 一款基于GAN的AI修图大师可以将你从这类工作中解放出来
一款基于GAN的AI修图大师可以将你从这类工作中解放出来

作为一个设计师,是否整天因为繁琐枯燥的修图工作不胜其烦?现在,一款基于GAN的AI修图大师可以将你从这类工作中解放出来。修轮廓、改表情、生发、加耳环、去眼镜、补残图,你能想到的它都能一键搞定。
这可能是史上最牛的AI修图大师。
在一张人脸图片上画上几笔,比如说勾出一个眉毛的轮廓,它就能自动把草图修正成真实的图片,即使你毫无艺术细胞,也没关系,只要能够大致表明想修哪里,剩下的活儿就都交给它好了。
这款工具由韩国电子与电信通讯研究所的Youngjoo Jo和Jongyoul Park开发,它比一般的脸部图片编辑工具或应用程序更高级,可以改变发型、把严肃脸改成笑脸,甚至可以加入原本没有的配饰,比如耳环、耳钉等。还可以在一张被部分遮挡的面部图像上生成完整的脸部图像,还能把图中的人戴的太阳镜去掉等等。
来看看这款“AI修图大师”的神奇效果:
改变脸部轮廓特征和瞳孔颜色
生发(划重点)、变笑脸、加头饰,都不在话下
加个耳环、耳坠什么的,只要划出大致位置就行了
强大的自动补全功能
草绘秒变真人,画风夸张也没问题
这款“神器”的开发者之一Youngjoo Jo表示:我们认为这个程序可以让设计师不用做那么多枯燥的劳动,让他们把更多的精力集中在创造性的工作上,不过这并不是说只有设计师才能使用这款工具,用户不需要具备设计上的专业知识。
机器学习研究人员Alex Champandard表示,这款工具与过去基于GAN的面部图片编辑程序相比实现了一次重大进步。
“当你面对这样的技术创新时,不免会在激动之余感到一丝害怕。”这种工具将不可避免地改变设计师的日常工作节奏和内容,但他并不认为这类工具会让设计师面临失业。
“现在的一个重要问题是,我们接下来要怎样做,才能让这一工具更好地服务于那些工作内容可能出现重大改变的人们?如何让这款工具成为这些人的好帮手,而不是威胁?”
SC-FEGAN:基于神经网络的人脸图像编辑系统
要达到这个神奇的效果,离不开SC-FEGAN。
SC-FEGAN是一种基于神经网络的人脸图像编辑系统,并提供了实现批量输入数据的方法。该网络可以端到端地进行训练,并生成具有逼真纹理细节的高质量合成图像。
该研究成果由韩国团队发表于arXiv:

论文地址:
https://arxiv.org/pdf/1902.06838.pdf
训练数据
恰当的训练数据有助于提高网络训练性能。
在训练本模型时,作者在几个预处理步骤之后使用CelebA-HQ数据集:
随机选择2组29000张图像用于训练,1000张图像用于测试;
在获得草图和颜色数据集之前,将图像调整为512×512像素。
为了更好的表达人脸图像中眼睛的复杂性,作者采用基于眼睛位置的free-from mask来训练网络。
此外,还使用了free from mask和人脸分割GFC创建了适当的草图域和颜色域。
这是非常关键的一步。因为它使得系统能够为手绘用户输入案例产生有说服力的结果。
网络结构
该网络同样也可以同时训练生成器和鉴别器。
生成器接收带有用户输入的不完整图像,在RGB通道中创建输出图像,并将输出图像的掩码区域插入到不完整输入图像中,以创建完整图像。
鉴别器接收完成的图像或原始图像(没有掩蔽)以确定给定输入是真实的还是假的。
在对抗训练中,识别器的额外用户输入也有助于提高性能。 此外,团队还发现与一般GAN损失不同的额外损失对于恢复大的擦除部分是有效的。
该网络架构如下图所示:
图注:SC-FEGAN的网络架构。除了输入和输出,LRN应用于所有卷积层之后。使用tanh作为发生器输出的激活函数。采用SN卷积层作为鉴别器。
生成器
生成器是基于U-net,所有卷积层使用3x3大小核的门控卷积。在除了其他soft gate之外的特征映射卷积层之后应用局部信号归一化(LRN)。LRN适用于除输入层和输出层之外的所有卷积层。
生成器的编码器接收尺寸为512×512×9的输入张量:具有在编辑时要被去除区域的不完整RGB通道图像,描述被去除部分结构的二进制草图、RGB颜色笔划图、二元掩模和噪音(如下图所示)。
草图和颜色域数据集以及批处理的输入。我们使用HED边缘检测器提取草图。使用GFC ,通过分割区域的中间颜色生成颜色图。 网络的输入包括不完整的图像、掩模、草图、颜色和噪声。
编码器使用2个步幅内核卷积对输入进行7次下采样,然后在上采样之前进行扩张卷积。
解码器使用转置的卷积进行上采样。然后,添加跳跃连接(skip connection)以允许与具有相同空间分辨率的先前层连接。
除了使用tanh函数的输出层之外,我们在每一层之后都使用了leaky ReLU激活函数。
总的来说,我们的发生器由16个卷积层组成,网络的输出是相同大小的输入(512×512)的RGB图像。
在将损失函数应用于输入图像之前,用输入图像替换了掩模外部的图像的剩余部分。这种替换允许发电机专门在编辑区域上进行训练。发生器受到了PartialConv中引入的损失的训练:每像素损失、感知损失、风格损失和总方差损失。还使用通用GAN损失函数。
鉴别器
该鉴别器有SNPatchGAN结构。同时,也使用3×3大小卷积内核,并应用了gradient penalty损失。还增加了额外的一项,避免了鉴别器输出patch的值接近于零。
总体损失函数如下:
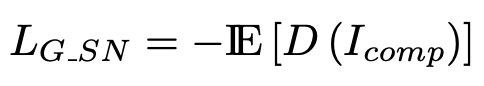
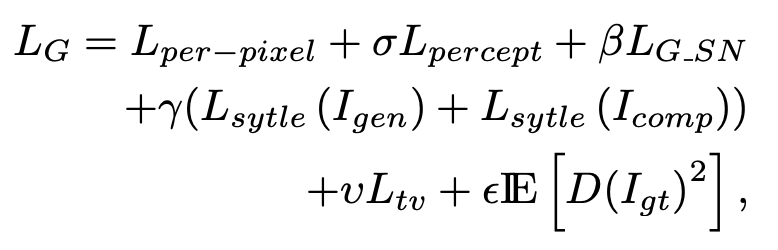
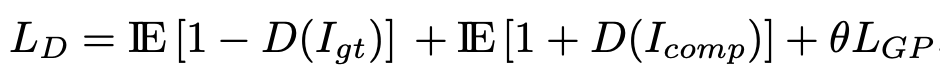
其中,发生器用LG进行训练,鉴别器用LD进行训练。D(I)是鉴别器给定输入I的输出。
而当编辑大面积区域时,额外损失(如Lstyle和Lpercept)是非常关键的。
多种场景修图俱佳,AI修图大师大显身手
那么,这款AI修图大师的修图结果如何呢?
首先将结果与Coarse-Refined net结构和U-net结构网络进行了比较。在测试Coarse-Refined net结构时,注意到细化阶段模糊了输出。而下图便展示了在Coarse-Refined net上使用本文方法后的结果。
在U-net和Coarse-Refined net上使用本文方法后的结果
本文的系统不仅在上述细节方面,在大面积区域修改方面也是具有优势的。
有/没有VGG损失的训练结果
在处理自由形状遮掩情况时,本文系统所产生的结果也较好。
与Celebf-HQ验证集上的Deepfillv1进行定性比较
下图显示了使用草图和颜色输入的各种结果。实验结果表明,该系统能够使用户很直接地编辑人脸图像的发型、脸型、眼睛、嘴巴等特征。
系统的面部图像编辑结果。 它表明系统可以正确地改变面部的形状和颜色。 还表明可以用于改变眼睛的颜色或擦除不必要的部分。 特别是右下角的两个结果表明系统也可以用于新的发型修饰。
GAN生成的图像结果通常显示出对训练数据集的高度依赖性。在本研究中,研究人员将HED应用于所有的区域,通过调度它来扩展掩蔽区域,能够获得特殊的结果,产生面部图像和耳环。
下图显示了这些有趣结果的选择。这些例子表明,该网络能够学习小细节,即使是很小的输入也能产生合理的结果。
特别的结果
总结
本文提出了一种基于端到端可训练生成网络的自由形状掩模、草图、颜色输入的图像编辑系统。
实验结果表明,与其他研究相比,该网络架构和损失功能显着改善了修复效果。并在许多情况下显示了各种成功和逼真的编辑结果。
该系统在一次性修复大面积区域方面表现极佳,使用者不需要费力就可以产生高质量和逼真的效果。
堪称AI修图大师!
-
神经网络
+关注
关注
42文章
4840浏览量
108142 -
图像
+关注
关注
2文章
1096浏览量
42435 -
GaN
+关注
关注
21文章
2382浏览量
84330
原文标题:最强GAN修图魔术师:美颜生发摘眼镜、草绘秒变真人脸
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
东软载波微电子ES-CodeMaker图形化代码自动生成工具发布

AI硬件五个模块的生死平衡

还在手动拼接 AI 代码?你的 IDE 早就该升级了
MCU工程初始化,到底该不该交给工具?
软件测试工具深度解析
AI+EDA如何重塑验证效率

小马智行亮相第二十届中国经济论坛
陶氏化学借助AI技术重塑网络安全
凌晨两点的急诊室:被校准卡壳的抢救设备

AI 芯片浪潮下,职场晋升新契机?
Analog Devices Inc. ADAQ8092 14位105MSPS μModule®数据手册




评论