 一种开源的机器学习模型,可在浏览器中使用TensorFlow.js对人物及身体部位进行分割
一种开源的机器学习模型,可在浏览器中使用TensorFlow.js对人物及身体部位进行分割
我们很高兴宣布推出BodyPix,这是一种开源的机器学习模型,可在浏览器中使用TensorFlow.js对人物及身体部位进行分割。默认设置下,该模型可在 2018 版 15 英寸 MacBook Pro 以及 iPhone X 上分别以 25 fps 和 21 fps 的帧率,估测及呈现人物及身体部位的分割。
人物分割究竟是什么?在计算机视觉中,图像分割是指将图像中的像素分成几组特定语义区域以确定对象和边界的技术。研究期间,我们训练 BodyPix 模型对人物及 24 个身体部位(如左手、右前小腿或后背等部位)执行此项操作。换言之,BodyPix 可将图像的像素分为以下两类:1) 表示人物的像素和 2) 表示背景的像素。它还可将表示人物的像素进一步分类为 24 个身体部位中的任一个部位。
若您在此处尝试实时演示,这一切可能会更加明了。
注:此处 链接
https://storage.googleapis.com/tfjs-models/demos/body-pix/index.html
人物分割有何用途?这项技术可广泛应用于多个多领域,包括增强现实、摄影编辑以及图像或视频的艺术效果等。具体应用由您决定!去年,当我们推出PoseNet(首个能够在浏览器中使用简易网络摄像头估测身体部位(Kinect 的功能)的模型)时,人们便对此项技术设想出各类用例。我们希望 BodyPix 也能用于开展同样的创意实验。
为何要在浏览器中执行此操作?与 PoseNet 的情况类似,您过去只能借助专用硬件,或对系统要求严苛且安装难度较高的软件,才能进行实时人物分割。相比之下,您无需执行安装步骤,而仅凭几行代码即可使用 BodyPix 和 PoseNet。使用这些模型时无需任何专用镜头,因为它们能与任何基本的网络摄像头或手机相机配合使用。最后,用户只需打开网址即可访问这些应用。由于所有计算均在设备上完成,因此数据可以保持私密性。鉴于以上所有原因,我们认为,对于艺术家、创意程序员和编程新手而言,BodyPix 是一个可轻松上手的工具。
在深入介绍 BodyPix 之前,我们要感谢 Google Research 团队的Tyler Zhu(此模型的幕后研究员,专攻人体姿势估测)[1,2]、Google Brain 团队工程师Nikhil Thorat与Daniel Smilkov(TensorFlow.js库的幕后研究员),以及Daniel Shiffman,同时还要感谢Google Faculty Research Award为 Dan Oved 的研究工作提供资助。
注:1 链接
https://arxiv.org/abs/1701.01779
2 链接
https://arxiv.org/abs/1803.08225
BodyPix 入门指南
让我们深入了解使用此模型时的技术细节。BodyPix 可用于将图像分割为人物像素和非人物像素。人物像素又可进一步分类为24 个身体部位中的任一部位。重要的是,此模型仅适用于单个人物,因此请确保您的输入数据不包含多个人。
第 1 部分:导入 TensorFlow.js 和 BodyPix 库
让我们回顾一下有关如何建立 BodyPix 项目的基础知识。
您可通过 npm install @tensorflow-models/body-pix 安装此库,然后使用 es6 模块将其导入:
import * as bodyPix from '@tensorflow-models/body-pix'; async function loadAndUseBodyPix() { const net = await bodyPix.load(); // BodyPix model loaded}
您也可通过网页中的软件包将其导入,而无需执行任何安装步骤:
bodypix.load().then(function(net) { // BodyPix model loaded });
第 2a 部分:人物分割
应用于图像的人物分割算法示例。图像来源:“Microsoft Coco:Common Objects in Context Dataset”,http://cocodataset.org
在基础层面,人物分割将图像分割为人物像素和非人物像素。但实际过程并非如此简单,图像在输入模型后会转化为二维图像,其中每个像素处的浮点值均介于 0 到 1 之间,表示该像素中存在人物的概率。我们需设定一个名为“分割阈值”的值,其表示像素分值必须达到此最小值后,方可视作人物的一部分。通过使用分割阈值,这些介于 0 到 1 之间的浮点值会成为二进制数值 0 或 1(即表示,若阈值为 0.5 ,则任何高于 0.5 的值均会变为 1,而低于 0.5 的值则变为 0)。
我们调用 API 方法estimatePersonSegmentation对图像或视频执行人物分割操作;下方简短的代码块展示了如何使用此方法:
const imageElement = document.getElementById('image');// load the BodyPix model from a checkpointconst net = await bodyPix.load();// arguments for estimating person segmentation.const outputStride = 16;const segmentationThreshold = 0.5;const personSegmentation = await net.estimatePersonSegmentation(imageElement, outputStride, segmentationThreshold);
人物分割输出示例如下所示:
{ width: 640, height: 480, data: Uint8Array(307200) [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, …]}// the data array contains 307200 values, one for each pixel of the 640x480 image that was passed to the function.
如需了解此方法及其参数的完整说明,请参阅GitHub readme。
注:GitHub readme 链接
https://github.com/tensorflow/tfjs-models/tree/master/body-pix#person-segmentation
绘制人物分割输出结果
BodyPix 在浏览器中的另一优势是,其允许我们访问Canvas 合成等网络 API。通过这些 API,我们可以使用 BodyPix 的输出结果遮盖或替换部分图像内容。为帮助您入门,我们提供了包含此功能的实用函数,具体如下:
toMaskImageData会提取经估测的人物分割的输出结果,并生成透明图像,该图像会在人物或背景所处位置显示模糊图像,具体视 maskBackground 而定。然后,可使用drawMask方法在原始图像上将其绘制为掩膜:
const imageElement = document.getElementById('image');const net = await bodyPix.load();const segmentation = await net.estimatePersonSegmentation(imageElement);const maskBackground = true;// Convert the personSegmentation into a mask to darken the background.const backgroundDarkeningMask = bodyPix.toMaskImageData(personSegmentation, maskBackground);const opacity = 0.7;const canvas = document.getElementById('canvas');// draw the mask onto the image on a canvas. With opacity set to 0.7 this will darken the background.bodyPix.drawMask( canvas, imageElement, backgroundDarkeningMask, opacity);
drawMask会在画布上绘制图像,同时会绘制包含掩膜的 ImageData,使其带有特定的模糊度。
借助对上方第一张图像执行estimatePersonSegmentation后的输出结果,toMaskImageData将生成ImageData。若将 maskBackground 设为 true(默认设置),则 ImageData 便会如上方第二张图像所示;若将 maskBackground 设为 false,则其会与第三张图像类似
然后,可使用drawMask在图像上绘制此掩膜
第 2b 部分:身体部位分割
应用于图像的身体部位分割算法示例。图像来源:“Microsoft Coco:Common Objects in Context Dataset”,https://cocodataset.org.hb
除了简单的人物/非人物分类,BodyPix 还能将图像分割为表示24 个身体部位中任一个部位的像素。图像在输入模型后会转化为二维图像,其中每个像素处的整数值均介于 0 到 23 之间,表示该像素在 24 个身体部位中的所属部位。对于非身体部位的像素,此值为 -1。
我们调用 API 方法estimatePartSegmentation对图像或视频执行身体部位分割操作;下方简短的代码块展示了如何使用此方法:
const imageElement = document.getElementById('image');// load the BodyPix model from a checkpointconst net = await bodyPix.load();// arguments for estimating body part segmentation.const outputStride = 16;const segmentationThreshold = 0.5;// load the person segmentation model from a checkpointconst net = await bodyPix.load();const partSegmentation = await net.estimatePartSegmentation(imageElement, outputStride, segmentationThreshold);
身体部位分割输出示例如下所示:
{ width: 680, height: 480, data: Int32Array(307200) [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 3, 3, 3, 3, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 0, 0, 0, 0, 1, 1, 2, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 15, 15, 15, 15, 16, 16, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 23, 23, 23, 22, 22, -1, -1, -1, -1, …]}// the ‘data’ array contains 307200 values, one for each pixel of the 640x480 image that was passed to the function.
如需了解此方法及其参数的完整说明,请参阅GitHub readme。
注:GitHub readme 链接
https://github.com/tensorflow/tfjs-models/tree/master/body-pix#person-segmentation
绘制身体部位分割输出结果
借助 estimatePartSegmentation 的输出结果,以及按部位 id 索引的颜色数组,toColoredPartImageData可在每个像素处为每个部位生成带有相应颜色的图像。然后,可在画布上使用drawMask方法将其绘制为原始图像的掩膜:
const imageElement = document.getElementById('person');const net = await bodyPix.load();const partSegmentation = await net.estimatePartSegmentation(imageElement);const rainbow = [ [110, 64, 170], [106, 72, 183], [100, 81, 196], [92, 91, 206], [84, 101, 214], [75, 113, 221], [66, 125, 224], [56, 138, 226], [48, 150, 224], [40, 163, 220], [33, 176, 214], [29, 188, 205], [26, 199, 194], [26, 210, 182], [28, 219, 169], [33, 227, 155], [41, 234, 141], [51, 240, 128], [64, 243, 116], [79, 246, 105], [96, 247, 97], [115, 246, 91], [134, 245, 88], [155, 243, 88]];// the colored part image is an rgb image with a corresponding color from the rainbow colors for each part at each pixel.const coloredPartImage = bodyPix.toColoredPartImageData(partSegmentation, rainbow);const opacity = 0.7;const canvas = document.getElementById('canvas');// draw the colored part image on top of the original image onto a canvas. The colored part image will be drawn semi-transparent, with an opacity of 0.7, allowing for the original image to be visible under.bodyPix.drawMask( canvas, imageElement, coloredPartImageData, opacity);
借助对上方第一张图像执行estimatePartSegmentation后的输出结果,以及提供的色度,toColoredPartImageData将生成类似于第二张图像的 ImageData。之后,可在画布上使用drawMask以将彩色部位图像绘制在原始图像上,并将模糊度设为 0.7;所得结果如上方第三张图所示
如需了解有关这些方法及其具体用法的详细说明,请参阅 GitHubreadme。
注:GitHubreadme 链接
https://github.com/tensorflow/tfjs-models/tree/master/body-pix#output-utility-functions
如何让 BodyPix 运行得更快或更精确
模型大小和输出步长最能影响性能和精确度,您可以设置二者的值,让 BodyPix 以低精确度高速运行,或以高精确度低速运行。
加载模型时,我们会设置模型大小和mobileNetMultiplier参数,参数值可能为 0.25、0.50、0.75 或 1.00。该值与 MobileNet 架构和检查点相对应。值越大,层的规模就越大,模型也会越精确,但其运行速度会相应降低。将其设为较小值有助于提升模型速度,但精确度也会相应降低。
运行分割时,我们会设置输出步长,此参数值可能为 8、16 或 32。总体来看,步长值还会影响姿势估测的精确度和速度。输出步长的值越低,精确度就越高,但速度也会越慢;而此值越高,预测时间则会越短,但精确度也会越低。
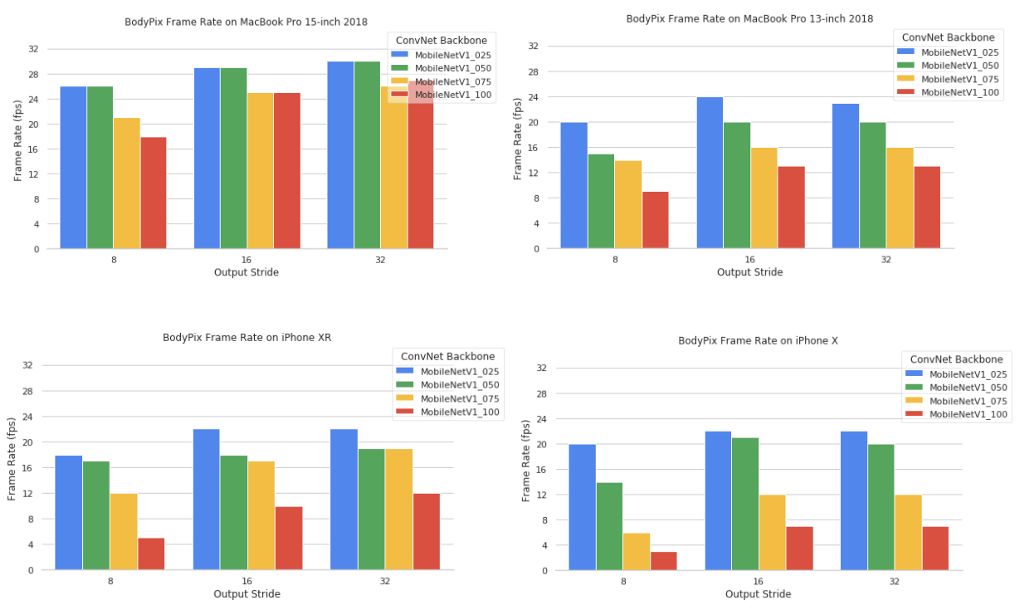
此外,原始图像的大小也会影响性能。由于分割的估测结果之后会放大为原始图像大小,因此原始图像越大,放大及绘制结果所需执行的计算就会越多。如要提高速度,您可以尝试缩小图像,然后再将其输入 API。
如果您想上手尝试 BodyPix,不妨在此处暂停片刻。若您有兴趣了解此模型的创建方法,可前往下一节阅读更多技术细节。
BodyPix 的创建过程
BodyPix 使用卷积神经网络算法。我们训练了 ResNet 和 MobileNet 这两个模型。尽管基于 ResNet 的模型更为精确,但本篇博文关注的是 MobileNet 已经过开源,能够在移动设备和标准消费类计算机上高效运行。MobileNet 模型用 1x1 卷积层代替传统分类模型最后的全连接池化层,以便预测密集的 2D 分割图。下图展示了使用 MobileNet 处理输入图像时所发生的情况:

本示例展示了 MobileNet 从输入图像到输出层的逐层激活过程(为便于演示,我们省略了特征图下采样操作)
人物分割
BodyPix 的核心是执行人物分割操作的算法,换言之,该算法会为输入图像的每个像素执行二进制决策,从而估测该像素是否属于人物的一部分。让我们通览一下此算法的运作过程:
上图说明人物区域分割任务可表示为对每个像素的二进制决策任务。1 表示像素属于人物区域,0 表示像素不属于人物区域(为便于演示,我们已降低分割分辨率)
将图像输入 MobileNet 网络,并使用 sigmoid 激活函数将输出结果转换为 0 到 1 之间的值,该值可表示像素是否属于人物区域。分割阈值(如 0.5)能够确定像素分值必须达到哪一最小值后,方可视作人物的一部分,进而能将此过程转化为二进制分割。
应用于图像的人物分割算法的数据表示示例。从左到右依次为:输入图像、网络在使用 sigmoid 函数后作出的分割预测,以及使用阈值后的二进制分割。插图作者:Ashley Jane Lewis。图像来源:“Microsoft Coco:Common Objects in Context Dataset”,https://cocodataset.org
身体部位分割
为对身体部位分割作出估测,我们使用相同的 MobileNet 模型作为演示,但这次会通过预测一个附加的 24通道输出张量P来重复上述过程,其中24表示身体部位的数量。每个通道会将身体部位存在与否的概率编成代码。
示例表明,分割人体部位区域的任务可表示为对每像素的多通道二进制决策任务。对于每个身体部位通道,1 表示像素属于身体部位区域,0 表示像素不属于身体部位区域(从左到右依次为:输入图像、右脸通道和左脸通道)

本示例展示了 MobileNet 从输入图像到附加的 24 通道身体部位分割输出层的逐层激活过程(为便于演示,我们省略了特征图下采样操作)
由于图像各位置的输出张量P中均有 24 个通道,因此我们需要在这些通道中找到最佳部位。推理期间,对于身体部位输出张量 P 的各像素位置 (u,v),我们使用以下公式来选择概率最高的最佳body_part_id:
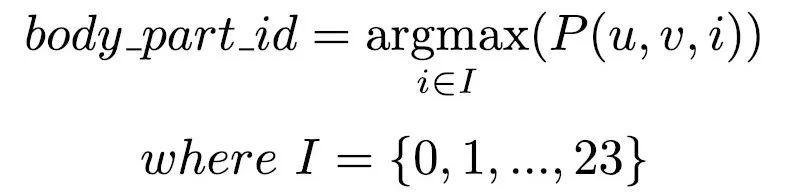
如此便会生成一张二维图像(大小与原始图像相同),且图像中的每个像素都包含一个整数,用以表示该像素所属的身体部位。人物分割输出结果用于裁剪完整图像中的人物,方法是将对应的人物分割输出值小于分割阈值的像素值设为 -1。
本示例展示了如何将 24 通道身体部位分割与人物分割合并为单通道部位 id 输出。插图作者:Ashley Jane Lewis。图像来源:“Microsoft Coco:Common Objects in Context Dataset”,https://cocodataset.org
本示例展示了在使用上述 argmax 公式合并 24 通道身体部位掩膜,并使用人物分割裁剪出人物区域后,最终形成的单通道身体部位 id 输出(每个body_part_id 均由唯一的颜色表示,且为便于演示,我们已降低输出分辨率)
使用真实数据与模拟数据进行训练
在将图像中的像素分割成 24 个身体部位区域的任务中,手动标注大量训练数据的方法相当耗时。于是,我们在内部使用计算机图形技术,以生成具有真实身体部位分割标注数据的图像。为训练模型,我们将生成的图像与真实的 COCO 图像(带有 2D 关键点和实例分割标注)混在一起使用。通过利用混合训练策略和多任务损失函数,我们的 ResNet 模型能够完全从模拟的标注数据中学习掌握对 24 个身体部位的预测功能。最后,我们将 ResNet “老师” 模型对 COCO 图像的预测功能提取至 BodyPix 所采用的 MobileNet “学生” 模型。
本示例展示了 ResNet “老师” 模型在真实图像与计算机图形技术所生成图像上的训练过程。身体部位的真实标注只出现在由计算机图形技术生成的图像上
本示例展示了如何将 ResNet“老师”模型的预测功能提取至 BodyPix 所采用的 MobileNet“学生”模型
我们相信 BodyPix 将成为除 PoseNet 之外,助我们迈向如下目标的又一小步,即帮助用户利用消费类设备在本地完成野外动作捕捉。目前,我们仍有不少研究问题尚未完全解决,如捕捉 3D 身型、高频软组织肌肉运动,以及详细展示服饰外观及其变形等。尽管前路漫漫,但我们仍乐观期待动作捕捉技术能够更方便地应用于各个领域和行业,同时带来更大用处。
我们已提供一些示例和实用方法,旨在帮助您启用 BodyPix 模型,并希望以此启发您对模型作出进一步修改。
-
浏览器
+关注
关注
1文章
1022浏览量
35322 -
tensorflow
+关注
关注
13文章
329浏览量
60527 -
机器学习模型
+关注
关注
0文章
9浏览量
2567
原文标题:BodyPix 发布:在浏览器中使用 TensorFlow.js 进行实时人物分割
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

一种WAP嵌入式浏览器的设计
一种新型分割图像中人物的方法,基于人物动作辨认

TensorFlow发表推文正式发布TensorFlow v1.9
利用TensorFlow.js,D3.js 和 Web 的力量使训练模型的过程可视化
基于tensorflow.js设计、训练面向web的神经网络模型的经验
用TensorFlow.js在浏览器中构建了一个使用任意图像进行风格化的demo
基于TensorFlow的开源JS库的网页前端人物动作捕捉的实现







 工商网监
工商网监
评论