 英伟达GPU Direct不可或缺的RMDA技术到底有多厉害?
英伟达GPU Direct不可或缺的RMDA技术到底有多厉害?
和娱乐圈的明星八卦一样,IT行业里面的各种并购也是非常有市场的。毕竟,像EMC,Cisco,Broadcom 这样的公司都是一路并购成长起来的。最近比较热门的应该是Mellanox说自己准备卖自己了。在25G/50G/100G市场上占据了69%的市场份额,2018年前三个季度,出货了2.1M的网络端口。[1] 这么好的标的,一时各种传闻都出来了。Xilinx[2],Microsoft[3],Intel[4],估计还有Broadcom[5]都在准备,以色列人的确有水平,已经从5.5B到了6B。陈福阳在华尔街筹钱的能力,估计还有大招。
Mellanox是个什么公司,一句话,就是目前RDMA技术的事实的技术定义者。虽然海有很多公司也有RDMA技术,但是在IB和Ethernet两个市场都能够呼风唤雨,只有它了。
Remote DMA技术在Ethernet上的应用不能不提微软,目前微软是目前在数据中心大规模部署RDMA的第一家HyperScale公司。微软在2015/6/7/8年的Sigcomm [6]有大量的论文来讲RDMA在数据中心的部署,很多人讲微软的风格是自己做了100分,但是对外只讲1分。因此可以想象Microsoft对于Mellanox准备卖身的关注,自己的技术投入不能打水漂,不仅自己下手,而且鼓励合作伙伴一起团购。
RDMA的技术是在一个有Mellanox主导的行业组织OFA[7]主导的。目前的成员如下图,可以看到还是集中在HPC的专业领域。

OFA是2004年成立的工业组织,在整个HPC行业从Myrinet[8]转换到IB的时候成立的。在2005年, Myrinet在TOP500的市场份额占到了28%,之后就一路下降,被IB替换掉了。对于诞生于HPC专业的领域,可用性一直是个大问题,HPC一切为了性能,不要虚拟化,不要通用操作系统和架构,每台超算恨不得自成一台体系。大家看看Mellanox的Linux 驱动的家族就知道这个有多复杂了。[7]
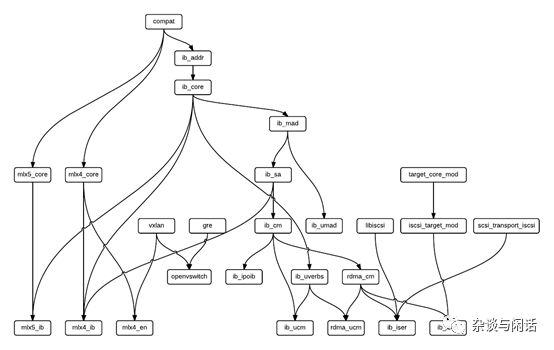
这路吐一个槽,作为Mellanox卡的资深用户,我很早就自己画了一份他们的OFED驱动的加载流程,作为Mellanox,这么基本的文档在2018年12月才发布,而且很多模块没有upstream,让人无奈的是,到现在为止我还没有找到卸载rdma_cm ( connection mangament ) 的有效方法。每次都需要重启。
因此看到AWS说要发布他们的EFA的时候,觉得他们还是真有勇气,但是仔细一看,原来和AWS的HPC业务紧密结合,而且利用了libfabric 的生态[8]
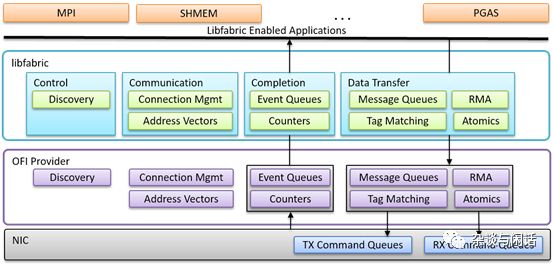
很明显,libfabric在网路传输层和流行的HPC编程框架之间做了一个统一。更重要的是,对于原来OFA的功能定义做了一个大大减法。俺曾经自己研究总结了Mellanox CX系列网卡的功能。大家可以自己看看这个复杂度。
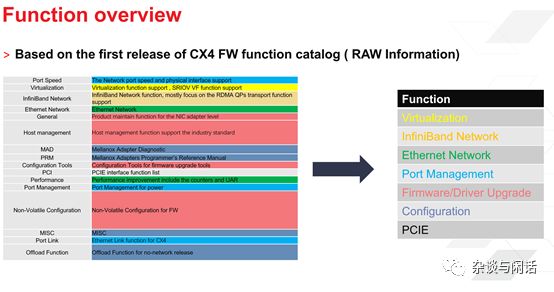
对于像AWS这样的Hyperscale公司也要部署RDMA,这个做法和之前的微软有很大的不同。对于微软,他们从40G开始规模部署RDMA,就是为了Azure的云环境的低延时网络,目前微软的网络还是天下第一。[9]当然微软为了大规模部署RoCEv2的所作的各种流控算法以及应用的优化对于整个业界都是非常有用的,但是他们主要停留在传统的网络上面。
AWS则不同,对于低延时网络来讲,在2014年之前,大部分的场景就是SDS,太多的存储startup公司,使用PCIE Flash和RDMA 网卡来构建自己的分布式存储系统,比较典型就是EMC收购的ScaleI/O了。[10]
2014年之后,由于ALexnet的出色表现,RMDA和Nvidia有了深度合作,利用GPU Direct,在GPU集群中快速传递数据成了RDMA的另一个
大众应用。[11]
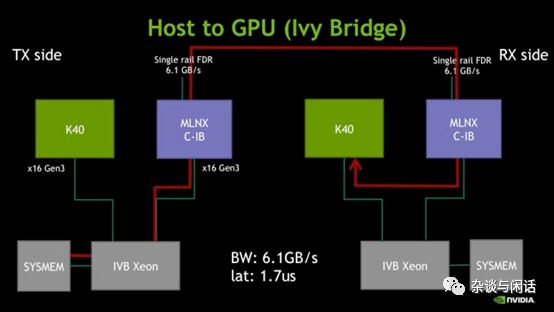
GPU+RDMA也是目前在TOP500部署量最大的应用,因此可以很明确地看出AWS使用Nitro做EFA的目的了。
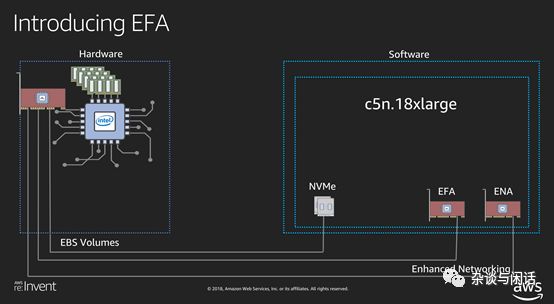
貌似只有一款机型部署了EFA。[12] 对于这个机型,定位很清楚,HPC和分布式机器学习的训练,因此功能实现也非常有目的,不要指望EFA会和Mellanox一样功能强大。
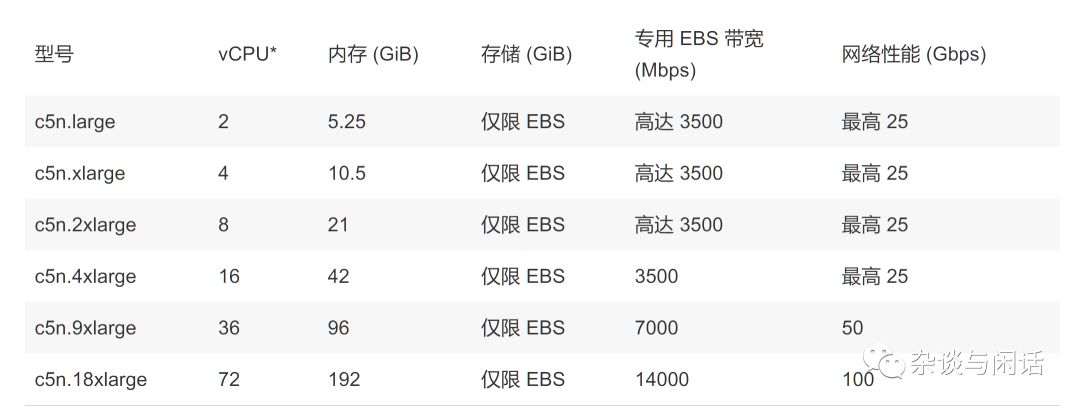
因此,可以看出,传统的Nitro芯片在升级了25G的Serdes之后,利用libfabric的生态实现了部分的RDMA的功能,可以满足AWS上的HPC和ML的业务需求。这个和国内的大厂的想法类似。
因此,对于未来RDMA在数据中心的使用场景,存储和HPC是两个比较明确的方向。对于存储,如何和NVMe这样的存储介质,以及NVMeoF和Cephover RDMA这样的存储后端结合是一个方向,在这个方向上,是不是要支持IB的编程框架并不重要。对于HPC的方向,则是如何和GPU这样的计算引擎结合,简单数据传输的延时,和上层的ML的框架紧密结合。
广告时间: Xilinx在2018.1 中就推出了自己的RDMA的实现,目前主要关注在存储应用这个方向。[13]实现了对10G/25G/40G/100G的网络速率的支持,在Vivado 2019.1中会在延时上有进一步的提升,在512Byte上和标准的Mellanox类似,当然我们也是兼容Mellanox。欢迎大家垂询。
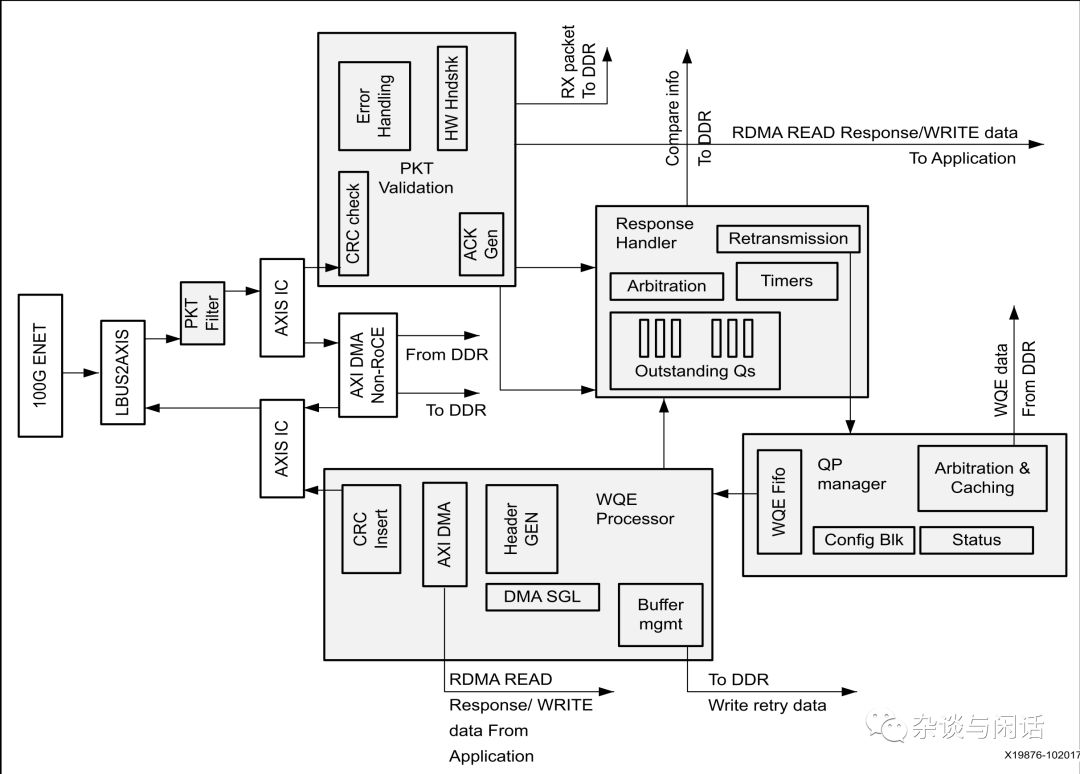
[1]https://www.businesswire.com/news/home/20181025005197/en/Mellanox-Ships-2.1-Million-Ethernet-Adapters-Quarters
[2]https://www.cnbc.com/2018/11/07/xilinx-working-with-barclays-to-buy-mellanox-possible-december-deal.html
[3]https://www.cbronline.com/news/microsoft-mellanox
[4]https://www.hpcwire.com/2019/01/30/intel-reportedly-in-6b-bid-for-mellanox/
[5]https://en.globes.co.il/en/article-mellanox-acquisition-fits-broadcom-like-a-glove-1001258241
[6]http://www.sigcomm.org/
[7]https://community.mellanox.com/s/article/mellanox-linux-driver-modules-relationship--mlnx-ofed-x
[8]https://ofiwg.github.io/libfabric/
[9]https://mspoweruser.com/report-microsoft-azure-beats-google-cloud-and-amazon-aws-in-network-performance/
[10]https://en.wikipedia.org/wiki/Dell_EMC_ScaleIO
[11]https://devblogs.nvidia.com/benchmarking-gpudirect-rdma-on-modern-server-platforms/
[12]https://aws.amazon.com/cn/ec2/instance-types/
[13]https://www.xilinx.com/products/intellectual-property/etrnic.html
-
英伟达
+关注
关注
22文章
3749浏览量
90867
原文标题:深度好文:RDMA,到底有多厉害?
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
高铁站网约车数智出行到底有多智能
挑战英伟达:聚焦本土GPU领军企业崛起
英伟达将全面转向开源GPU内核模块
英伟达数据中心GPU出货量飙升,市场份额持续领跑
英伟达GPU新品规划与HBM市场展望
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
英伟达、AMD、英特尔GPU产品及优势汇总
国内GPU新势力:能否成为英伟达的“终结者”?

印度政府考虑购买英伟达GPU以发展人工智能生态系统
英伟达发布新一代AI芯片架构Blackwell GPU
英伟达在英受审,业绩创新高
机器视觉在电子半导体行业的应用 ——倒装焊技术不可或缺的“锐眼”






 工商网监
工商网监
评论