 讲真,AI研究发表和模型开源,真的该制定一个规范了
讲真,AI研究发表和模型开源,真的该制定一个规范了
深度学习界“最敢说的人”Yann LeCun再次放话,不过今天是提问:要是他早先能够预料到如今CNN被滥用,比如制作DeepFake换脸假视频,他当初还该不该开源CNN?讲真,AI研究发表和模型开源,真的该制定一个规范了。
Yann LeCun今天在Twitter上提问:
讲真,要是当初知道卷积神经网络(CNN)会催生DeepFake,我们还要不要发表CNN?
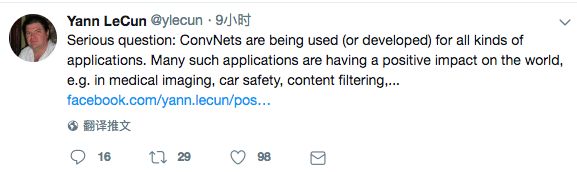
LeCun说:“问个严肃的问题:卷积神经网络(CNN)被用于(或开发)各种各样的应用。很多这样的应用对世界起到了积极影响,例如,医疗影像、汽车安全、内容过滤、环境监控等等。
“但有的应用则可能起到负面的效果,或者说侵犯隐私,例如,公众场所的人脸识别系统、进攻性武器,以及有偏见的“过滤”系统……
“那么,假设在上世纪80年代那时我们能够预见CNN的这些负面影响,我们该不该把CNN模型保密不公开呢?
“几点想法:
最终,CNN(或者类似的东西)还是会被其他人发明出来(实际上,有些人可以说差不多已经做到了)。其实,福岛邦彦就跟我说,他80年代末的时候正在研究一种用BP训练的新认知机(Neocogitron),但看到我们1989年发表的神经计算论文“大感震惊”(shocked),然后停止了他的项目。
开源CNN或深度学习软件平台直到2002年才出现(CNN是20世纪90年代早期商业软件包SN和2002年开源的Lush软件包的一项功能。20世纪90年代中后期才开始有OSS分发)。因此,在某种程度上,CNN直到2002年才完全发表(released)。但那时基本没有什么人关注CNN,或者想到用Lush来训练CNN。”
LeCun的这番话,可以说是为他此前的“表态”做出了完美的解释。
是的,这里说的还是关于OpenAI模型开源的那件事。
LeCun:担心模型太强大而不开源,干脆别研究AI
2月中旬,OpenAI宣布他们开发了一个通用文本生成模型GPT-2,拥有15亿参数,使用了800万网页进行训练,能够同时完成文本生成、回答问题、总结摘要、机器翻译等多项任务,有的时候效果甚至比专门的文本生成/问答/摘要总结等模型还要好。
接着,OpenAI用一个又一个的示例,充分展示了GPT-2模型有多强大,等到众人迫不及待地要了解设计细节时,突然话锋一转,说他们担心模型“太过强大”,开源后可能遭人滥用,这次决定不公布具体参数和训练数据集,只是放出一个小很多的样本模型供人参考。
谁料,OpenAI这一举动引爆了整个AI圈,相比GPT-2模型本身,对于模型是否该开源的争论在短时间内得到了更多的关注,NLP领域以外的研究人员和开发者也凑过来,而且“群众的意见”几乎是一边倒的反对OpenAI,简而言之:
担心AI过于强大而不开源太矫情,这样还不如一开始就别研究AI。
当时,LeCun不仅转发了一条讽刺OpenAI的推文,还“火上浇油”地写了个段子,大意是:可不能开源在MNIST数据集上精度99.99%的模型,这可能被人用来篡改邮编,发动垃圾邮件恐怖袭击,那还得了。具体见下:
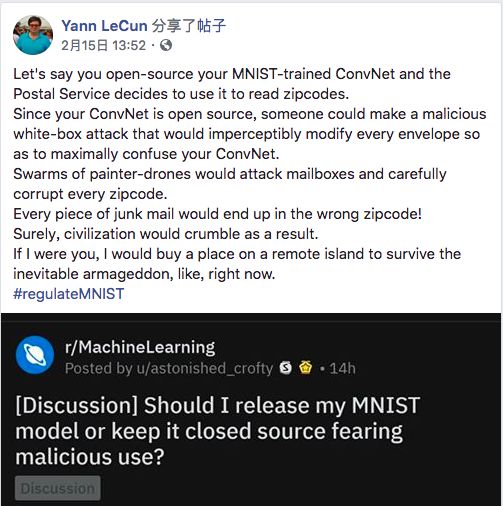
最终,LeCun对OpenAI不予开源的嘲讽发展到了极致:
“每个新生出来的人都可能造谣、传播流言并影响其他人,那我们是不是该别生孩子了?”
这番言论实在称不上严谨,甚至不能算“严肃”,但作为Facebook首席科学家、卷积神经网络发明人和深度学习三巨头之一,LeCun在如今的AI圈子里拥有巨大的影响力,他的这一表态迅速成为重磅砝码,压在了天平“反对不开源”的这边,不仅坚定了此前站出来表示反对的人的信念,还影响了不少后来人的观点。
关于模型开源,我们真正关注的应该是什么?
当然,现在业界的重点已经从最初的口水战聚焦到AI研究发表和开源政策的讨论上来。
LeCun或许也是希望用今天这个“serious question”来阐述自己当初过于简单而容易被人误会的表态。
大多数研究人员都同意,OpenAI决定不开源的出发点是好的,但给出的理由却不尽人意:
首先,GPT-2模型是否真有那么强大?不公布细节无法证明这一点。这也是一开始口水战的一大焦点,如果不给出细节,谁都可以站出来说我实现了强AI,但由于“担心太过强大”,所以我不能发表。
插一句,从OpenAI公布的统计数据中可以看出,GPT-2不仅仅是“记住了”数据,而是确实具有更强的泛化性能。
其次,公开了模型设计和训练数据集,是否就会被人拿去在网上“假言惑众”?先抛开结果复现程度,但看训练成本——OpenAI并没有介绍训练GPT-2模型的时间,但根据知情的研究人员透露,OpenAI取得了特许,使用谷歌TPU来训练模型,1小时花费2048美元。这个费用不是一般人能承担得起的,而能承担起这种费用的,如果真要“作恶”,有大概率不需要借助开源模型。
最后,关于企业研究机构如何宣传AI研究,如何面对公众、媒体和研究人员等不同群体,OpenAI的做法也有一些争议。DeepMind在最初介绍WaveNet,一个能合成与真人语音几乎无二的强大语音生成模型的时候对于潜在危险只字不提,而OpenAI不但主动提出并且还想要牵头制定AI研究发表的相关政策。这里说不出谁对谁错,但OpenAI只给出一个邮箱地址,欢迎“感兴趣的研究人员”联系他们的做法是远远不够的。
现在能够肯定的是,关于AI研究发表和模型开源,相关的政策真的需要制定了。OpenAI在担心模型被滥用时举了DeepFake为例,DeepFake是基于CNN构建的图像生成模型,由于强大的图像生成能力,能够生成以假乱真的人脸,甚至骗过先进的人脸识别模型。
那么回到LeCun一开始问的那个严肃的问题:
要是当初知道卷积神经网络(CNN)会催生DeepFake,我们还要不要发表CNN呢?
-
AI
+关注
关注
87文章
30851浏览量
269028 -
深度学习
+关注
关注
73文章
5503浏览量
121153 -
cnn
+关注
关注
3文章
352浏览量
22213
原文标题:LeCun:30年前知道DeepFake,我还该不该开源CNN?
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Meta重磅发布Llama 3.3 70B:开源AI模型的新里程碑





 工商网监
工商网监
评论