 机器学习在嵌入式系统中的应用
机器学习在嵌入式系统中的应用
机器学习已从一个有趣的研究课题迅速发展成为广泛应用的有效解决方案。它显而易见的有效性迅速吸引了人工智能理论学者群体之外的开发者社区的兴趣。在某些方面,机器学习开发能力已经扩展到其它基于强大理论基础的技术应用层面。
要开发有价值、高精度的机器学习应用绝非易事。尽管如此,不断增长的机器学习生态系统已经大大减少了对底层算法深入理解的要求,并使机器学习开发越来越容易被嵌入式系统开发人员使用,而不仅仅是理论上的研究。本文着重介绍一些神经网络模型开发中使用的主要概念和方法,机器学习本身是一个非常多样化的领域,目前只有一种实用的机器学习方法可供嵌入式开发人员使用。
任何基于高深理论的方法都遵循从研究到工程的发展模式,机器学习也是一样。就在不久前,希望实现三相交流感应电机精确控制的开发人员需要自己找出解决方案来处理相关的微分方程组。如今,开发人员可以使用库来快速实现先进的运动控制系统,这些库使用非常先进的技术(如磁场定向控制、空间矢量调制和梯形控制等)集成完整的电机控制解决方案。除非遇到特殊要求,开发人员通常无需深入了解底层算法或其特定的数学方法,即可部署复杂的电机控制解决方案。运动控制研究人员继续用新的理论技术发展这门学科,但开发人员可以开发有用的应用,依靠库来抽象底层方法。
在某些方面,机器学习已达到类似的阶段。机器学习算法研究及专用硬件的发展在持续进步当中,如果工程师在理解其相关要求和当前局限的情况下进行处理,这些算法的应用便可成为一种实用的工程方法。在这种情况下,机器学习可以提供有用的结果,不需要高级线性代数专业知识,只要对目标应用数据有正确的理解,并且愿意接受比传统软件开发经验更具实验性的开发方法。对机器学习基础感兴趣的工程师会发现他们对细节的偏爱可以得到满足。然而,那些没有时间或兴趣探索理论的人会发现有一个不断扩大的机器学习生态系统,可以帮助他们简化有用的机器学习应用开发。
机器学习方法
工程师可以找到能够支持广泛类型机器学习的优化库,包括无监督学习、强化学习和监督学习。无监督学习可以揭示出大量数据中的模式,但是这种方法不能将这些模式明确地标记为属于特定类别的数据。尽管本文未涉及无监督学习,但这些技术在物联网应用中可能非常重要,可以揭示数据集中的异常值或表明存在偏离数据趋势的情况。例如,在工业应用中,从一组机器的传感器读数中可以看出,统计上显著偏离正常的现象可以作为该组机器出现潜在故障的指示。类似地,在一个大规模分布式IoT应用中,显著偏离多个性能参数正常值的现象可能揭示出,在数百或数千个设备组成的网络中可能有遭受黑客攻击的设备。
强化学习是一种通过实验进行有效学习的应用方法,利用正反馈(激励)来学习对事件的成功响应。例如,当一个强化学习系统检测到来自一组机器的异常传感器读数时,可能试图通过采取不同的动作(例如增加冷却剂流量、降低室温、减少机器负载等)来校正,以便将这些读数恢复到正常。在了解到哪个动作达到期望的结果后,强化学习系统在下次遇到相同的异常读数时就可以更快地执行相同的操作。虽然本文不探讨这种方法,但强化学习可能会在大规模复杂应用(如物联网)中得到越来越广泛的应用,因为在这些应用中所实现的运行状态都不能有效地预测。
监督学习
监督学习方法消除了在识别哪组输入数据对应于哪个特定状态(或对象)时进行的猜测。 利用这种方法,开发人员明确识别出与特定对象、状态或条件相对应的输入值或特征组合。 在一个假设的机器示例中,工程师通过一组由n和x组成的函数来表征要解决的问题,其中x是函数表达式(如x2),而n代表不同的特征参数,比如传感器输入、机器运行时间、最后服务日期、机器年龄和其他可测量参数。然后工程师根据他们的专业知识创建一个训练数据集,即这些特征向量的多个实例(x1 x2 ... xn),每个特征向量都有n个观察值与已知输出状态相关联,标记为y:
(x11, x12, … x1n) ⇒ y1
(x21, x22, … x2n) ⇒ y2
(x31, x32, … x3n) ⇒ y3
…
给定所测量特征值与相应标签之间的已知关系,开发人员就可以为训练集中的每个特征向量(x1k x2k ... xnk)生成预期标签yk的模型(方程组)。在这一训练过程期间,训练算法使用迭代方法,通过调整构成该模型的方程组的参数来最小化预测标签与其实际标签之间的差异。将训练集中的所有样本都训练一次,称为“一次迭代(epoch)”,而每一次epoch都会产生一组新的参数、一组与这些参数相关的新预测标签,以及相关的差异或损失。
针对损失进行绘图,在每次迭代时产生的参数值集合是具有一些最小值的多维表面。该最小值对应于训练集中提供的实际标签与模型推断的预测标签之间的最接近的一致性。因此,训练的目标是调整模型的内部参数以达到最小损失值,使用方法来寻求最小的“下坡”路径。在多维表面上,通过计算每个参数相对于其他参数的斜率 - 即每个参数的偏导数,可以确定导致最佳下坡路径的方向。训练算法通常使用矩阵方法,称为梯度下降,以便在每个epoch通过模型运行训练数据的全部或子集之后来调整模型参数值。为了最小化这种调整的幅度,训练算法将每个步长调整一些值,称为学习速率,这有助于训练过程收敛。在没有受控学习速率的情况下,由于模型参数的过大调整,梯度下降可能超过最小值。在模型达到(或可接受地收敛)最小损失之后,工程师就可以测试模型的标签预测能力。
一旦经过训练和评估,就可以在生产环境中部署合适的模型,作为推理模型来预测实际应用数据的标签。请注意,推理会为训练中使用的每个标签生成一组概率值。因此,用标记为“y1”,“y2”或“y3”的特征向量训练的模型可能在呈现与y1相关的特征向量时产生这样的推断结果,比如“y1:0.8; y2:0.19; y3:0.01”。额外的软件逻辑将监视输出层以选择具有最佳似然值的标签,并将所选标签传递给应用。通过这种方式,一个应用就可以使用机器学习模型来识别一个或其他数据模式,并采取适当的行动。
神经网络的发展
创建精确的推理模型当然是对监督学习过程的回报,该过程能够利用各种基础模型的类型和体系结构。在这些模型类型中,神经网络因其在图像识别、自然语言处理和其他应用领域的成功而迅速普及。实际上,当先进的神经网络在图像识别中显著优于早期算法之后,神经网络架构已经成为这类问题事实上的解决方案。随着GPU等能够快速执行基础计算的硬件的出现,算法开发者和用户可以快速获得这些技术。反过来,有效的硬件平台和神经网络的广泛接受又推动了各种方便开发人员使用的框架,包括Facebook的Caffe2、H2O、英特尔的neon、MATLAB、微软认知工具包、Apache MXNet、三星Veles、TensorFlow、Theano和PyTorch等。结果,开发人员可以轻松地找到合适的环境来评估机器学习,特别是神经网络。
神经网络的开发始于使用任意数量的可用安装选项来部署框架。尽管依赖性通常很小,但所有流行的框架都能够利用GPU加速库。因此,开发人员可以通过安装NVIDA CUDA工具包和NVIDIA深度学习SDK中的一个或多个库[比如用于多节点/多GPU平台的NCCL(NVIDIA集体通信库)或NVIDIA cuDNN(CUDA深度神经网络)库]来大幅提高计算速度。机器学习框架在GPU加速模式下运行,可充分利用cuDNN针对标准神经网络例程的优化实现,包括卷积、池化、规范化和激活层。
无论是否使用GPU,框架的安装都很简单,通常需要为这些基于Python的软件包安装pip。例如,要安装TensorFlow,可以使用与任何Python模块相同的Python安装方法:
pip3 install --upgrade tensorflow
(或仅适用于Python 2.7环境)
此外,开发人员可能希望添加其他Python模块以加速不同方面的开发。例如,Python pandas模块提供了一个功能强大的工具,用于创建所需的数据格式,执行不同的数据转换,或者只处理机器学习模型开发中经常需要的各种数据整理操作。
经验丰富的Python开发人员通常会为Python开发创建一个虚拟环境,例如,流行的框架都可以通过Anaconda获得。开发人员可以使用容器技术来简化devops,也可以找到其所用框架内置的合适容器。例如,TensorFlow在Dockerhub上的Docker容器中就支持两个版本,一个是仅支持CPU的,一个是支持GPU的。Python wheel档案中也提供了一些框架。例如,Microsoft在CPU和GPU两个版本中都提供Linux CNTK wheel 文件,开发人员也可以在Raspberry Pi 3上找到用于安装TensorFlow的wheel 文件。
数据准备
虽然设置机器学习框架已经比较简单,但真正的工作始于选择和准备数据。如前所述,数据在模型训练中起着核心作用,因此决定着一个推理模型的有效性。之前未提及的事实是,训练集通常包括数十万甚至数百万个特征向量和标签以达到足够的准确度水平。这些数据集的庞大规模使得对输入数据的随意检查变得不可能或基本上无效。然而,糟糕的训练数据直接影响模型质量。错误标记的特征向量、缺失数据,以及“太”干净的数据集可能导致推理模型无法提供准确的预测或很好地归纳。对于整体应用而言可能更糟糕的是,选择统计上不具代表性的训练集预示着模型会因那些缺失的特征向量及其所代表的实体而偏离实际。由于训练数据的重要性以及创建数据的难度很大,业界已经发展了大量的标记数据集,这些数据集可从诸如UCI机器学习库等来源获取。对于仅仅探索不同机器学习算法的开发人员,Kaggle数据集通常可以提供一个很有用的起点。
当然,对于从事独特的机器学习应用开发的组织来说,模型开发需要自己独特的数据集。即使有足够大的可用数据池,标记数据也是一项庞大的工程。实际上,标记数据的过程主要还是人工来完成的。因此,创建一个准确标记数据的系统本身就是一个过程,需要结合心理学理解人类如何解释指令(如标签方式和内容),以及技术支持来加速数据的呈现、标记和验证。Edgecase、Figure Eight和Gengo等公司结合了数据标签多种要求方面的专业知识,提供旨在将数据转化为有用的监督学习培训集的服务。有了一组合格的标记数据,开发人员就需要将数据分成训练集和测试集,通常使用90:10左右的比例进行分割。注意测试集是一个有代表性但又与训练集截然不同的数据集。
模型开发
在许多方面,创建合适的训练和测试数据可能比创建实际模型本身更困难。例如,使用TensorFlow,开发人员可以在TensorFlow的Estimator类中使用内置模型类型来构建模型。例如,单个调用如:
classifier = tf.estimator.DNNClassifier(
feature_columns=this_feature_column,
hidden_units=[4,],
n_classes=2)
使用内置的DNNClassifier类自动创建一个基本的完全连接的神经网络模型(见图1),它包括一个有三个神经元的输入层(支持的特征数量),一个有四个神经元的隐藏层,以及一个有两个神经元的输出层(支持的标签数量)。在每个神经元内,相对简单的激活函数对其输入组合执行一些转换以生成其输出。

图1:最简单的神经网络包括输入层、隐藏层和输出层,而有用的推理依赖于包含大量隐藏层的深度神经网络模型,每个隐藏层包含大量神经元。 (来源:维基百科)
图片翻译:输入层;隐藏层;输出层
为了训练模型,开发人员只需在实例化的估算器对象中调用训练方法 - 在此示例中为classifier.train(input_fn = this_input_function),并使用TensorFlow数据集API通过输入函数提供正确形成的数据(本示例中为this_input_function)。需要这样的预处理或“整形”来将输入数据流转换为具有输入层所期望的维度(形状)的矩阵,但是这一预处理步骤还可能包括数据缩放、归一化以及特定模型所需的任何数量的变换。
神经网络是许多高级识别系统的核心,但实际应用所采用的神经网络,其结构比本示例要复杂得多。这些“深度神经网络”架构具有许多隐藏层,每层都有大量神经元。虽然开发人员可以简单地使用内置的Estimator类来添加更多层及更多神经元,但成功的模型架构往往会混合不同类型的层和功能。
例如,AlexNet是一种卷积神经网络(CNN)或ConvNet,它在ImageNet竞赛(以及之后的许多图像识别应用)中引发了CNN的广泛使用,共有八层(见图2)。每层包含非常多的神经元,在第一层中有253440个,第二层及以后依次为186624、64896、64896、43264、4096、4096和1000个神经元。不是使用观察数据的特征向量,ConvNets扫描图像通过一个窗口(n×n像素滤镜),移动窗口几个像素(步幅)并重复该过程,直到图像被完全扫描。每个过滤结果都通过ConvNet的各个层来完成图像识别模型。
图2:AlexNet演示了使用深度卷积神经网络架构来降低图像识别中的错误率。 (来源:ImageNet大规模视觉识别竞赛)
图片翻译:步幅4;最大池化;密集矩阵
即使采用这种“简单”配置,与前一年的领先解决方案相比,使用CNN可以显著降低ImageNet大规模视觉识别竞赛(ILSVRC)中的前5个错误。 (前5个错误是一个常见指标,表示在该模型的输入数据对可能标签的前五个预测中,不包括正确标签的推断百分比。)在随后的几年中,领先的参赛作品显示了层数的急剧增加,以及前5个错误显著减少(图3)。
图3:由于AlexNet在2012年大幅降低了ImageNet前5个错误率,因此ILSVRC中表现最佳的模型架构具有更深层次的模型架构。 (来源:计算机视觉基金会)
图片翻译:ImageNet分类前5个错误率(%);层;
模型开发
开发人员可以使用任何流行的框架来创建ConvNets和其他复杂的自定义模型。使用TensorFlow,开发人员使用方法调用逐层构建ConvNet模型,以构建卷积层,使用池化层聚合结果,并对结果进行标准化,通常重复该组合以根据需要创建尽可能多的卷积层。实际上,在设计用于完成CIFAR-10分类集的ConvNet的TensorFlow演示中,前三层是使用三种关键方法构建的:tf.nn.conv2d、tf.nn.max_pool和tf.nn.lrn:
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights',
shape=[5, 5, 3, 64],
stddev=5e-2,
wd=None)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
模型训练
开发人员使用清单1中所示的训练方法来训练完整的TensorFlow模型。
其中,train_op引用cifar10类对象的训练方法来执行训练,直到满足开发人员在其他地方定义的停止条件。 cifar10训练方法处理实际的训练周期,包括损失计算、梯度下降、参数更新,以及将指数衰减函数应用于学习率本身(清单2)。
def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
global_step = tf.train.get_or_create_global_step()
# Get images and labels for CIFAR-10.
# Force input pipeline to CPU:0 to avoid operations sometimes ending up on
# GPU and resulting in a slow down.
with tf.device('/cpu:0'):
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate loss.
loss = cifar10.loss(logits, labels)
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
train_op = cifar10.train(loss, global_step)
class _LoggerHook(tf.train.SessionRunHook):
"""Logs loss and runtime."""
def begin(self):
self._step = -1
self._start_time = time.time()
def before_run(self, run_context):
self._step += 1
return tf.train.SessionRunArgs(loss) # Asks for loss value.
def after_run(self, run_context, run_values):
if self._step % FLAGS.log_frequency == 0:
current_time = time.time()
duration = current_time - self._start_time
self._start_time = current_time
loss_value = run_values.results
examples_per_sec = FLAGS.log_frequency * FLAGS.batch_size / duration
sec_per_batch = float(duration / FLAGS.log_frequency)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), self._step, loss_value,
examples_per_sec, sec_per_batch))
with tf.train.MonitoredTrainingSession(
checkpoint_dir=FLAGS.train_dir,
hooks=[tf.train.StopAtStepHook(last_step=FLAGS.max_steps),
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement)) as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
清单1:在这一来自TensorFlow CIFAR-10 ConvNet的演示示例中,TensorFlow会话mon_sess运行方法执行训练周期,引用cifar10实例本身包含的损失函数和其他训练参数。 (来源:TensorFlow)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
decay_steps,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
tf.summary.scalar('learning_rate', lr)
# Generate moving averages of all losses and associated summaries.
loss_averages_op = _add_loss_summaries(total_loss)
# Compute gradients.
with tf.control_dependencies([loss_averages_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)
# Apply gradients.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
清单2:在TensorFlow CIFAR-10 ConvNet实现中,cifar10对象执行梯度下降,使用指数衰减计算损耗,并更新模型参数。 (来源:TensorFlow)
TensorFlow方法提供了强大的功能和灵活性,但代码可以说是比较笨拙的。 好消息是,Keras作为一个更直观的神经网络API,可以运行在TensorFlow之上。使用Keras,开发人员只需几行代码即可构建CIFAR-10 ConvNet,比如添加所需的层、激活函数、聚合(池)等(见清单3)。
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
清单3:Keras提供了一种逐层构建ConvNet模型的直观方法。 (来源:Keras)
在Keras中定义模型之后,开发人员调用模型的编译方法来指定所期望的损耗计算算法和优化算法(比如梯度下降)。为了训练模型,开发人员称之为模型的拟合方法。 或者,模型的fit_generator方法提供了一种更简单的训练方法,即使用Python的生成器功能对从Keras预处理类生成的批量数据进行处理,以此来训练模型。
要将模型部署到目标设备(如边缘设备),开发人员通常可以从其开发环境中导出模型。 例如,使用TensorFlow,开发人员可以使用TensorFlow freeze_graph.py实用程序,以pb格式导出模型,这是一种基于Google协议缓冲器的序列化格式。在目标设备中,开发人员可以使用TensorFlow C ++ API创建TensorFlow运行会话、加载pb文件,并使用应用输入数据运行它。对于能够使用容器的目标平台,开发人员通常可以在Docker Hub上找到他们喜欢的框架的Docker容器,添加他们的模型执行应用程序,并将应用程序容器导出到他们的目标平台。在实践中,重新部署模型的过程需要额外注意,特别在将从开发环境中提取训练数据而构建的功能更换为专门为生产环境的数据处理而优化的功能时。
开发方法
TensorFlow、Keras和其他神经网络框架显著简化了构建复杂模型的任务,但创建一个有效地满足设计目标的模型完全是另一回事。与传统的软件开发不同,开发有效的模型可能需要更多的推测来尝试不同的解决方案,以便“看出哪种方案可行”。研究人员正在积极研究能够创建优化模型的算法,但神经网络优化的一般定理仍然难以捉摸。就此而言,创建模型没有通用的最佳实践或启发式方法:每个应用在前端都有其独特的数据特征,而在后端都有性能、准确性和功耗的独特要求。
一种有效的方法是自动化模型构建工具,例如Google的Cloud AutoML,它使用迁移学习和强化学习在特定领域找到良好的模型架构。到目前为止,Google已经发布了一款还处于早期测试阶段的产品AutoML Vision。虽然没有立即出现,但自动化模型构建工具的出现将是不可避免的。因为AI工具供应商在争夺机器学习的主导地位,想借此改变游戏规则,因此,AutoML类工具仍然是一个活跃的研究课题。
与此同时,云服务提供商和框架开发人员也在不断改进更直接的功能,以简化机器学习解决方案的开发。开发人员可以使用TensorFlow调试器等工具深入了解模型和TensorBoard的内部状态,以便更轻松地可视化和探索复杂的模型拓扑和节点交互。例如,TensorBoard提供了损失与epoch的交互式视图,可以对模型有效性和学习速率适用性做出早期衡量(见图4)。
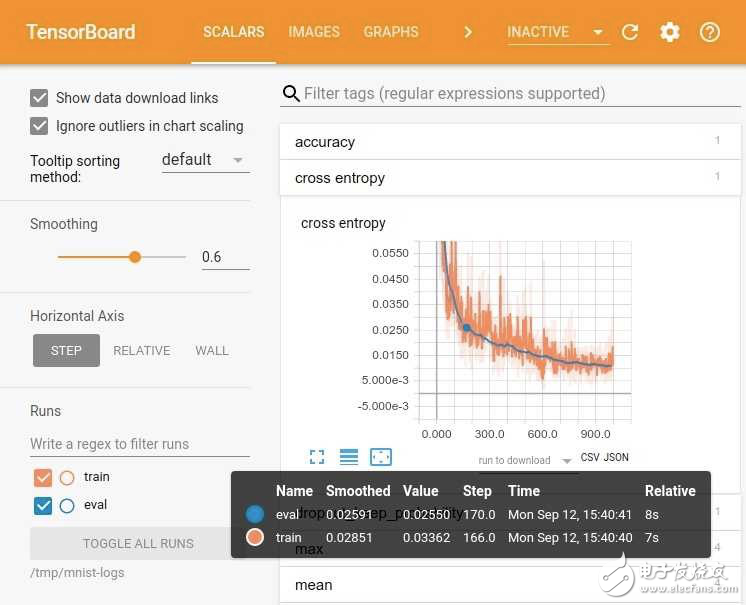
图4:TensorBoard帮助开发人员可视化模型内部结构和训练过程,显示损失函数(此处使用损失函数的交叉条目)与epoch的关系。 (来源:TensorFlow)
最终,找到最合适的架构和配置是经验和反复试错的结果。即使是最有经验的神经网络研究人员也建议找到最佳机器学习架构和特定拓扑结构的方法是尝试,看看哪种方法效果最好。从这个意义上说,神经网络发展与传统应用开发有很大不同。不要期望对模型编码后,就万事大吉了,经验丰富的机器学习开发人员,特别是神经网络开发人员,会将每个模型构建视为一个试验,使用不同的模型架构和配置运行多个实验,以找到最适合自己应用需要的模型。
然而,开发人员可以利用框架提供商和开源社区提供的大量预建模型来加速模型开发过程。预构建模型带有通用数据集,甚至特定应用的数据集,但很少有开发人员所期望模型的最佳选择。然而,采用迁移学习方法,这些模型不仅可以加速开发,而且得到的结果通常比使用自己的数据集来训练初级模型更好。实际上,开发人员可以从很多渠道找到开源的预训练模型,比如Caffe2 Model Zoo、Microsoft CNTK Model Gallery、Keras和TensorFlow等。
平台要求
然而,即使可用的模型创建技术数量不断增加,模型选择的关键约束仍然是目标平台的性能。为多GPU系统而设计的模型,将无法在基于通用处理器的系统上有效运行。如果没有适当的硬件支持,通用处理器无法快速完成主导机器学习算法的矩阵乘法计算(图5)。
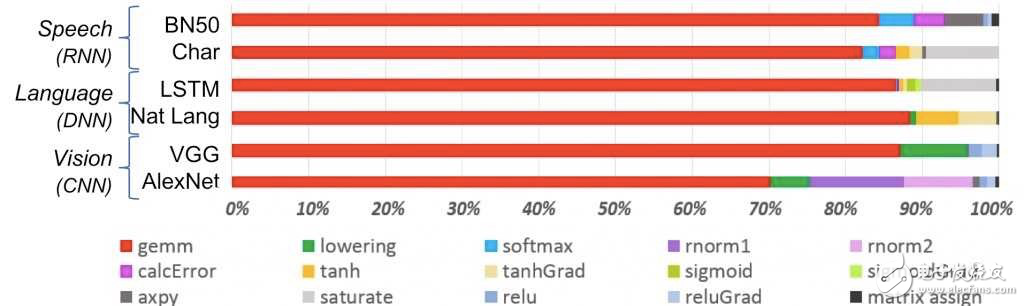
图5:通用矩阵乘法(gemm)计算是一般机器学习的主要方式,特别是神经网络架构。 (来源:IBM)
尽管如此,开发人员仍然可以使用前面提到的TensorFlow for Raspberry Pi的版本来开发神经网络模型,能够在Raspberry Pi这样的系统上运行。更普遍地,Arm的计算库提供了针对Arm Cortex-A系列CPU优化的机器学习功能,比如Raspberry Pi 3使用的CPU就是Arm处理器。开发人员甚至可以使用Arm的CMSIS-NN为Arm Cortex-M7 MCU创建普通但有效的神经网络库。实际上,Arm介绍过一个示例,NUCLEO Mbed板上的标准216 MHz Cortex-M7处理器,就可以支持为CIFAR-10预先构建的Caffe ConvNet,运行后,它可以在合理的时间内完成推理(图6)。
图6:Arm展示Caffe CIFAR-10 ConvNet模型能够在标准Arm Cortex-M7处理器上运行。 (来源:Arm)
FPGA可以提供重要的性能升级和快速开发平台。例如, Lattice 半导体公司的SensAI平台使用神经网络编译器,能够将TensorFlow pb文件和其他文件编译到Lattice 神经网络IP核上,以便在其FPGA上实现人工智能。
专用的AI设备则更进一步,它们采用专门的硬件来加速面向大众市场的机器学习应用。比如Intel Movidius Neural Compute Stick、NVIDIA Jetson TX2模块和高通Snapdragon模块等硬件设备可让开发人员在各种系统中嵌入高性能机器学习算法。
专门针对AI应用的架构旨在减少CPU-内存瓶颈。例如,IBM在2018年VLSI电路研讨会上描述的AI加速器芯片将用于加速矩阵乘法的处理单元与用于减少片外存储器访问的“暂存存储器”层次结合在一起(图7)。同样地,新兴的高级AI芯片利用各种方法将微架构中的逻辑和存储器合并,以加速AI应用的各种操作。

图7:使用了诸如IBM AI芯片中描述的暂存器内存层次结构等技术的新兴AI芯片架构旨在减少CPU-内存瓶颈的影响。 (来源:IBM)
专用框架和架构
专用硬件旨在充分发挥机器学习的潜力,IC行业继续提供更加强大的AI处理器。与此同时,框架开发人员和机器学习算法专家也在不断寻找优化框架和神经网络架构的方法,以便更有效地支持资源受限的平台,包括智能手机、物联网边缘设备和其他性能一般的系统。虽然Apple Core ML和Android神经网络API都为各自的环境提供了解决方案,但TensorFlow Mobile等框架(及其演化版本TensorFlow Lite)提供了更通用的解决方案。
模型结构本身在不断发展,以解决嵌入式设备的资源限制。SqueezeNet就是通过挤压模型架构的元素,从而显著减少了模型大小和参数。MobileNet采用不同的架构方法,可达到与其他方法相当的top-1 精度,但所需要的乘法-加法操作却少得多(图8)。机器学习公司Neurala使用自己的独创方法开发出很小的模型,但仍然能够达到很高的精度。

图8:Google的MobileNet等专用模型架构通过减少资源受限的嵌入式应用所需的矩阵乘法-加法运算,仍可提供具有竞争力的精度。
算法和工具的融合减少了从头构建机器学习模型的需要。开发人员利用越来越强大的框架和工具,更多地在预先构建的模型上开发,来满足他们自己的独特需求。因此,开发人员可以在流行的平台上部署推理模型,以执行图像识别等简单任务。利用同样的技术来创建有用的高性能生产模型绝非易事,但任何开发人员都非常容易获得和使用。随着专用AI硬件在低功耗系统中的发展,机器学习很可能成为嵌入式开发人员常用的开发工具。
-
机器学习
+关注
关注
66文章
8422浏览量
132714
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论