 “公开代码”再次成为焦点,这次你站在哪一边?
“公开代码”再次成为焦点,这次你站在哪一边?
OpenAI担心其NLP模型“过于强大”或遭滥用而不公开代码及模型的做法似乎引发众怒。今天外网AI圈几乎全是对OpenAI的批评及嘲讽,尽管微弱的支援声夹杂其中。“公开代码”再次成为焦点,这次你站在哪一边?
OpenAI火了,虽然并非以他们希望的方式。
昨天,OpenAI在官博宣布,他们构建了一个强大的NLP模型,但正因为这个模型过于强大,能够生成以假乱真的句子,为了避免其遭到滥用,他们决定不公开模型的具体结构和代码 (而仅发布了一个小很多的样例)。
“大型的通用语言模型可能会产生重大的社会影响,”OpenAI的官博这样写道,他们的这个模型现在公布出来,“可能被用于生成假新闻、在线假装某人的身份、在社交媒体上发布虚假内容或故意误导言论,以及自动生成垃圾邮件/网络钓鱼内容”。
OpenAI还援引了DeepFake,这是计算机视觉界一个臭名昭著的例子,DeepFake由于其强大的图像生成能力,成了一个“假脸生成器/换脸器”,制造出大量恶意的虚假视频、音频和图像而被禁用。
OpenAI还在博客中写了对相关政策的讨论,包括确保AI研究安全可靠,符合伦理道德标准。但没想到的是,良苦的用心,却遭到网友几乎一边倒的批评和讥讽。
OpenAI干脆改名“CloseAI”算了!

我也做了个超强大的MNIST模型,要不要担心它被滥用而不公开呢?

更有甚者,比如下面这位Ben Recht,还发了一条Twitter长文进行嘲讽:

今天我要介绍我们的论文“Do ImageNet Classifiers Generalize to ImageNet?”我们尝试按照原论文描述复现其结果,但发现这样做实在太难!
……我们完全可以基于一个不能公开的数据集构建一个超大模型,在我们自己的标准ML范式中很难发生过拟合。
但是,测试集上的一个微小改动就会导致分布结果大幅变化,你可以想见把模型和代码全都公布出来以后会发生什么!
PS 这篇论文还在arxiv等候审核发布,要不是我们的最终版PDF过大,那就是因为arxiv也学着OpenAI的做法,觉得AI/ML研究太过危险而不能公开。
OpenAI:新NLP模型很强大,公布后可能遭滥用
从研究的角度来看,OpenAI昨天宣布的“强大”NLP模型GPT-2,技术突破性体现在两个方面。首先,是模型的容量空前巨大。
根据OpenAI的研究主管Dario Amodei介绍,GPT-2的参数有15亿,是上一个版本GPT大小的12倍,训练数据集则扩大了15倍。
GPT-2在一个包含约1000万篇文章的数据集上进行训练,而这些文章来源是从Reddit上点赞超过三票的链接里爬出来的,大小是40GB,相当于3.5万本《白鲸记》(Moby Dick)。
实际上,GPT2就是一个自动文本生成器,但鉴于其训练数据量直接影响模型的性能,也使GPT2成为一个更加通用的语言生成模型,这也正是其第二个突破所在:相比以往的文本模型,GPT2能完成更多的任务,包括机器翻译、文本总结,以及阅读理解,而且有的时候,其性能还超过了专门为某种任务——比如阅读理解——构建的模型。
也正因如此,致使OpenAI违背其名称中宣扬的“Open”理念,不公开这个模型。“如果你无法预测模型能够做什么,你就不得不去做各种实验,但这个世界上有太多太多比我们更聪明更厉害,更善于拿这个模型去做坏事的人存在。”
OpenAI宣传主管Jack Clark在接受《卫报》采访时表示:“我们并不是说我们知道什么该做,我们也并不是在通过这种方法在表明这样做就是对的,我们还在探讨更严谨和谨慎的做法。我们算是摸着石头过河。”
OpenAI给出了其模型强大的例子,可以参见昨天新智元的报道。
网友观点:不公开代码和训练集就干脆别发表!
至于持反对观点的网友这边,很多人恰恰是因为了解模型在训练集和测试集上表现的区别,才纷纷反对OpenAI不公开全部代码和数据集的做法。
其次,OpenAI“担心AI研究太危险而不公开”的理由,也成了众矢之的。比如Denny Britz在Twitter上发文称:
是不是又该旧话重提,“AI能自己生成语言,所以不能再研究AI了!”
去年,加拿大蒙特利尔大学的计算机科学家们希望展示一种新的语音识别算法,他们希望将其与一名著名科学家的算法进行比较。唯一的问题:该benchmark的源代码没有发布。研究人员不得不从已公开发表的描述中重现这一算法。但是他们重现的版本无法与benchmark声称的性能相符。蒙特利尔大学实验室博士生Nan Rosemary Ke说:“我们尝试了2个月,但都无法接近基准的性能。”
人工智能(AI)这个蓬勃发展的领域正面临着实验重现的危机,就像实验重现问题过去十年来一直困扰着心理学、医学以及其他领域一样。AI研究者发现他们很难重现许多关键的结果,这导致了对研究方法和出版协议的新认识。法国国家信息与自动化研究所的计算神经科学家Nicolas Rougier说:“这个领域以外的人可能会认为,因为我们有代码,所以重现性是有保证的。但完全不是这样。”
AAAI 2018会议上,reproducibility问题被提上议程,一些团队对这个问题进行了分析。挪威科技大学计算机科学家Odd Erik Gundersen报告了一项调查的结果,调查针对过去几年在两个AI顶会上发表的论文中提出的400种算法,结果只有6%的研究者分享了算法的代码,只有三分之一的人分享了他们测试算法的数据,而只有一半分享了“伪代码”。
针对主要会议上发表的400篇AI论文的调查显示,只有6%的论文包含算法的代码,约30%包含测试数据,54%包含伪代码。
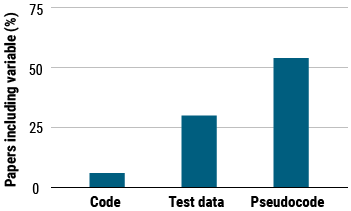
CREDITS: (GRAPHIC) E. HAND/SCIENCE; (DATA) GUNDERSEN AND KJENSMO, ASSOCIATION FOR THE ADVANCEMENT OF ARTIFICIAL INTELLIGENCE 2018
研究人员说,这些缺失的细节的原因有很多:代码可能是一项正在进行中的工作,所有权归某一家公司,或被一名渴望在竞争中保持领先地位的研究人员紧紧掌握。代码可能依赖于其他代码,而其他代码本身未发布。或者代码可能只是丢失了,在丢失的磁盘上或被盗的笔记本电脑上——Rougier称之为“我的狗吃了我的程序”问题。
假设你可以获得并运行原始代码,它仍然可能无法达到你的预期。在机器学习领域,计算机从经验中获取专业知识,算法的训练数据可以影响其性能。这也是这次OpenAI没有公开其全部代码和训练集遭到网友反对的主要原因。
在这场意外掀起的激烈争论中,你站在哪一边呢?
-
AI
+关注
关注
87文章
30898浏览量
269130 -
代码
+关注
关注
30文章
4788浏览量
68625 -
计算机视觉
+关注
关注
8文章
1698浏览量
45994
原文标题:OpenAI担心自家AI太强大不公开代码,网友嘲讽:改名CloseAI算了
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
临江而立:智慧边坡监测守护长江岸坡安全
非球面透镜背后的焦点研究
Air201公开但没全公开?你要的资料在这里!
求助,一个超级难找到的元器件,有礼金相送
京东方HV320WHB-N00一边白屏案例
TPA3255加了PFFB后一边输出声音很小是什么原因?
PCB生产,在钻咀和成品孔径之间,你会优先满足哪一项呢
一边光模块一边光纤收发器可以吗
MWC上海如期而至,AI和5G-A成为焦点
陶瓷基板技术PK:DBC vs DPC,你站哪一边?






 工商网监
工商网监
评论