer:it = suitcaseModel answer:it = suitcase
性能表现
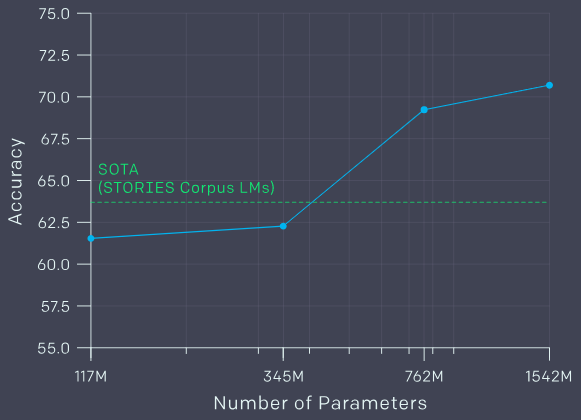
在常识推理任务中,GPT-2优于SOTA
3、问题回答
数据集:Natural Questions
示例
Who wrote the book the origin of species?
Correct answer:Charles DarwinModel answer:Charles Darwin
What is the largest state in the U.S. by land mass?
Correct answer:AlaskaModel answer:California
性能表现:
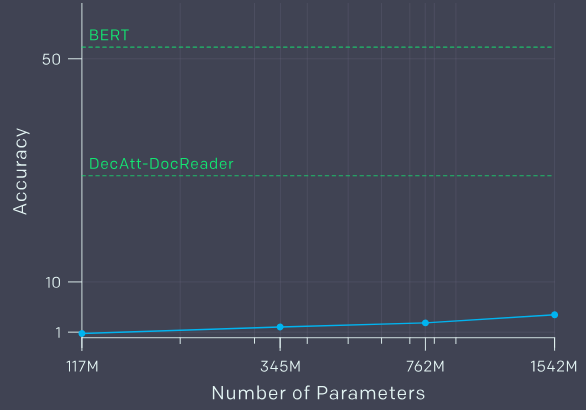
在问答任务中,GPT-2的表现远低于BERT
4、广义语境的语言建模:预测一段文字的最后一个词
数据集:LAMBADA
示例
Both its sun-speckled shade and the cool grass beneath were a welcome respite after the stifling kitchen, and I was glad to relax against the tree’s rough, brittle bark and begin my breakfast of buttery, toasted bread and fresh fruit. Even the water was tasty, it was so clean and cold. It almost made up for the lack of…
Correct answer:coffeeModel answer:food
性能表现
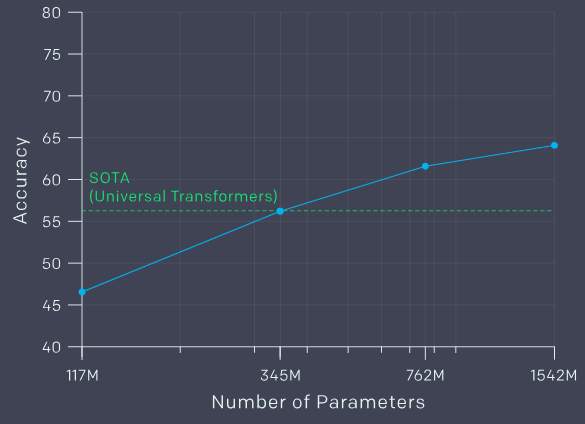
在广义语境的语言建模任务中,GPT-2比SOTA的模型表现更好
5、写摘要:对新闻文章进行总结
数据集:CNN和每日邮报数据集
示例文本:
Prehistoric man sketched an incredible array of prehistoric beasts on the rough limestone walls of a cave in modern day France 36,000 years ago.
Now, with the help of cutting-edge technology, those works of art in the Chauvet-Pont-d’Arc Cave have been reproduced to create the biggest replica cave in the world.
…
参考摘要:
Cave mimics famous Caverne du Pont-d’Arc in France, the oldest cave decorated by man and the best preserved. The replica contains all 1,000 paintings which include 425 such as a woolly rhinoceros and mammoths. Minute details were copied using 3D modelling and anamorphic techniques, often used to shoot widescreen images. The modern cave also includes replica paw prints of bears, bones and details preserved in the original cave.
机器编写的摘要:
The original site in Vallon-Pont-D’arc in Southern France is a Unesco World Heritage site and is the oldest known and the best preserved cave decorated by man. The replica cave was built a few miles from the original site in Vallon-Pont-D’Arc in Southern France. The cave contains images of 14 different species of animals including woolly rhinoceros, mammoths, and big cats.
性能表现
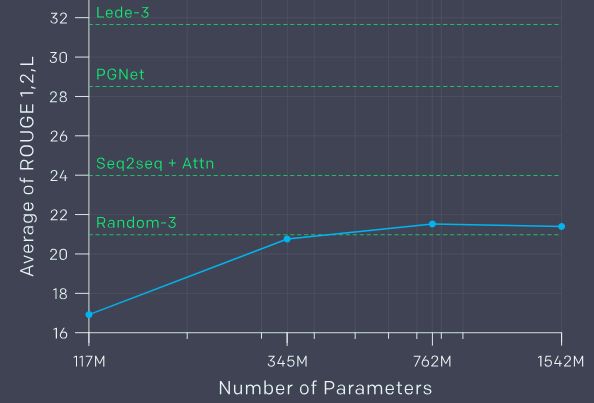
在摘要任务中,GPT-2的表现不如专门的系统
6、机器翻译:把法语句子翻译成英语
数据集:WMT-14 Fr-En
示例
法语句子:
Un homme a expliqué que l’opération gratuite qu’il avait subie pour soigner une hernie lui permettrait de travailler à nouveau.
参考翻译:
One man explained that the free hernia surgery he’d received will allow him to work again.
模型的翻译
A man told me that the operation gratuity he had been promised would not allow him to travel.
性能表现
在法语-英语机器翻译任务中,GPT-2的表现不如专门的系统
我们认为,由于这些任务是通用语言建模的子集,我们可以预期随着计算力和数据量的增加,性能会进一步提高。其他研究人员也发表了类似的假设。我们还期望通过微调来提高下游任务的性能,尽管这需要进行彻底的实验。
-
机器翻译
+关注
关注
0文章
139浏览量
14910 -
数据集
+关注
关注
4文章
1208浏览量
24727 -
nlp
+关注
关注
1文章
489浏览量
22052
原文标题:15亿参数!史上最强通用NLP模型诞生:狂揽7大数据集最佳纪录
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI暂不推出Sora视频生成模型API
OpenAI世界最贵大模型:昂贵背后的技术突破
Orion模型即将面世,OpenAI采用新发布模式
nlp逻辑层次模型的特点
nlp自然语言处理模型有哪些
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
OpenAI推出全新大语言模型
Stack Overflow与OpenAI签订协议为其模型提供数据
微软准备推出新的AI模型与谷歌及OpenAI竞争
Anthropic 声称其新的 AI 聊天机器人模型击败了 OpenAI 的 GPT-4

OpenAI文生视频模型Sora要点分析

高分工作!Uni3D:3D基础大模型,刷新多个SOTA!

最佳开源模型刷新多项SOTA,首次超越Mixtral Instruct!「开源版GPT-4」家族迎来大爆发






 工商网监
工商网监
评论