 OpenAI发布的史上最强NLP似乎成了负面新
OpenAI发布的史上最强NLP似乎成了负面新
前几日,OpenAI发布史上最强“通用”NLP模型,但号称过于强大怕被滥用而没有开源,遭到网友猛怼、炮轰。而做为创始人之一的马斯克,虽然早已离开董事会,碍于舆论,不得不站出来做出澄清:我早已退出。
OpenAI发布的史上最强NLP似乎成了负面新闻。
原因是,OpenAI并没有公布GPT-2模型及代码,只是象征性的公布了一个仅含117M参数的样本模型及代码,给到的理由:因为这个模型能力太强大了!他们目前还有点hold不住它。一旦开源后被坏人拿到,将会贻害无穷。
之后有网友气不过跑到马斯克推特底下,叫骂OpenAI干脆改名CloseAI。
然而,马斯克却连发数文,澄清与OpenAI的关系:我早已退出。

马斯克表示,已经有一年多的时间没有和OpenAI密切合作了,并且也没有管理层和董事会的监督。
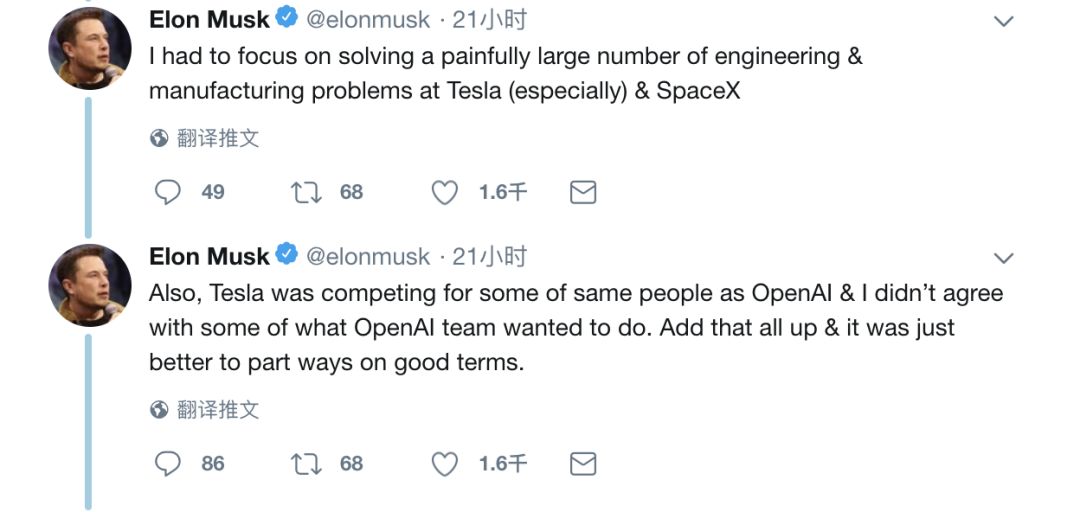
而后有网友追问:“一直不知道你为何离开OpenAI,可否给予详细的解释说明?”
马斯克便又在推特上补充道:
我必须集中精力解决大量让人头疼的工程和制造问题,尤其是在特斯拉和SpaceX方面。
此外,特斯拉与OpenAI在人才争夺方面也有一些交集,我并不同意其团队想要做的一些事情。综上所述,希望最好是友好分手。
2015年12月,马斯克与Y Combinator总裁Sam Altman共同创立这个非营利组织研究机构,以研究人工智能的道德和安全问题。
然而,在亲手创办两年多后,伊隆·马斯克退出了OpenAI董事会。
虽然马斯克于去年2月离开了该组织,但却一直被认为是OpenAI主要资助者之一。

官博地址:
https://blog.openai.com/openai-supporters/
OpenAI在去年2月20日发布的官方博客中也提到:“马斯克将离开OpenAI董事会,但仍将继续为该组织提供捐赠和建议。随着特斯拉将更加关注人工智能,这将消除马斯克未来潜在的冲突。”
值得注意的是,马斯克一直是人工智能最大的批评者之一。2014年在麻省理工学院演讲时,他将人工智能描述为“存在的最大威胁”,甚至称之为“召唤恶魔”。
他还认为人工智能甚至可以导致第三次世界大战。他补充称,大国之间都不会故意发动核战争,但人工智能将是最有可能的、先发制人的取胜之道。
OpenAI称模型使用15亿参数,训练一小时相当于烧掉一台iPhone Xs Max(512G)
马斯克之所以被@出来说明一个问题:Elon离开OpenAI的消息,还有很多人不知道,或者知道他已经离开了董事会却不知为何,导致他又特意出来发推澄清一下,顺便又蹭了一下OpenAI最近的热点。
OpenAI近日宣称他们研究出一个GPT-2的NLP模型,号称“史上最强通用NLP模型”,因为它是:
踩在15亿参数的身体上:爬取了Reddit上点赞超过三票的链接的文本内容,大约用到1000万篇文章,数据体量超过了40G,相当于35000本《白鲸记》。(注:小说约有21万单词,是电影《加勒比海盗》的重要故事参考来源之一。动漫《海贼王》里四皇之一的白胡子海贼团的旗舰就是以故事主角大白鲸的名字Moby Dick命名)。
无需预训练的“zero-shot”:在更通用的数据集基础上,使用自注意力模块迁移学习,不针对任何特定任务的数据进行训练,只是作为最终测试对数据进行评估,在Winograd Schema、LAMBADA以及其他语言建模任务上实现了state-of-the-art 的结果。
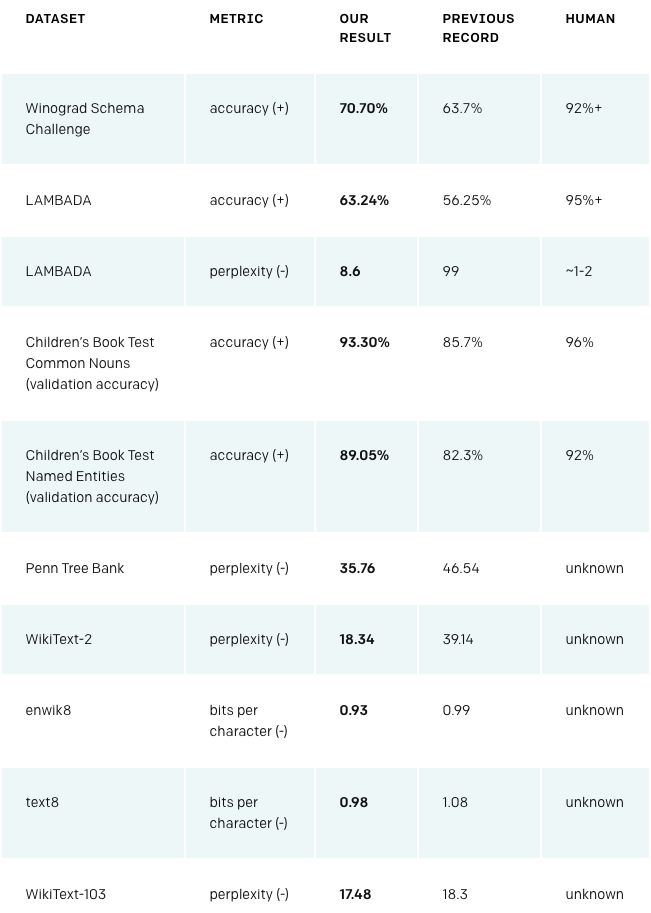
最终结果:8个数据集中油7个刷新当前最佳纪录。
下表显示了最先进的zero-shot结果。(+)表示该项分数越高越好。(-)表示分数越低越好。
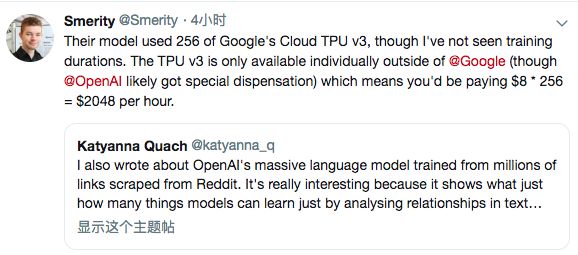
虽然OpenAI没有在论文中提及具体的计算力及训练时间,但通过公布的数据推测,他们的模型使用了256个谷歌云TPU v3。
TPU v3在Google之外只提供单独使用版本(排除OpenAI可能得到了特别的许可),很可能GPT-2训练时所需的成本将高达8 * 256 = 2048美元/小时,相当于一小时烧掉一台512G的iPhone Xs Max。
然而,OpenAI并没有公布GPT-2模型及代码,只是象征性的公布了一个仅含117M参数的样本模型及代码,相当于他们宣称使用的数据量的0.29%。(有兴趣的读者可以去 https://github.com/openai/gpt-2 查看)
OpenAI给出的理由是:因为这个模型能力太强大了!他们目前还有点hold不住它。一旦开源后被坏人拿到,将会贻害无穷。有点中国武侠小说里,绝世武功秘籍的意思。
面临着实验重现的危机,网友吐槽:不公开代码和训练集就干脆别发表!
于是开发者和学者们不干了,纷纷质疑OpenAI这种做法显得心口不一。甚至盛产吐槽大神的Reddit上,有人建议OpenAI干脆改名CloseAI的言论,获得了数百网友的点赞。
OpenAI干脆改名“CloseAI”算了!

我也做了个超强大的MNIST模型,要不要担心它被滥用而不公开呢?

更有甚者,比如下面这位Ben Recht,还发了一条Twitter长文进行嘲讽:

今天我要介绍我们的论文“Do ImageNet Classifiers Generalize to ImageNet?”我们尝试按照原论文描述复现其结果,但发现这样做实在太难!
……我们完全可以基于一个不能公开的数据集构建一个超大模型,在我们自己的标准ML范式中很难发生过拟合。
但是,测试集上的一个微小改动就会导致分布结果大幅变化,你可以想见把模型和代码全都公布出来以后会发生什么!
PS 这篇论文还在arxiv等候审核发布,要不是我们的最终版PDF过大,那就是因为arxiv也学着OpenAI的做法,觉得AI/ML研究太过危险而不能公开。
因为人工智能这个蓬勃发展的领域正面临着实验重现的危机,AI研究者发现他们很难重现许多关键的结果。
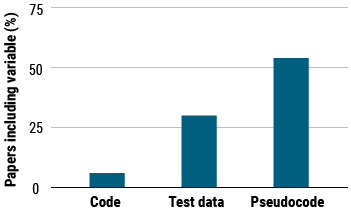
针对主要会议上发表的400篇AI论文的调查显示,只有6%的论文包含算法的代码,约30%包含测试数据,54%包含伪代码。
CREDITS: (GRAPHIC) E. HAND/SCIENCE; (DATA) GUNDERSEN AND KJENSMO, ASSOCIATION FOR THE ADVANCEMENT OF ARTIFICIAL INTELLIGENCE 2018
去年,加拿大蒙特利尔大学的计算机科学家们希望展示一种新的语音识别算法,他们希望将其与一名著名科学家的算法进行比较。
唯一的问题:该benchmark的源代码没有发布。研究人员不得不从已公开发表的描述中重现这一算法。
但是他们重现的版本无法与benchmark声称的性能相符。蒙特利尔大学实验室博士生Nan Rosemary Ke说:“我们尝试了2个月,但都无法接近基准的性能。”
另外一群人更担心GPT-2会导致假新闻出现井喷。OpenAI也拿DeepFake举了个例子。
DeepFake由于其强大的图像生成能力,成了一个“假脸生成器/换脸器”,制造出大量恶意的虚假视频、音频和图像,最终被禁用。
比如这次,不怀好意的人完全可以借助GPT-2,发布有关Elon的假新闻,说他虽然公开宣称去年就退出OpenAI,但实际上私下还在OpenAI身居要职,恐怕也会有很多人相信。
技术是把双刃剑,越是强大的技术,一旦被用于坏用途,约可能造成更坏的结果。那么在这场意外掀起的激烈争论中,你站在哪一边呢?
-
人工智能
+关注
关注
1792文章
47396浏览量
238902 -
马斯克
+关注
关注
1文章
825浏览量
21358 -
nlp
+关注
关注
1文章
489浏览量
22052
原文标题:史上最强AI被喷,马斯克躺枪发推:我早就看不惯OpenAI
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI发布o1大模型,数理化水平比肩人类博士,国产云端推理芯片的新蓝海?
OpenAI世界最贵大模型:昂贵背后的技术突破
OpenAI启动12天新品发布盛宴


余承东称史上最强大的Mate11月见
安全政策遭质疑 OpenAI解散AGI团队
Orion模型即将面世,OpenAI采用新发布模式
nlp神经语言和NLP自然语言的区别和联系
OpenAI竞争对手Anthropic发布最强大模型Claude 3.5 Sonnet
新火种AI|OpenAI要和苹果合作了?微软有些不高兴






 工商网监
工商网监
评论