 机器学习研究中常见的七大谣传总结
机器学习研究中常见的七大谣传总结
在学习深度学习的过程中,我们常会遇到各种谣传,也会遇到各种想当然的「执念」。在本文中,作者总结了机器学习研究中常见的七大谣传,他们很多都是我们以前的固有概念,而最近又有新研究对它们提出质疑。所以在为机器学习填坑的生涯中,快自检这七个言传吧。
谣传一:TensorFlow 是一个张量运算库
事实上,TensorFlow 是矩阵而不是张量运算库,这两者的区别非常大。
在 NeurIPS 2018 的论文 Computing Higher Order Derivatives of Matrix and Tensor Expressions 中,研究者表明,他们基于张量微积分(Tensor Calculus)所建立的新自动微分库具有明显更紧凑(compact)的表达式树(expression trees)。这是因为,张量微积分使用了索引标识,进而使前向模式和反向模式的处理方式相同。
与此相反,矩阵微积分出于标识方便的考虑隐藏了索引,这也通常会导致自动微分的表达式树显得过于复杂。
若有矩阵的乘法运算:C=AB。在前向模式中,有
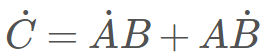
,而在反向模式中,则有
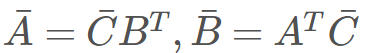
。为了正确完成乘法计算,我们需要注意乘法的顺序和转置的使用。对于机器学习开发者而言,这只是在标识上的一点困惑,但对于程序而言,这是一个计算上的开销。
以下是另一个例子,毫无疑问意义更大一些:对于求行列式 c=det(A)。在前向模式中,有
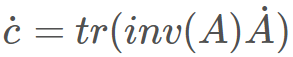
,而在反向模式中,则有
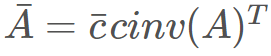
。这里可以明显看出,无法使用同一个表达式树来表示两种模式,因为二者是由不同运算组成的。
总的来说,TensorFlow 和其他库(如 Mathematica、Maple、 Sage、SimPy、ADOL-C、TAPENADE、TensorFlow, Theano、PyTorch 和 HIPS autograd)实现的自动微分方法,会在前向模式和反向模式中,得出不同的、低效的表达式树。而在张量微积分中,通过索引标识保留了乘法的可交换性,进而轻松避免了这些问题(具体的实现原理,请阅读论文原文)
研究者通过反向传播,在三个不同问题上,测试了反向模式自动微分新方法的性能,并度量了其计算 Hessian 矩阵所消耗的时间。
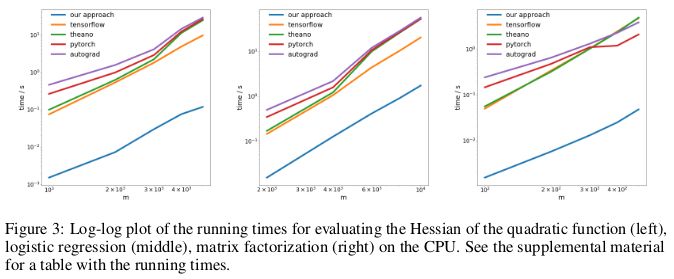
第一个问题是优化一个形如 xAx 的二次函数;第二个问题是求解一个逻辑回归;第三个问题是求解矩阵分解。
在 CPU 上,新方法与当下流行的 TensorFlow、Theano、PyTorch 和 HIPS autograd 等自动微分库相比,要快两个数量级。
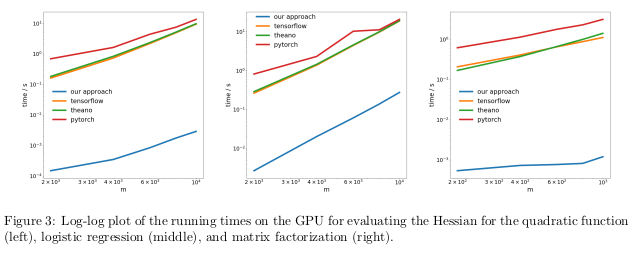
在 GPU 上,研究者发现,新方法的提速更加明显,超出流行库的速度近似三个数量级。
意义:利用目前的深度学习库完成对二次或更高阶函数的求导,所花费的成本比本应消耗的更高。这包含了计算诸如 Hessian 的通用四阶张量(例:在 MAML 中,以及二阶牛顿法)。幸运的是,在「深度」学习中,二阶函数并不常见。但在「传统」机器学习中,它们却广泛存在:SVM对偶问题、最小二乘回归、LASSO,高斯过程……
谣传二:机器学习研究者并不使用测试集进行验证
在机器学习第一门课中,我们会学习到将数据集分为训练集、验证集以及测试集。将在训练集上训练得到模型,在验证集上进行效果评估,得出的效果用以指导开发者调节模型,以求在真实场景下获得效果最好的模型。直到模型调节好之后,才应该使用测试集,提供模型在真实场景下实际表现的无偏估计。如果开发者「作弊」地在训练或验证阶段使用了测试集,那么模型就很可能遇到对数据集偏差产生过拟合的风险:这类偏差信息是无法在数据集外泛化得到的。
在机器学习研究高度竞争的环境下,对新算法/模型的评估,通常都会使用其在测试集上的表现。因此对于研究者而言,没有理由去写/提交一篇测试集效果不 SOTA 的论文。这也说明在机器学习研究领域,总体而言,使用测试集进行验证是一个普遍现象。
这种「作弊」行为的影响是什么?
在论文 DoCIFAR-10Classifiers Generalize to CIFAR-10? 中,研究者们通过在 CIFAR-10 上建立了一个新的测试集,来研究此问题。为此,他们解析标注了来自 Tiny Images 库的图像,就像最初的数据采集过程一样。
常用测试集带来过拟合?你真的能控制自己不根据测试集调参吗
研究者们之所以选择 CIFAR-10,是因为它是机器学习界使用最广泛的数据集之一,也是 NeurIPS 2017 中第二受欢迎的数据集(在 MNIST 之后)。CIFAR-10 数据集的创建过程也有完善公开的文档记录。而庞大的 Tiny Images 库中,也有足够的细粒度标签数据,进而使得在尽量不引起分布偏移的情况下重建一个测试集成为了可能。
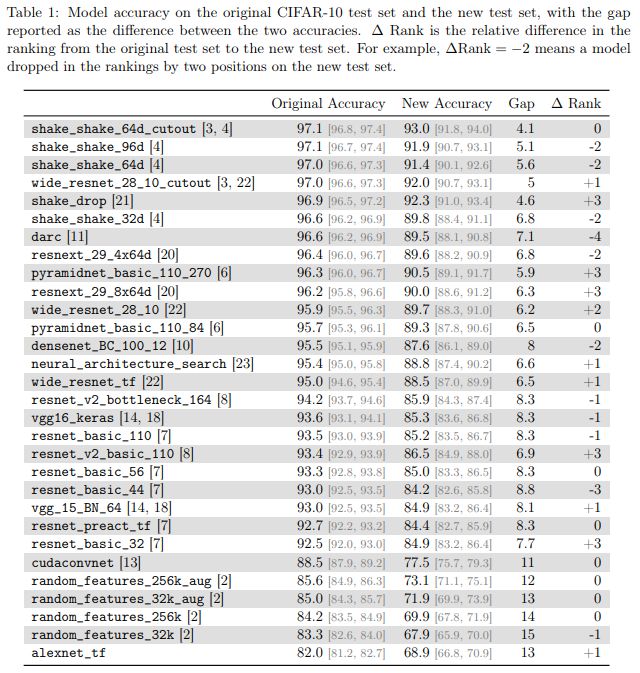
研究者发现,很多神经网络模型在从原来的测试集切换到新测试集的时候,都出现了明显的准确率下降(4% - 15%)。但各模型的相对排名依然相对稳定。
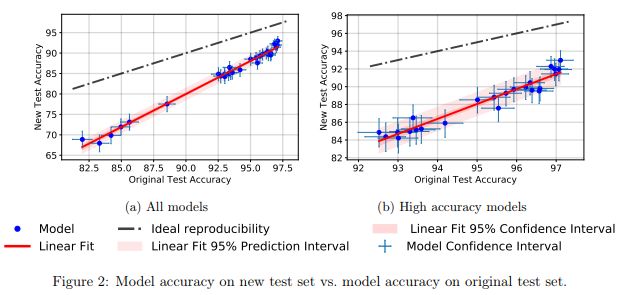
总的来说,相较于表现较差的模型,表现较好模型的准确率下降程度也相对更小。这是一个振奋人心的消息,因为至少在 CIFAR-10 上,随着研究社区发明出更好机器学习模型/方法,由于「作弊」得到的泛化损失,也变得更加轻微。
谣传三:神经网络训练过程会使用训练集中的所有数据点。
有这样一个常见说法,数据是新的原油(财富),数据量越大,我们就能将数据相对不足的、过参数化的深度学习模型训练得越好。
在 ICLR 2019 的一篇论文 An Empirical Study of Example Forgetting During Deep Neural Network Learning 中,研究者们表示在多个常见的较小图像数据集中,存在显著冗余。令人震惊的是,在 CIFAR-10 中,我们可以在不显著影响测试集准确率的情况下剔除 30% 的数据点。
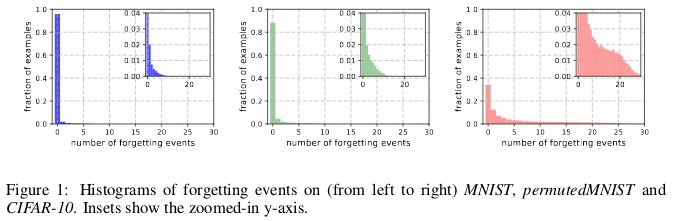
当神经网络在 t+1 时刻给出误分类、而在 t 时刻给出了准确的分类时,就称为发生了遗忘事件(forgetting event)。这里的「时刻」是指训练网络的随机梯度下降(SGD)的更新次数。为了让记录遗忘事件变得可行,研究者每次只在用于完成 SGD 更新的小批量数据上运行神经网络,而不是在数据集的单个样本上运行。对于不会经历遗忘事件的样本,称之为不可遗忘样本(unfogettable example)。
研究者发现,MNIST 中 91.7%、permutedMNIST 中 75.3%、CIFAR-10 中 31.3% 以及 CIFAR-100 中 7.62% 的数据属于不可遗忘样本。这符合直观理解,因为随着图像数据集的多样性和复杂性上升,神经网络理应遗忘更多的样本。
相较于不可遗忘样本,可遗忘样本似乎表现了更多不寻常的独特特征。研究者将其类比于 SVM 中的支持向量,因为它们似乎划分了决策边界。
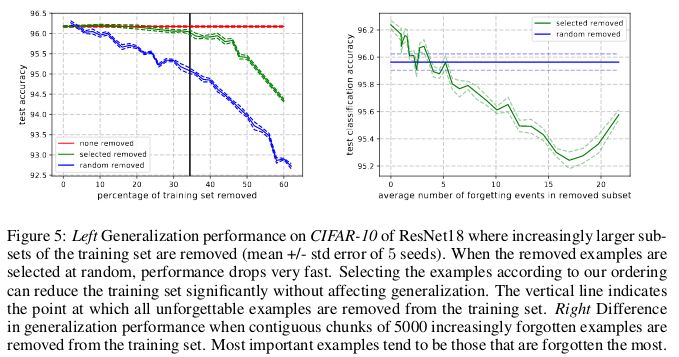
与此相反,不可遗忘样本则编码了绝大部分的冗余信息。如果将样本按其不可遗忘性(unforgettability)进行排序,就可以通过删除绝大部分的不可遗忘样本,而对数据集完成压缩。
在 CIFAR-10 中,30% 的数据可以在不影响测试集准确率的情况下移除,而删除 35% 的数据则会产生 0.2% 的微小测试准确率下降。如果所移除的 30% 数据是随机挑选而非基于不可遗忘性,那么就会导致约 1% 的显著下降。
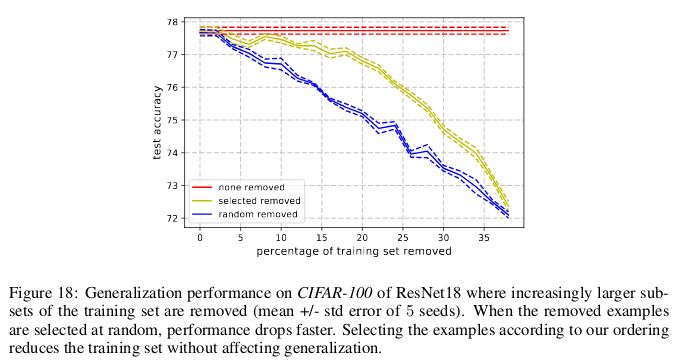
与此类似,在 CIFAR-100 上,8% 的数据可以在不影响测试集准确率的情况下移除。
这些发现表明,在神经网络的训练中,存在明显的数据冗余,就像 SVM 的训练中,非支持向量的数据可以在不影响模型决策的情况下移除。
意义:如果在开始训练之前,就能确定哪些样本是不可遗忘的,那么我们就可以通过删除这些数据来节省存储空间和训练时间。
谣传四:我们需要批标准化来训练超深度残差网络。
长久以来,人们都相信「通过随机初始参数值和梯度下降,直接优化有监督目标函数(如:正确分类的对数概率)来训练深度网络,效果不会很好。」
从那时起,就有很多聪明的随机初始化方法、激活函数、优化方法以及其他诸如残差连接的结构创新,来降低利用梯度下降训练深度神经网络的难度。
但真正的突破来自于批标准化(batch normalization)的引入(以及其他的后续标准化技术),批标准化通过限制深度网络每层的激活值尺度,来缓和梯度消失、爆炸等问题。
值得注意的是,在今年的论文 Fixup Initialization: Residual Learning Without Normalization 中,研究表明在不引入任何标准化方法的情况下,通过使用 vanilla SGD,可以有效地训练一个 10,000 层的深度网络。
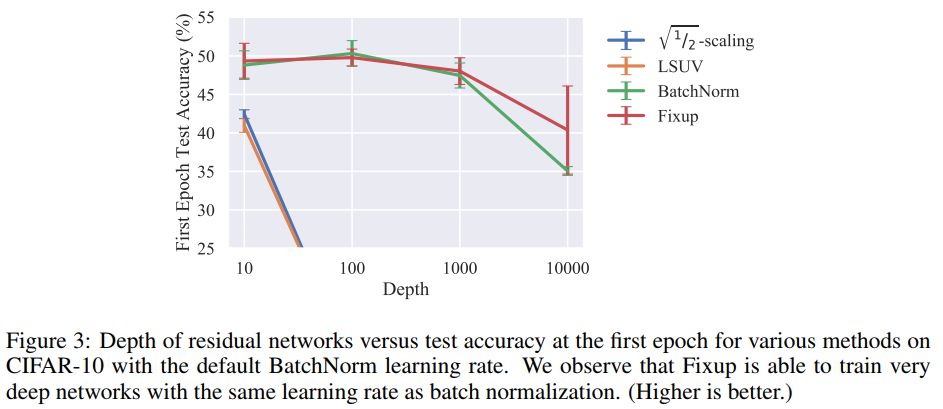
研究者比较了在 CIFAR-10 上,不同深度残差网络训练一个 epoch 的结果。并发现,虽然标准初始化方法在 100 层的网络上失败了,但 Fixup 和批标准化都在 10,000 层的网络上成功了。

研究者通过理论分析,证明了「特定神经层的梯度范数,以某个随网络深度增加而增大的数值为期望下界」,即梯度爆炸问题。
为避免此问题,Fixup 中的核心思想是在每 L 个残差分支上,对 m 个神经层的权重,使用同时依赖于 L 和 m 的因子进行调整。」
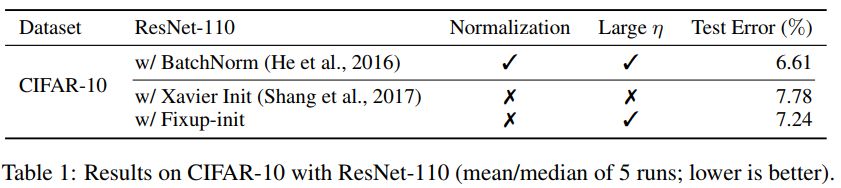
Fixup 使得能够在 CIFAR-10 上以高学习速率训练一个 110 层的深度残差网络,得到的测试集表现和利用批标准化训练的同结构网络效果相当。
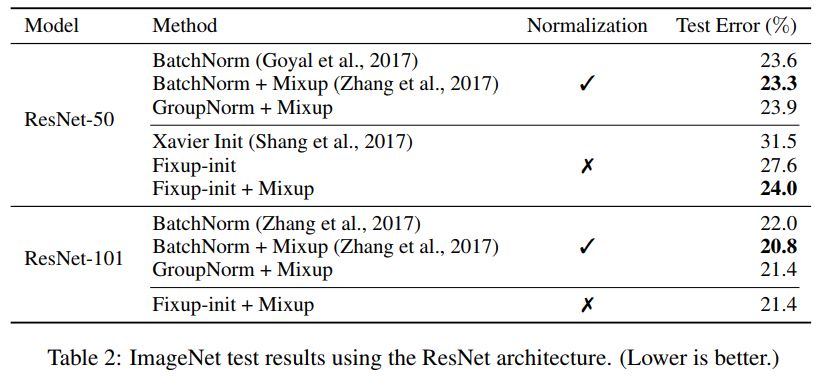
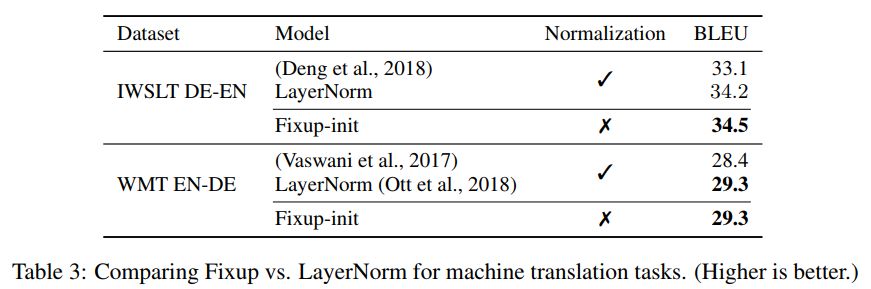
研究者也进一步展示了在没有任何标准化处理下,基于 Fixup 得到的神经网络在 ImageNet 数据集和英语-德语机器翻译任务上相当的测试结果。
谣传五:注意力>卷积
在机器学习领域,有一个正得到认同的说法,认为注意力机制是卷积的更优替代。重要的是 Vaswani et al 注意到「一个可分离卷积的计算成本,和一个自注意力层与一个逐点前馈层结合后的计算成本一致」。
即使是最新的 GAN 网络,也展示出自注意力相较于标准卷积,在对长期、多尺度依赖性的建模上效果更好。
在 ICLR 2019 的论文 Pay Less Attention with Lightweight and Dynamic Convolutions 中,研究者对自注意力机制在长期依赖性的建模中,参数的有效性和效率提出了质疑,他们表示一个受自注意力启发而得到的卷积变体,其参数效率更高。
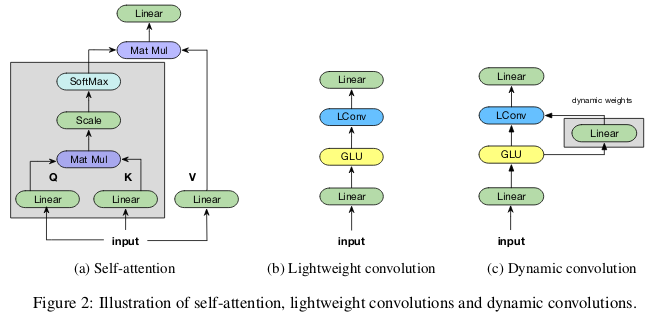
轻量级卷积(lightweight convolutions)是深度可分离(depthwise-separable)的,它在时间维度上进行了 softmax 标准化,通道维度上共享权重,且在每个时间步上重新使用相同权重(类似于 RNN 网络)。动态卷积(dynamic convolutions)则是在每个时间步上使用不同权重的轻量级卷积。
这些技巧使得轻量级卷积和动态卷积相较于传统的不可分卷积,在效率上优越几个数量级。
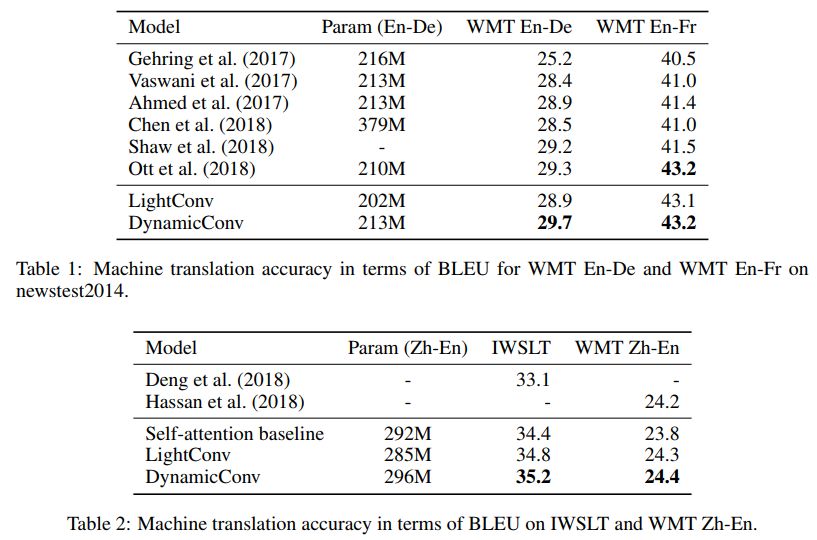
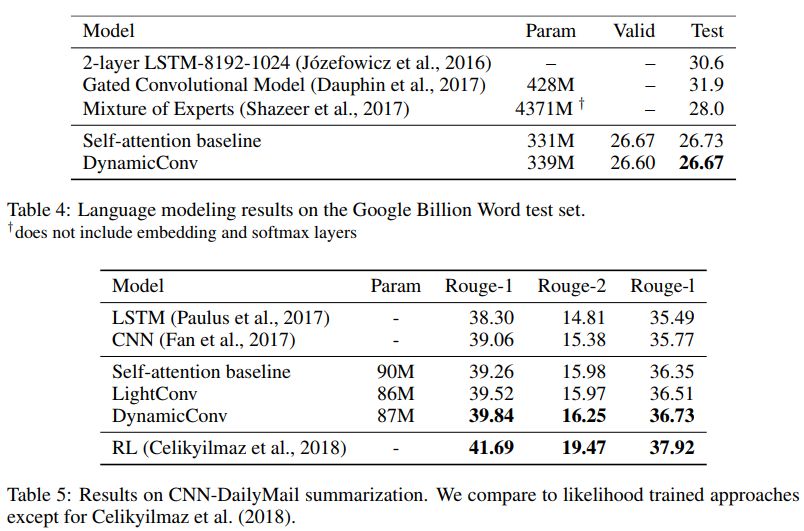
研究者也证明,在机器翻译、语言建模和抽象总结等任务上,这些新卷积能够使用数量相当或更少的参数,达到或超过基于自注意力的基准效果。
谣传六:图像数据集反映了自然世界真实图像分布
我们可能会认为,如今的神经网络在目标识别任务上,效果已经超出真人水平。这并不正确。在 ImageNet 等筛选出来的图像数据集上,它们的效果可能确实优于真人。但对于自然世界的真实图像,它们在目标识别上绝对无法比正常成年人做得更加出色。这是因为,从目前的图像数据集中抽取的图像,和从真实世界整体中抽取的图像并不一样,二者分布并不相同。
这里有一篇 2011 年比较老的论文: Unbiased Look at Dataset Bias,其中,研究者根据 12 个流行的图像数据集,尝试通过训练一个分类器用以判断一个给定图像来自于哪个数据集,来探索是否存在数据集偏差。
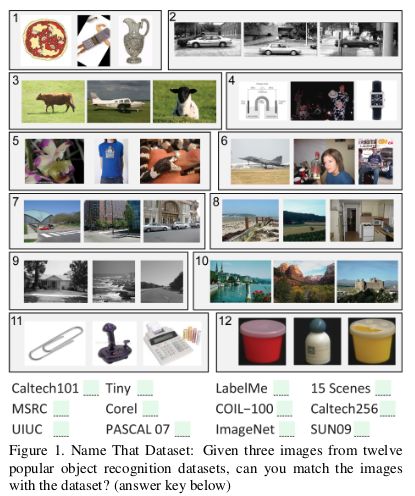
随机猜测的正确率应该是 1/12 = 8%,而实验结果的准确率高于 75%。

研究者在 HOG 特征上训练了一个 SVM,并发现其正确率达到 39%,高于随机猜测水平。如今,如果使用最先进的 CNN 来复现这一实验,很可能得到更好的分类器效果。
如果图像数据集确实能够表征来自自然世界的真实图像,就不应能够分辨出某个特定图像是来自于哪个数据集的。
但数据中的偏差,使得每个数据集变得可识别。例如,在 ImageNet 中,有非常多的「赛车」,不能认为这代表了通常意义上「汽车」的理想概念。
研究者在某数据集训练分类器,并在其他数据集上评估表现效果,进一步度量数据集的价值。根据这个指标,LabelMe 和 ImageNet 是偏差最小的数据集,在「一篮子货币(basket of currencies)」上得分 0.58。所有数据集的得分都小于 1,表明在其他数据集上训练的模型都给出了更低的准确度。在没有数据集偏差的理想情况下,应该有一些得分是高于 1 的。
谣传七:显著图(saliency maps)是解释神经网络的一个稳健方法。
虽然神经网络通常被认为是黑箱模型,现在还是已经有了有非常多对其进行解释的探索。显著图,或其他类似对特征或训练样本赋予重要性得分的方法,是其中最受欢迎的形式。
能够将图像进行特定分类的理由,总结为图像特定部分对模型决策过程中起的作用,是一个非常诱人的课题。已有的几种计算显著图的方法,通常都基于神经网络在特定图像上的激活情况,以及网络中所传播的梯度。
在 AAAI 2019 的一篇论文 Interpretation of Neural Networks is Fragile 中,研究者表明,可以通过引入一个无法感知的扰动,来破坏一个特定图像的显著图。
「帝王蝶之所以被分类为帝王蝶,并不是因为翅膀的图案样式,而是因为背景上一些不重要的绿色树叶。」
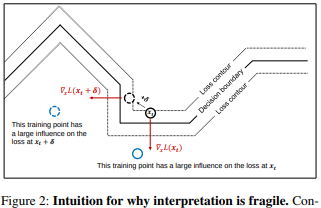
高维图像通常都位于深度神经网络所建立的决策边界附近,因此很容易受到对抗攻击的影响。对抗攻击会将图像移动至决策边界的另一边,而对抗解释攻击则是将图像在相同决策区域内,沿着决策边界等高线移动。

为实现此攻击,研究者所使用的基本方法是Goodfellow提出的 FGSM(fast gradient sign method)方法的变体,这是最早的一种为实现有效对抗攻击而引入的方法。这也表明,其他更近的、更复杂的对抗攻击也可以用于攻击神经网络的解释性。
意义:随着深度学习越来越普遍地应用于高风险场景,如医学成像,对于如何解释神经网络所做的结论也越发重要。例如,虽然 CNN 网络将 MRI 图像上的小点识别为恶性致癌肿瘤是非常好的事情,但如果它们是基于非常脆弱的解释方法,那么也不应姑妄信之。
-
机器学习
+关注
关注
66文章
8453浏览量
133166 -
tensorflow
+关注
关注
13文章
329浏览量
60663
原文标题:机器学习的七大谣传,这都是根深蒂固的执念吧
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

揭秘注塑机快速换模的七大步骤,助力智能制造升级
什么是机器学习?通过机器学习方法能解决哪些问题?


VisionChina2024(深圳)七大议题引领视觉技术跨界融合,部分论坛议程抢先看!
放大电路中常见的噪声有哪些
【「时间序列与机器学习」阅读体验】+ 简单建议
机器学习中的数据分割方法
机器人视觉技术中常见的图像分割方法

机器学习算法原理详解
小度发布首款百度文心大模型学习机
基于FPGA的常见的图像算法模块总结







 工商网监
工商网监
评论