 语音控制视为人机接口进步项 语音激活可嵌入到任何地方
语音控制视为人机接口进步项 语音激活可嵌入到任何地方
历史书可能会将语音控制视为人机接口中最重要的进步。我们不再打字,不再指点,只需说出想要什么就可以了。这个领域的初期进展十分缓慢,直到智能扬声器的出现,让我们开始意识到了解决方案。现在,随着在手机、耳机、可穿戴设备和智能家居中识别功能和应用的改进,这场竞争已然开始。如今,最广为人知的解决方案依赖于少数提供商控制的平台和服务,但这种情况正在发生改变。语音激活可嵌入到任何地方,不仅可以定制,还可提高抗噪性,降低功率,扩大范围,而且在语音识别方面与大型平台一样有效。
消费类语音产品市场的历史饶有趣味,而语音识别功能在其中起着重要作用。FutureSource 显示,从 2008 年到 2012 年,语音体验主要集中在智能手机上,整体市场价值下降。从 2012 年到 2014 年,市场基本持平。然后,从 2015 年到 2018 年,主要受语音激活驱动,它再次以 15% 的复合年增长率增长。展望未来,Yole Développement 预计到 2023 年,复合年增长率至少为 30%,这主要得益于语音识别。这一增长将主要集中在智能手机上,其次是耳机和可穿戴设备、个人助理和智能家居功能(电视、电器等)。同一份报告得出的结论是,我们现在正进入智能语音的第二阶段,随着消费者对这种控制方法越来越满意,语音控制将变得越来越普遍。
无论部署在哪里,他们的目标都是增强实别能力。在智能手机或任何其他电池供电的设备中,一个明显的优势是支持始终在线聆听;在发出命令之前无需按下按钮。这就需要超低功耗的触发命令词检测,众所周知,这意味着硬件与软件的契合,以尽量降低待机功耗。当然,用户都希望为自己的品牌定制个性化触发命令词或短语的功能,并且可以支持多种语言,以便在其所在地区甚至国际市场上获得强大的渗透力。您仍然将后续命令传递给某个主要的语音识别提供商来识别请求。或者,也许不必。如果您的设备只需要对有限的词汇表提供支持,并且您的语音识别引擎可以满足该目标,则可能无需第三方的帮助。
另一个关键需求是在嘈杂的环境中进行识别,也许还有身份验证。语音识别所面临的挑战与目标识别不同。例如,在起居室或汽车中,可能会有多个声源:人们说话、电视和独立的音乐/无线电、室内外的噪音、以及房间或汽车内部表面反射的回声。隔离命令源、消除回声和降低背景噪声需要一些复杂的技术,这取决于多麦克风、波束成形和回声消除,以及噪声抑制。
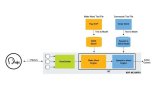
当然,鉴于这些需求,CEVA 等公司已备好满足这些需求的可用解决方案。最近推出的 CEVA Whispro™ 语音识别产品解决方案就采用了在 CEVA DSP 平台上运行的,基于神经网络的软件。Whispro 已经支持“Alexa”和“Ok Google”作为触发命令词,并且可以在培训中进行自定义,以支持任何客户要求的触发命令词。它支持多种语言,可以处理多种语音触发。该方案在多噪声背景下进行培训,因此,识别具有嵌入的抗扰性,识别率大于 95%,每小时错误接受率小于 1 次,且无需进行云识别。
通过添加专门的语音拾取解决方案 CEVA ClearVox™,开发人员可实现多麦克风支持和波束成形,以改进远场语音拾取、消除回声和进一步降低噪音。Whispro 与 ClearVox 的组合可以在更远的距离内(最远 7 米),尤其是在嘈杂的环境中,也能够提供具有竞争力的触发识别。
-
语音接口
+关注
关注
0文章
10浏览量
9918 -
语音控制
+关注
关注
5文章
484浏览量
28268
原文标题:语音接口的大众化【中文版】
文章出处:【微信号:CEVA-IP,微信公众号:CEVA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
空调语音控制方案NRK3501语音识别芯片-让智能生活触手可及!

语音识别与自然语言处理的关系

Transformer模型在语音识别和语音生成中的应用优势
卷积神经网络在语音识别中的应用
离线语音控制技术特点

语音控制模块_雷龙发展
智能语音交互技术如何助力设备实现人机自然对话
基于ASR-PRO离线语音芯片,DIY一个可转动的语音控制的月球音响灯
MCU配对简化了语音控制接口设计
澎湃微离线语音识别应用实例
语音合成技术在智能驾驶中的创新与应用
AI加速智能家居分布式语音技术发展
恩智浦发布新一代智能语音技术组合的语音识别引擎





 工商网监
工商网监
评论