 决策神经科学:解决机器人技术中的关键挑战
决策神经科学:解决机器人技术中的关键挑战
通过模仿人类大脑在日常生活中做出决策时使用的策略,可以显著增强机器人智能。最近,科学家们找到了最新观点。
本周五在国内上映的《阿丽塔:战斗天使》又掀起了一波智能热,这部由著导演詹姆斯·卡梅隆(James Cameron)担任编剧和制片的电影,讲述了拥有人类大脑、机械身躯的女主角,不断改变世界、认识自我的故事。
这部背景发生在26世纪的电影,依旧把人类大脑作为承载智慧、情感和决策的关键能力。
而现在,一份来自韩国高等科学技术研究院(KAIST)、剑桥大学、日本国家信息通信技术研究所(NICT)和谷歌DeepMind的联合研究认为,通过模仿人类大脑在日常生活中做出决策时使用的策略,可以显著增强机器人智能,他们的方法是:将神经科学应用于机器人大脑。
最近,这项研究发表在了Science Robotics杂志上。
决策神经科学:解决机器人技术中的关键挑战
人类和自主机器人不断需要学习和适应新的环境。两者的不同之处在于,人类能够根据独特情况做出决策,而机器人仍然依靠预定数据来做出决策,这是目前机器人的短板。
强化学习(RL)成为通过与世界交互来理解决策的主要理论框架,并且最近在构建具有超人类表现的智能体方面取得成功。然而,哪怕是最新的强化算法仍然存在很大的局限性,例如,缺乏制定目标导向策略的能力,或依赖大量经验来学习。
这些限制阻碍了机器人在任务或背景频繁变化的动态环境中快速适应的能力。
相比之下,人类在经验有限的条件下迅速适应环境变化方面具有非凡的能力。决策神经科学(decision neuroscience)的最新发现表明,大脑不仅为RL使用多个控制系统,而且还使用一种灵活的元控制机制(metacontrol mechanism)来选择控制选项,每个不同选项分别与预测性能、认知负荷和学习速度相关。
理解大脑如何实现这些选项可能会让RL算法解决机器人的实际控制问题。
在Science Robotics上发表的研究中,研究人员讨论了人类RL相关的最新发现,这些发现可能会解决机器人技术中的几个关键挑战:性能—效率—速度权衡、多机器人设置中的冲突需求以及探索—开发困境。
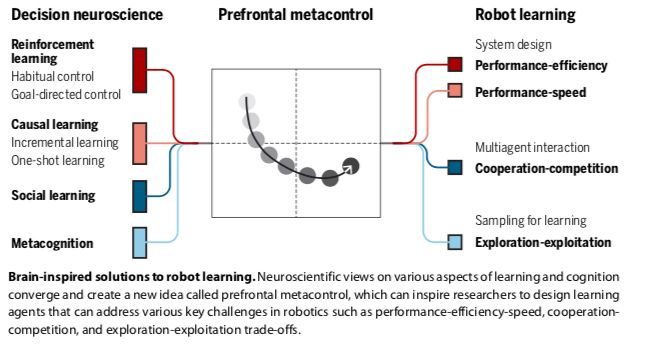
详细解读:元控制可以类似大脑
首先,决策神经科学的证据表明,人类利用两种不同的行为控制策略:
刺激驱动的习惯性(stimulus-driven habitual);
目标导向的认知控制(goal-directed cognitive control)。
习惯性控制是自动且快速的,尽管它在不稳定的环境中很脆弱,并且能由model-free RL很好地解释,model-free RL通过无环境模型下的试错过程来逐步学习行为的价值。
相反,目标导向的控制可以迅速适应环境的变化,但它具有认知需求。它通过学习环境模型来指导行动,并利用这个知识库快速适应环境结构的变化,例如学习状态-行动空间中的潜在(隐藏)原因。
model-based RL和model-free RL之间的这种计算上的区别表明它们之间存在不可避免的妥协。model-free RL学习起来比较慢,但一旦策略被学习并实现自动化,就可以快速地实现目标。model-based RL通常比model-free RL提供更多的准确预测,但计算量要大得多。每种策略都提供了关于准确性、速度和认知负荷的互补解决方案,突出了预测性能和计算效率之间的权衡。
其次,RL算法通常需要大量经验来充分学习不同环境因素下的因果关系(incremental learning)。然而,人类的学习速度很快——通常一个从未经历过的事件发生一次之后就已学习(“one-shot learning”)。
神经科学最近的研究发现,当与环境的交互受到限制时,人类有很强的提高学习速度的倾向;他们会努力迅速弄清环境中未知的部分,即使这会危及安全。这些结果表明,大脑是直接执行计算来寻找性能和速度之间的权衡。
第三,越来越多的证据支持这样一种观点,即前额叶皮层使元控制能够灵活地在不同的学习策略之间进行选择,例如在model-based RL和model-free RL 之间,以及在incremental learning和one-shot learning之间。
在新的环境中,元控制通过选择model-based RL来强调性能。因为这在计算上很昂贵,当大脑发现进一步学习没有什么好处时,就会转向model-free RL:要么环境非常稳定,可以做出精确的预测;要么高度不稳定,以至于基于模型的RL的预测不如无模型RL的预测可靠。
在其他情况下,元控制优先考虑速度。当预估的因果关系中的不确定性很高时,大脑倾向于转换到one-shot学习,以快速解决预测结果中的不确定性。然而,当agent对所有可能的因果关系都同样不确定时,它会重新转向incremental learning以确保安全的学习。
这些机制表明类似于大脑的元控制可以处理性能-效率-速度的权衡。
第四,人类的RL可以解释在人类进化中起重要作用的社会现象。在多主体相互作用的人类社会中,存在着具有部分竞争性和部分一致性激励机制的社会困境。
使用model-based的RL方法成功地在更复杂的时间扩展设置中实现了协作。
人类似乎通过使用元认知(metacognition)来绕过这个问题——元认知是一种评估自己表现的能力,即评估自信和/或不确定性的水平。例如,较低的任务难度或较低的环境噪声会使学习主体自信,从而导致更果断的行动,而失去自信则会导致更谨慎和防御性的策略。元认知学习因此可以快速适应环境的变化,同时保持对环境噪声的鲁棒性。这样的策略有可能增强机器人的决策能力。
总之,将人类决策神经科学的发现整合起来,可以为机器人的动作控制系统提供有价值的见解,从而实现更安全、更有能力、更高效的学习。
对大脑建模,算法能否支撑起意识?
另外,研究团队还认为,这种跨学科的方法也应该引起神经科学的注意,为开发新的人类决策计算理论提供一个可靠的测试基础。
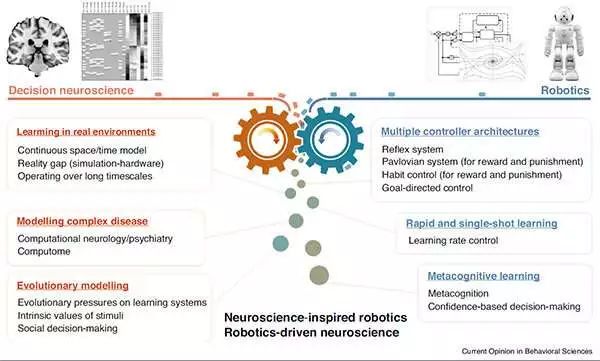
最近对焦虑、抑郁和成瘾等精神疾病背后的兴趣引起了很多人的兴趣,这使得一系列复杂的理论在没有某种先进的情境平台的情况下难以测试。这种情况需要一种对人类大脑进行建模的方法,以找出它在现实生活中如何与世界相互作用,以测试这些模型中的不同异常是否以及如何引起某些疾病。
例如,如果我们可以在机器人中重现焦虑行为或强迫症,那么就可以预测需要做些什么来治疗。研究团队预计,开发不同精神疾病的机器人模型,与研究人员现在使用动物模型的方式类似,将成为临床研究的关键未来技术。
最后再回到电影《阿丽塔》。
电影中所有的机器人都拥有人类的生命、有机大脑。机器人能从脊髓或大脑直接将信号传递到假体中的代码,使截瘫或四肢瘫痪的人能够随着机器人技术的进步再次获得行动能力。
如果放到现在的时代,这种技术看上去非常棒;但电影设定发生在五百年后,AI依然只是作为支撑躯体的技术,核心还是人类的大脑而不是由算法主导意识与行动,看来卡梅隆和罗德里格斯导演的脑洞还是小了点:)
-
控制系统
+关注
关注
41文章
6622浏览量
110614 -
机器人
+关注
关注
211文章
28423浏览量
207139 -
代码
+关注
关注
30文章
4788浏览量
68625
原文标题:Science子刊:为机器人复制脑代码,无限接近人类决策
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「具身智能机器人系统」阅读体验】1.全书概览与第一章学习
《具身智能机器人系统》第7-9章阅读心得之具身智能机器人与大模型
【「具身智能机器人系统」阅读体验】+数据在具身人工智能中的价值
【「具身智能机器人系统」阅读体验】+初品的体验
《具身智能机器人系统》第1-6章阅读心得之具身智能机器人系统背景知识与基础模块
虹科携手Seed Robotics,开启机器人灵巧手合作新篇章

【书籍评测活动NO.51】具身智能机器人系统 | 了解AI的下一个浪潮!
开源项目!用ESP32做一个可爱的无用机器人
开源项目!用ESP32做一个可爱的无用机器人
机器人神经网络系统的特点包括
机器人神经网络控制原理是什么
「探索」康复机器人在神经康复中的应用

其利天下技术·搭载无刷电机的扫地机器人的前景如何?
技术革新--机器人激光焊接机的优势与挑战






 工商网监
工商网监
评论