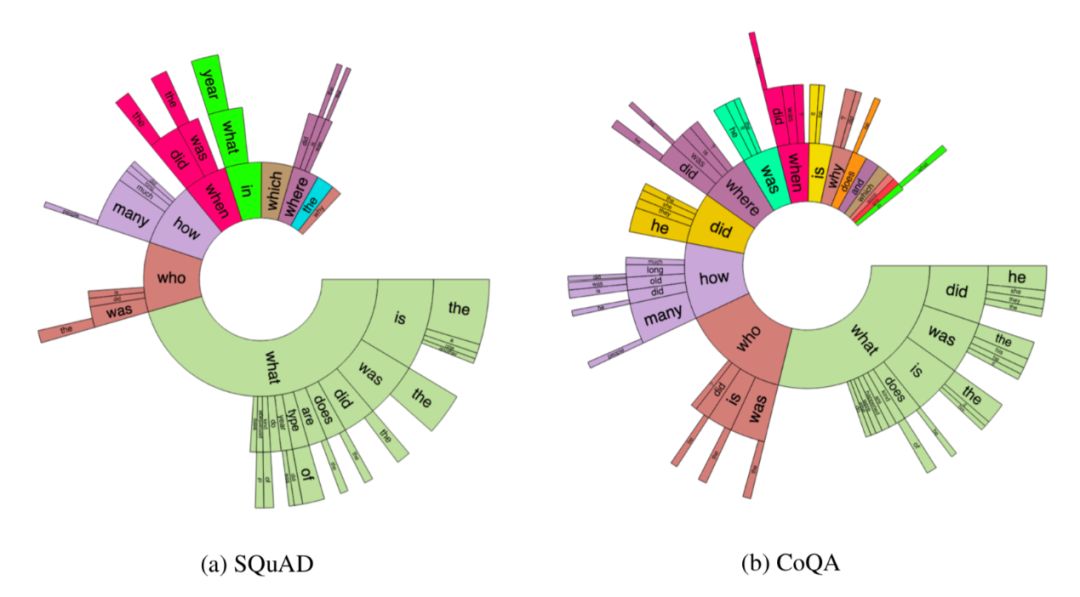
 斯坦福NLP的强大QA数据集
斯坦福NLP的强大QA数据集
很多朋友在互联网搜索问题的时候都会大赞引擎返回的结果,而不是丢给你一堆链接让你自己去查找。各类搜索引擎会对问题进行有效的匹配,总能准确的告诉你世界上有多少个国家、中国的面积有多大,以及今年清明放几天假。但是面对更为复杂的问题可能搜索引擎黔驴技穷了,比如你想要去把上周末贪心吃掉一大块巧克力芝士蛋糕运动燃烧掉,无论是谷歌百度还是必应搜狗都没办法告诉你需要骑多久的车、走多远的路才能燃烧你的卡路里。但是,任何一个人都可以从引擎返回的前面一两条链接内容里找到自己的答案。
在如今这个信息爆炸的时代,无数的信息和知识文本让我们目不暇接。让机器替代我们去阅读海量的文献并为我们提供相关问题的答案在当今社会有着十分巨大的现实需求和重要的现实意义,机器阅读理解和问答已经成为了自然语言处理领域的关键任务,这一能力将会实现像电影时光机器中那位知识渊博的图书管理员一样强大的智能AI知识系统。
近年来,类似SQuAD和TriviaQA等大规模的问答数据集促进了这一领域的快速发展,庞大的数据集是的研究人员可以训练更大更深更强的深度学习模型。通过这些庞大数据集驱动的算法已经可以通过在百科中搜寻合适的内容来回答很多随机的问题,而无需人类亲力亲为寻找答案。

SQuAD数据集从超过500篇百科文章中收集了超过10万个问题,文章的每一段都列出一系列独立的问题和与之相对应段落内一段连续内容作为答案。这种方式又称为“抽取式问答” 。
虽然这些数据集推动着这一领域飞速发展,但依然存在不可回避的问题。事实上研究人员发现模型并没有理解问题的内涵,而更多地倾向于去对问题的答案进行模式匹配。

From Jia and Liang. 研究显示模型只学会了匹配城市名字而不是理解问题和答案。
为了克服这些问题,斯坦福NLP组的研究人员们Peng Qi & Danqi Chen提出了两个新的数据集。在这篇文章中,研究人员探索了如何拓展现有机器阅读系统的能力,并基于这两个新的数据集探索了在问答任务中机器“阅读”与“推理”间的相关性,以突破机器以简单的模式匹配方式来回答问题。
其中CoQA数据集集中于对话的角度,通过自然对话的形式引入与文本段落相关丰富的上下文信息来为问答系统提供对话角度的探索方向。而HotpotQA数据集则超越了段落内容,主要集中于解决需要综合多个文本,并进行有效推理才能获得答案的复杂挑战。
CoQA数据集
绝大多数现存的问答系统局限于独立的回答问题(类似于SQuAD)。尽管这也是一种问答方式,但对人人类来说更常见的做法是听过一系列你问我答的具有相互关联的交流对话来获取有效信息。CoQA就是这样一个机遇对话问答的数据集,其中包含了自七个领域的8千个对话过程,共十二万七千个问答数据,可以有效解决现有AI问答系统中存在的上述问题。

CoQA主要包含了从各种来源收集的文章,以及关于文章内容的一系列相关对话。对话的每一轮包含一个问题及其答案,同时每一个问题都依赖于先前的问题。与SQuAD以及其他现存的数据集不同的是,这一数据集中对话历史对于回答很多问题的答案是不可或缺的。例如在上面例子中的第二个问题,在没有对先前回答历史理解的情况下是无法回答的。此外在对话中人们的注意力中心会随着对话的进行而转移,例如前述例子中的从问题四中的他们,到问题五中的他再到问题六中的他们,对于机器来说要回答这类对话中心迅速变化问题充满了调整,数据集中的问题需要机器能够更加理解对话的上下文内容才能有效回答。
CoQA还具有很多不同于先前数据集的新特征:
首先这一数据集并不会像SQuAD一样将答案限制在文章中一个连续地区域。研究人员认为一个问题的答案不仅仅局限于一个单一的部分,而是会分布在文章各处。此外研究人员希望这一数据集可以支持自动评价,问题的答案可以获得人类的认同。所以数据集的标注者不仅标注出了文章中对应的部分(作为给出答案的理由),同时将这些部分编辑为了自然语言形式的回答。这些给出答案的理由将提升问答系统模型的训练效果。
其次现存的QA数据集大都集中在单个领域,使得基于这些数据集训练的模型不具有通过的泛化能力。为了解决这一问题CoQA数据集收集了来自儿童故事、文学、中学英语测试、新闻、百科、Reddit和科学等七个领域的不同材料,使得数据集具有了更为丰富的特性。
通过对数据集进行深度的分析,研究人员发现了一系列丰富的语言学现象。首先27.2%的问题需要进行实际的推理,包括常识和预测的辅助,而不能简单的从文章内容中进行转述。比如需要通过对于主人公动作的描写来推测他的性格。只有29.8%的问题可以直接通过文本匹配来回答。此外研究人员发现有30.5%的问题并不依赖于讨论历史,49.7%的问题包含“它”、“他”、“她”等清晰的讨论语言标志,额外19.8%的问题需要参考整个段落或事件来进行回答。

与SQuAD2.0相比,CoQA数据集的问题要短很多(平均5.5词),这反映了数据集中对话的特点。此外数据集中的问题还包含了更多丰富的问题和更多类型的提问方式,而SQuAD中的问题则更多的集中于问题本身。同时CoQA数据集还加入了更多的前缀、时态的变化,丰富了问答系统的表达。
最新进展
去年八月公布数据集以来,CoQA引起了全球范围内研究者的关注,并成为了最有效的基准数据集。基于它产生了一系列优秀的研究工作,包括谷歌强大的BERT模型和微软亚洲研究院提出的“BERT+MMFT+ADA”方案实现87.5%的领域F1和85.3%域外F1精度。不仅达到了人类的水平并超过了不久之前基准模型将近20个点。我们相信在优秀数据集的基础上,好的模型还将不断涌现,未来可期!

HotpotQA:基于多文本的机器阅读
为了探索世界本来的面目,我们再阅读时不仅需要深入理解每篇文章上下文的内容和关系,更需要搜寻多篇相关的文献探求事物背后的内在联系。例如下面这些问题问题,我们基于从单篇材料进行回答:
- 雅虎是在哪个州建立的?
- 斯坦福还是CMU的计算机研究人员多?
- 刚刚吃的小蛋糕需要跑步多久才能消耗掉?
虽然网上有丰富的资料几乎可以帮助我们解答任何问题,但很多时候我们并不能直接搜索到需要的答案。如果我们想要知道雅虎在美国哪个州创立的,我们假设你就只在wiki上进行检索,发现我们没能找到这个问题的直接答案,而仅仅发现了Yahoo的主页和杨致远,David Filo的介绍。为了回答这个问题,你需要在wiki上浏览并总结如下的分析才能回答这一问题:

通常我们将经历以下步骤来回答这个问题:我们首先注意到,雅虎是在斯坦福创建的,那么随后我们就将问题中心转移到斯坦福在哪。随后在斯坦福的页面上发现它坐落于加州,最后我们就将这两个问题联系起来得到了雅虎于加州创立的答案。
显然在回答这类问题的时候我们需要具备两种能力:寻找相关信息的检索能力以及基于多个文档信息进行推理的能力。
这对于机器阅读系统来说是十分重要的能力,只有具备这样的检索推理能力才能帮助我们从海量的信息总寻求需要的答案。
然而目前的数据集大都集中于单个文档的理解问答,为了解决这一问题,斯坦福的研究人员们建立了另一个优秀的数据集HotPotQA。
HotpotQA数据集的内容
HotpotQA是一个包含十一万三千个问答对的庞大数据集, 这一数据集的特点在于问题的答案需要结合大量的文档进行分析综合,并最终基于多个事实的支撑来推理得出答案。

这一数据集中的问答来源于整个英文版的Wikipedia,覆盖了从科学、宇宙、地理到娱乐、运动、和法律等多样性的内容。其中的每一个问题都需要综合多个文档进行推理而得到。例如前文雅虎的例子中,斯坦福大学就是回答问题中确实的一环,我们通过寻找斯坦福的位置间接的回答了雅虎创立的地点。这一条推理的逻辑链条如下所示:

在这问答中,斯坦福大学成为了我们衔接不同知识间的桥梁和纽带。在很多类似的问题里都会存在这里衔接不同知识的桥梁,帮助我们最终通过整合推理得到答案。
也许你会想到,我们如果可以直接找到问题中的桥梁媒介那就太好了!虽然这一中介不能回答原始问题,但它可以指导我们进行推理和进一步的信息搜寻已解决问题。在Hotpot数据集中,研究人员总结出了一类新的问题类型:比较形问题,以增强问答系统的推理和语言理解能力。
例如,到底是斯坦福还是CMU的计算机研究人员多呢?为了回答这一问题,QA系统不仅需要检索出相应的材料,分别找出两个学校计算机研究人员的数量,同时还需要对结果进行比较以获取最终答案。而比较对于现有的问答系统十分困难,问题中引入的数值比较、时间比较、数量甚至是算数问题的比较提高问题的复杂度和难度。
但这并不意味着前一个寻找相关材料的问题简单。尽管在比较问题中搜索和定位支持材料较为容易,但对于需要桥梁媒介来进行回答的问题,这一任务很可能更具挑战。
基于传统信息检索方法将wiki的文章按照与问题的相关性进行排名,研究人员发现需要平均检索两个以上的段落(黄金段落)才能找到与问题相关的答案,而在排名最高的是个段落中只能找到1.1个黄金段落。在按照相关性排序画出的图中,无论排序较高或者是较低的段落都呈现出了明显的厚尾效应。

具体来讲,有超过80%的高排名段落可以再Top10的检索结果中找到,而只有30%的低排名结果可以在Top10中找到。假设我们仅仅依靠阅读相关性排名较高的文件来寻找可以回答问题的环境段落的话,我们需要阅读近600个文本,这还不包括机器有时候无法准确识别黄金段落带来的损耗。
所以我们需要新的方法来解决这种原始的机器阅读方法,引入推理和归纳来提升系统表现,这也将为我们带来对于海量信息更加便捷的和有效的接入。
创建更具解释性的问答系统
问答系统另一个重要的需求是产生结果的可解释性。一个只会简单给出答案的问答系统,而不能解释或者严重答案的问答系统,在某种程度上来说是无法使用的。即便是在绝大多是时候这一系统都给出了正确的答案,用户在无法再无法验证答案的情况下是不会充分信任它的。
所以HotpotQA数据集在收集过程中,标注人员将得到答案的支撑语句标记了出来,作为数据集的一部分为问答系统提供可解释性的支持。下图中绿色的句子作为得到答案的依据被标注了出来。
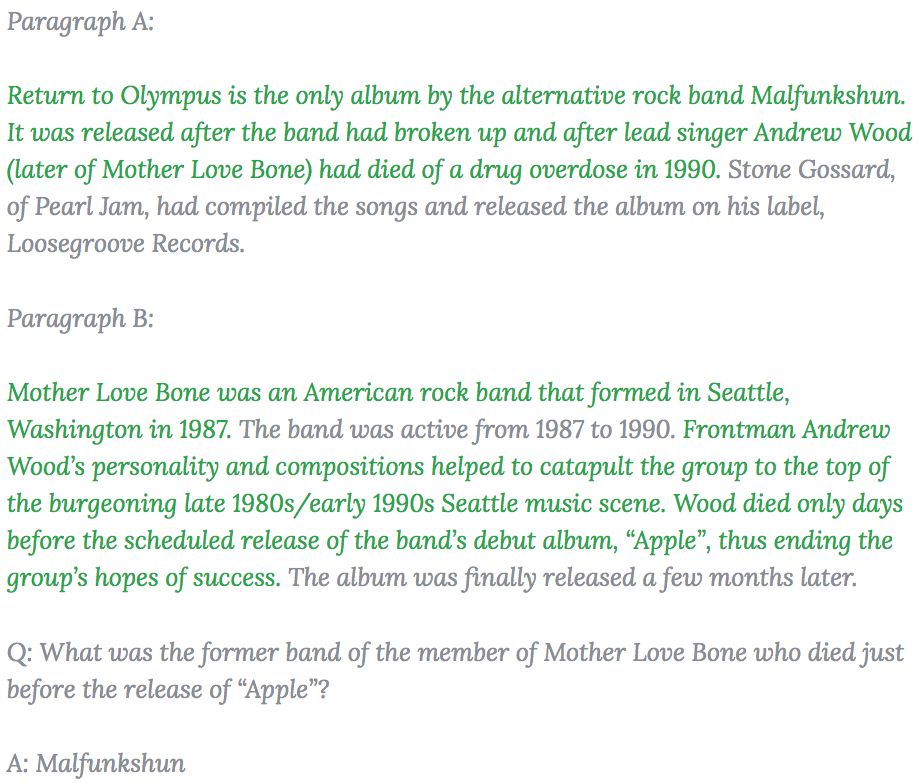
这些依据不仅能够帮助用户更有效地检查系统给出的答案,同时也能在很大程度上促进系统更精确地寻找所期望的答案,为模型提供比先前数据集更丰富的监督信号。
写在最后的思考
书写的文字中浓缩了人类最宝贵的智慧,越来越多的电子化文件将有效驱动智能问答系统的阅读、推理和理解能力,超越传统的模式匹配,单一文本的学习模式,并发展出具有多文件归纳、推理和理解能力的强大系统。
CoQA系统中一系列问题形式的数据集将有效共享多个对话之间的上下文内容,综合推理回答复杂的问题;HotpotQA数据集中的多文件推理和支撑依据将进一步促进智能问答系统对问题的综合理解及可解释性。这将促进学界在相关方向上更为深入的研究,更多的优秀研究和高性能模型将会不断涌现。
数据是深度学习系统,特别是问答系统最为重要的燃料,这两个数据集将为投入深度学习的熔炉,推动用问答系统的引擎推动深度学习这艘巨轮不断向前。
-
AI
+关注
关注
87文章
32332浏览量
271431 -
机器
+关注
关注
0文章
787浏览量
40897 -
数据集
+关注
关注
4文章
1212浏览量
24964
原文标题:机器阅读理解最新进展:超越模式匹配,斯坦福研究员探索机器“阅读”与“推理”的相关性
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
斯坦福开发过热自动断电电池
关于斯坦福的CNTFET的问题
斯坦福 CG635 供应 CG635 时钟发生器
供应 现货 CG635 斯坦福 时钟发生器
热卖现货 CG635 斯坦福 时钟发生器
回收新旧 斯坦福SRS DG645 延迟发生器
DG645 斯坦福 SRS DG645 延迟发生器 现金回收
"现代爱迪生"镍氢反应电池发明者斯坦福逝世
斯坦福开启以人为中心的AI计划
斯坦福SR560可编程滤波器开机显示overload维修案例

维修斯坦福SR560可编程滤波器烧了overload






 工商网监
工商网监
评论