 一个实用的GitHub项目:TensorFlow-Cookbook
一个实用的GitHub项目:TensorFlow-Cookbook
今天为大家推荐一个实用的GitHub项目:TensorFlow-Cookbook。 这是一个易用的TensorFlow代码集,包含了对GAN有用的一些通用架构和函数。
今天为大家推荐一个实用的GitHub项目:TensorFlow-Cookbook。
这是一个易用的TensorFlow代码集,作者是来自韩国的AI研究科学家Junho Kim,内容涵盖了谱归一化卷积、部分卷积、pixel shuffle、几种归一化函数、 tf-datasetAPI,等等。
作者表示,这个repo包含了对GAN有用的一些通用架构和函数。
项目正在进行中,作者将持续为其他领域添加有用的代码,目前正在添加的是 tf-Eager mode的代码。欢迎提交pull requests和issues。
Github地址 :
https://github.com/taki0112/Tensorflow-Cookbook
如何使用
Import
ops.py
operations
from ops import *
utils.py
image processing
from utils import *
Network template
def network(x, is_training=True, reuse=False, scope="network"): with tf.variable_scope(scope, reuse=reuse): x = conv(...) ... return logit
使用DatasetAPI向网络插入数据
Image_Data_Class = ImageData(img_size, img_ch, augment_flag) trainA = trainA.map(Image_Data_Class.image_processing, num_parallel_calls=16) trainA = trainA.shuffle(buffer_size=10000).prefetch(buffer_size=batch_size).batch(batch_size).repeat() trainA_iterator = trainA.make_one_shot_iterator() data_A = trainA_iterator.get_next() logit = network(data_A)
了解更多,请阅读:
https://github.com/taki0112/Tensorflow-DatasetAPI
Option
padding='SAME'
pad = ceil[ (kernel - stride) / 2 ]
pad_type
'zero' or 'reflect'
sn
usespectral_normalizationor not
Ra
userelativistic ganor not
loss_func
gan
lsgan
hinge
wgan
wgan-gp
dragan
注意
如果你不想共享变量,请以不同的方式设置所有作用域名称。
权重(Weight)
weight_init = tf.truncated_normal_initializer(mean=0.0, stddev=0.02) weight_regularizer = tf.contrib.layers.l2_regularizer(0.0001) weight_regularizer_fully = tf.contrib.layers.l2_regularizer(0.0001)
初始化(Initialization)
Xavier: tf.contrib.layers.xavier_initializer()
He: tf.contrib.layers.variance_scaling_initializer()
Normal: tf.random_normal_initializer(mean=0.0, stddev=0.02)
Truncated_normal: tf.truncated_normal_initializer(mean=0.0, stddev=0.02)
Orthogonal: tf.orthogonal_initializer(1.0) / # if relu = sqrt(2), the others = 1.0
正则化(Regularization)
l2_decay: tf.contrib.layers.l2_regularizer(0.0001)
orthogonal_regularizer: orthogonal_regularizer(0.0001) & orthogonal_regularizer_fully(0.0001)
卷积(Convolution)
basic conv
x = conv(x, channels=64, kernel=3, stride=2, pad=1, pad_type='reflect', use_bias=True, sn=True, scope='conv')
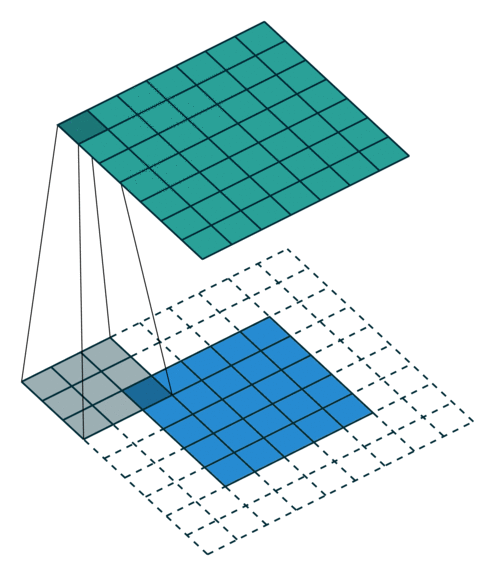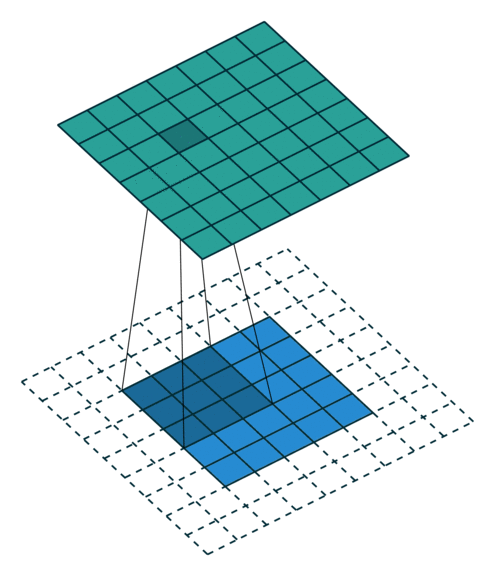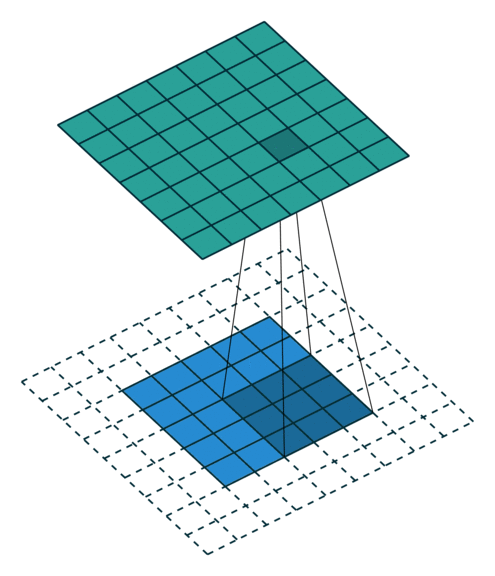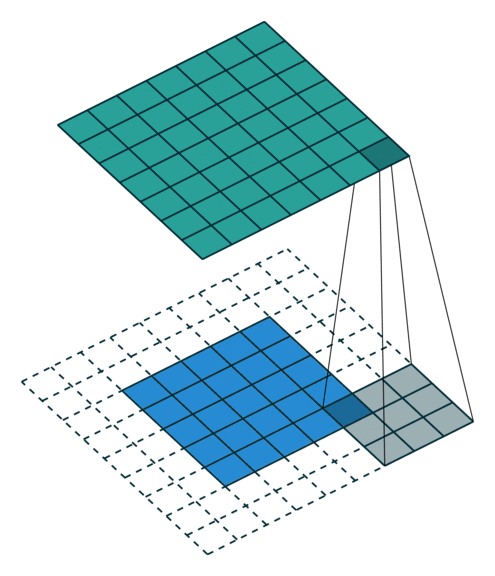
partial conv (NVIDIAPartial Convolution)
x = partial_conv(x, channels=64, kernel=3, stride=2, use_bias=True, padding='SAME', sn=True, scope='partial_conv')
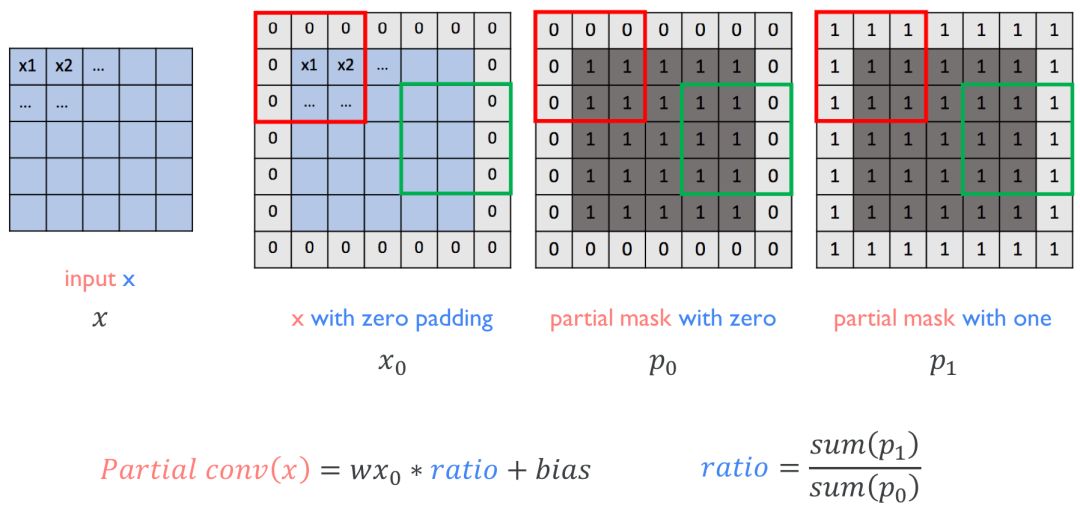
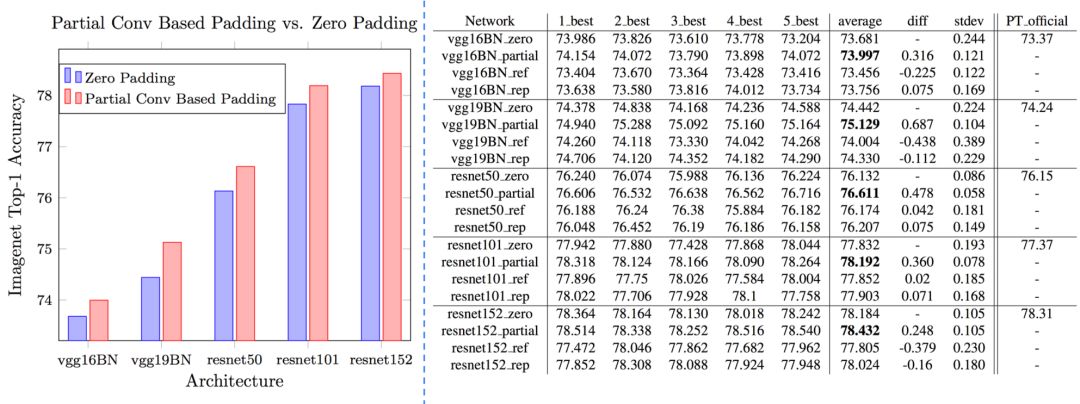
dilated conv
x = dilate_conv(x, channels=64, kernel=3, rate=2, use_bias=True, padding='SAME', sn=True, scope='dilate_conv')
Deconvolution
basic deconv
x = deconv(x, channels=64, kernel=3, stride=2, padding='SAME', use_bias=True, sn=True, scope='deconv')
Fully-connected
x = fully_conneted(x, units=64, use_bias=True, sn=True, scope='fully_connected')
Pixel shuffle
x = conv_pixel_shuffle_down(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_down') x = conv_pixel_shuffle_up(x, scale_factor=2, use_bias=True, sn=True, scope='pixel_shuffle_up')
down===> [height, width] -> [height // scale_factor, width // scale_factor]
up===> [height, width] -> [height * scale_factor, width * scale_factor]
Block
residual block
x = resblock(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block') x = resblock_down(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_down') x = resblock_up(x, channels=64, is_training=is_training, use_bias=True, sn=True, scope='residual_block_up')
down===> [height, width] -> [height // 2, width // 2]
up===> [height, width] -> [height * 2, width * 2]
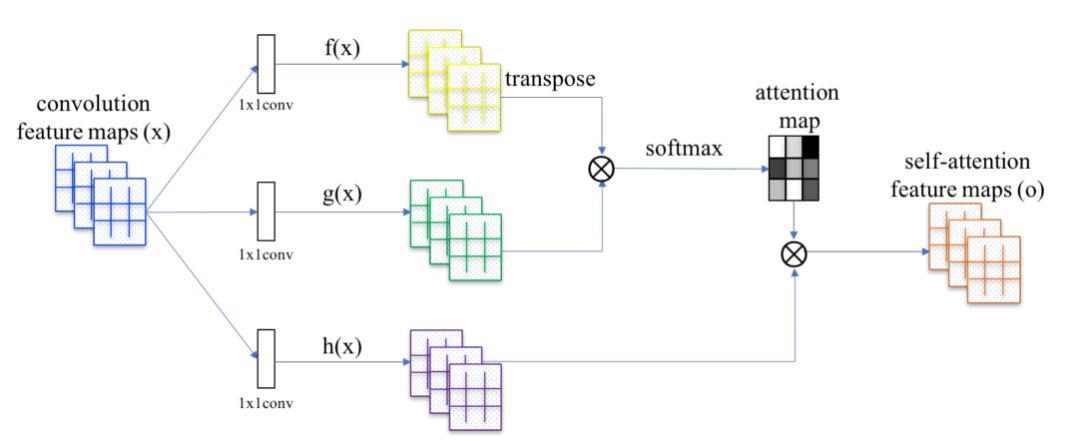
attention block
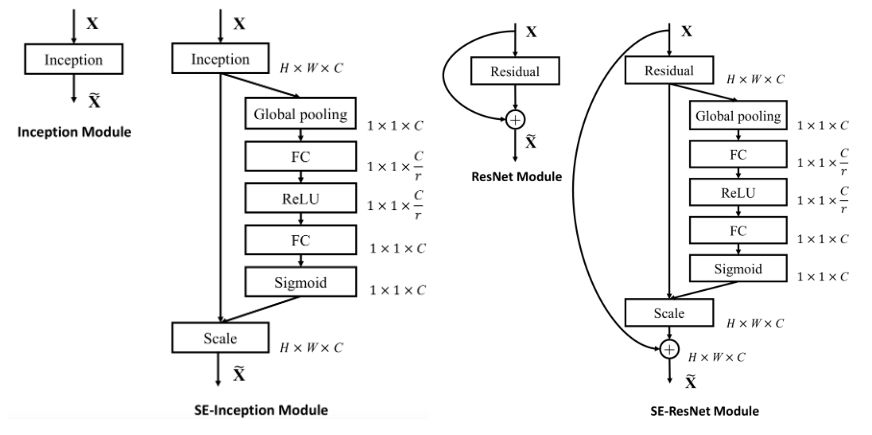
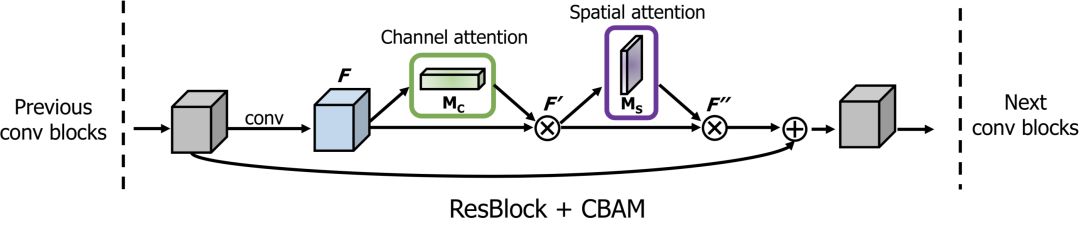
x = self_attention(x, channels=64, use_bias=True, sn=True, scope='self_attention') x = self_attention_with_pooling(x, channels=64, use_bias=True, sn=True, scope='self_attention_version_2') x = squeeze_excitation(x, channels=64, ratio=16, use_bias=True, sn=True, scope='squeeze_excitation') x = convolution_block_attention(x, channels=64, ratio=16, use_bias=True, sn=True, scope='convolution_block_attention')
Normalization
Normalization
x = batch_norm(x, is_training=is_training, scope='batch_norm') x = instance_norm(x, scope='instance_norm') x = layer_norm(x, scope='layer_norm') x = group_norm(x, groups=32, scope='group_norm') x = pixel_norm(x) x = batch_instance_norm(x, scope='batch_instance_norm') x = condition_batch_norm(x, z, is_training=is_training, scope='condition_batch_norm'): x = adaptive_instance_norm(x, gamma, beta):
如何使用condition_batch_norm,请参考:
https://github.com/taki0112/BigGAN-Tensorflow
如何使用adaptive_instance_norm,请参考:
https://github.com/taki0112/MUNIT-Tensorflow
Activation
x = relu(x) x = lrelu(x, alpha=0.2) x = tanh(x) x = sigmoid(x) x = swish(x)
Pooling & Resize
x = up_sample(x, scale_factor=2) x = max_pooling(x, pool_size=2) x = avg_pooling(x, pool_size=2) x = global_max_pooling(x) x = global_avg_pooling(x) x = flatten(x) x = hw_flatten(x)
Loss
classification loss
loss, accuracy = classification_loss(logit, label)
pixel loss
loss = L1_loss(x, y) loss = L2_loss(x, y) loss = huber_loss(x, y) loss = histogram_loss(x, y)
histogram_loss表示图像像素值在颜色分布上的差异。
gan loss
d_loss = discriminator_loss(Ra=True, loss_func='wgan-gp', real=real_logit, fake=fake_logit) g_loss = generator_loss(Ra=True, loss_func='wgan_gp', real=real_logit, fake=fake_logit)
如何使用gradient_penalty,请参考:
https://github.com/taki0112/BigGAN-Tensorflow/blob/master/BigGAN_512.py#L180
kl-divergence (z ~ N(0, 1))
loss = kl_loss(mean, logvar)
Author
Junho Kim
Github地址 :
https://github.com/taki0112/Tensorflow-Cookbook
-
函数
+关注
关注
3文章
4350浏览量
63078 -
GitHub
+关注
关注
3文章
474浏览量
16701 -
tensorflow
+关注
关注
13文章
329浏览量
60668
原文标题:【收藏】简单易用 TensorFlow 代码集,GAN通用框架、函数
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何使用tensorflow快速搭建起一个深度学习项目
干货 | TensorFlow的55个经典案例
TensorFlow是什么
TensorFlow的特点和基本的操作方式
github入门到上传本地项目步骤
提出一个快速启动自己的 TensorFlow 项目模板
总结Tensorflow纯干货学习资源,分为教程、视频和项目三大板块
人工智能凉了? GitHub年度报告揭示真相
总结一份GitHub热门开源项目
TensorFlow Community Spotlight获奖项目
如何使用Github高效率的查找项目





 工商网监
工商网监
评论