 Git命令解析-patch、apply、diff
Git命令解析-patch、apply、diff

无论是merge还是rebase,都是在同一个工作目录中协调差异,处理变更历史。而git的另一些命令,允许开发者单独保存,或者通过文件或邮件的方式与别人分享这些差异。
这有助于更灵活的选择和使用某些较为独立的更改。这有点类似另一类版本控制系统的工作方式:存储差异而不是快照。
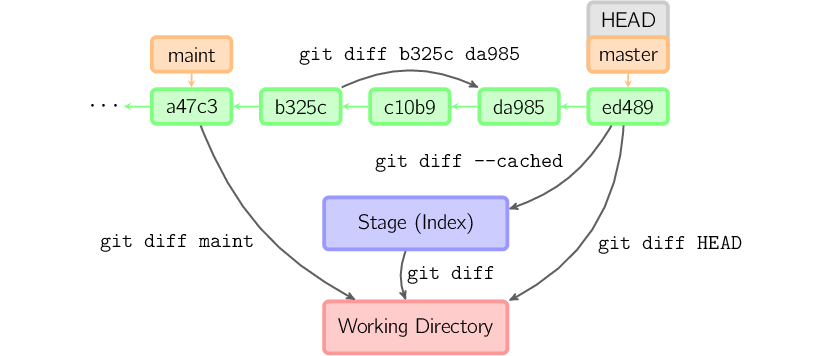
可以使用 git diff > patchfile 将差异输出到patch文件,保存或者分享给他人。使用 git diff 命令可以查看工作区修改的内容,git diff —cached 命令查看添加到暂存区但还未提交的内容。这两种命令会生成兼容unix系统的标准格式patch。类似这样:
git apply --stat patchfile
git apply --check patchfile
git apply patchfile
这三条命令分别是,检查patch文件格式,测试patch是否能应用到当前分支,应用此patch。
这种方式传递的修改将会丢失提交信息和作者信息,但可以兼容非git管理的代码。除此之外,git还提供另一个命令更便于git库之间的patch传递。
git format-patch commit-id
git format-patch -s commit-id
生成指定提交之后的所有提交的patch。把 -s 改为 -n,n为任意数字,则会生成每个提交之前的n个patch。每个patch是单独的文件,命名类似于:
0001-commit message.patch
format-patch生成的patch保存了更多提交信息。因此除了git apply之外,还可以用更智能的git am命令使用此patch。git am 命令会在应用patch失败时给出详细的错误信息,并允许手动解决冲突,是官方较为推荐的补丁应用方式。
我们在使用版本控制工具时,总会花费很多时间来处理diff,比如检查正在进行的未提交的工作,查看单个提交中发生了什么变更,在执行合并之前比较两个分支,等等。
diff是版本控制的核心概念,但可能大多数使用者没有考虑过它是如何生成的。请思考一下如何编写一个函数来计算diff。很容易发现,更准确的需求是只显示发生了什么变化,忽略其他保持不变的部分。那么,如何确定文件的哪些部分没有更改?如果从某行开始发现了差异,如何在每个版本中找到再次匹配的部分?
对修改者来说,哪些东西应该标记为更改似乎是显而易见的。比如向文件中插入新代码、删除冗余语句或重写部分函数,作为代码的贡献者,我们总会有一个直观的心理模型。然而,如同大多数程序员所知,只会执行指令的机器要得到一个符合人类直觉的结果,通常比看上去要困难的多。而且总会存在很多可供选择的实现方法,会产生完全不同的结果。
例如:有原序列ABCABBA,记做a,长度记为N,修改后的序列CBABAC,记做b,长度记为M。以单个字符为最小单位,把删除和添加两个步骤作为变更的基本操作。从a到b显然有很多种方法,比如可以直接简单粗暴的删除a,再添加b,那么编辑脚本看起来会是这样:
一共需要 N+M 步,这显然不是我们想要的最简操作。再继续观察,发现操作中出现了对同一个字符的删除和新增操作,这些字符可以看做不变的部分,省略编辑步骤。
但是又出现了新的问题,比如仅看新串的前三个字符CBA,它可以看做原串第3-7字符删掉中间AB,也可以看做2-4字符的前面加C同时删除中间的C。这两者虽然步数相同,但不同的看待方式会影响其他字符的变更步数。另外,就算全部步数相同,也可能存在一些方式比另一些方式更直观更容易理解。
形式上,问题的关键是找到一个最长公共子序列,或者等价地,找到将一个序列转换成另一个序列的符号的最少步骤。这是一个已有广泛研究基础的问题,git使用的默认算法由Eugene W. Myers 在1986年的论文(http://www.xmailserver.org/diff2.pdf)中提出。
Myers的算法就是这样一种策略,它的速度很快,而且它产生的变更大部分情况下都是最直观的。它通过贪心的方式来实现这一点,即优先尝试使用相同的行数,并且在处理等价步骤时优先选择删除而不是插入。
下面尝试较为直观的展示该算法的基本步骤,并通过一个示例表现它如何计算从一个版本到另一个版本的最简变更。
令x轴为原序列a,y轴为新序列b,两个序列之间的转换就可以表示为下图。向右表示删除一个字符,而向下则表示新增,对角边对应那些允许不变的部分。
原问题就转化为找从点(0,0)到点(N,M)的最多对角边,同时也等于找从点(0,0)到点(N,M)的最少非对角边。对应更少变更操作的要求,设置对角边的权值为0,非对角边的权值为1。这样,问题也等价于在图中找一条从点(0,0)到(N,M)的权值最小的路径,属于单源最短路问题的一个特例。
下面引入几个概念:
D:待求得的最小权值,也就是原问题中的最小操作步数。(取值范围从0到MAX,MAX = M+N)
k :k = x - y,使用横纵坐标的差来标记对角线,无论线上是否存在对角边。它的范围是从-M到N。
snake :连续的对角边序列(可以为空,为空时即等于终止点)
D-path:用来表示一个权重数为D的路径,也就是水平垂直边数为D的路径。比如D=0的0-path就是一条只有对角边的路径。基于对角线的概念,任意D-path的结束点都会在某个k值对应的对角线上。
这里比较容易混淆的概念就是对角线和对角边,对应到上图,对角线指的是穿过所有点,公式为 x=y+k 的一系列等距斜线。而对角边或snake仅表示那些连接相同字符的实线线段。如下图:
一条D-path的终止点,所在的对角线的k值和D的差一定是偶数,并且范围在-D和D之间。基于这些概念,原论文中先论证了两条理论:
若一条D-path的最远结束点对应的对角线为k,那么最远的(D-1)-path必然达到了对角线 k±1 。
第一条很容易理解,参照上图,构思一个D=3的D-path,会发现它的终止点不可能在-2,0,2这些k值对应的线上。
第二条基于上一条结论,(D-1)-path或(D+1)-path必定会和D-path相差一条水平或垂直边,必然会导致 k值有±1的变动。
基于这两个结论,论文作者给出一种时间复杂度O((M+N)D)的贪心算法。基本步骤如下:
让步数D从0开始增长,最大值为MAX。
对应每个D值,让k从-D到D以步数为2增长。在图上体现为从右上向左下依次循环。
对每个D值的所有k值,保存或更新对应D-path达到的最大x坐标。这保证了D-path优先向右延伸,即优先删除。
随着循环进行,D值不断增长,D-path不断延伸,直到 x >= N 并且 y >= M,说明最远D-path的终止点已经可以到达终点(N,M),算法终止。
文中的伪代码如下:
整个步骤也可以表示为下图,其中(0,-1)的虚拟点和超出图范围的部分,是处于遍历中边界条件的需要,把终止点为(0,0)和全图不含对角边的情况包含其中。
对于最开始举的例子,可以找到的最佳diff路径类似这样:
现在结合上面的伪代码详述一下计算过程:
循环D=0:
k=0。根据if条件k = -D,和预先赋值的V[1] = 0,待判定点的x设置为0。
第8行,y=x-k=0。
第9行判断是否存在(0,0)->(1,1)的对角边,不存在这个边,所以不变更终止点。
第10行保存D=0,k=0时的最大x坐标值:V[0] = 0。
第一轮D=0结束时,唯一最远终止点为(0,0)
循环D=1:
k取值-1或1。分别对应上图D=1时与横纵轴相交的两个点。
k = -1,满足条件 k=-D,所以 x =V[0] = 0, y = x-k = 1。而(0,1)->(1,2)不存在对角边。
记录D=1,k=-1时的x值,V[-1] = 0。
k = 1,不满足第4行的条件,跳转到第7行,x = V[0] + 1 = 1, y = x-k = 0。
记录D=1,k=1的x值,V[1] = 1。
第二轮D=1结束时,达到过的最远终止点为(1,0)和(0,1)。
但因为V数组仅保存最大x坐标,以实现优先删除,记录最远终止点为(1,0)
此时 V[-1] = 0, V[0] = 0, V[1] = 1
循环D=2:
k取值-2,0,2。
k = -2,满足条件 k=-D,设置 x =V[-1] = 0, y = x-k = 2。
第9行循环判断,(0,2)->(1,3)->(2,4)存在连续对角边。所以此条件下终止点为(2,4)。
记录D=2,k=-2时的x值,V[-2] = 2。
k = 0,判断第4行”or”之后的条件,V[-1] < V[1],即 0 < 1,成立。设置 x = 1,y = x-k = 1。
此点存在对角边(1,1)->(2,2),记录D=2,k=0时的x值,V[0] = 2。
k = 2,不满足第4行条件,执行第7行设置 x = V[1]+1 = 2,y = x-k = 0。
此点存在对角边(2,0)->(3,1),记录D=2,k=2时的x值,V[2] = 3。
此轮D=2结束时,达到过的最远终止点为(2,4)(2,2)和(3,1)。
V数组仅保存最大x坐标,所以记录最远终止点为(3,1)。
以下依次循环,直到足以到达(N,M)点。
细心的读者可能会发现,以上步骤仅保存了最远终止点及对应D值,为了明确列出具体路径,还需要保存每一步的终止点和方向,这还需要额外O(D*D)的空间复杂度。于是作者继续提出一种优化方案。
方案基于作者提出的第三条理论:
从序列a到序列b的最佳D-path,与b到a的最佳D-path,必然重合(或翻转重合)在最佳的终止点或snake对角边上。
作者针对这一理论给出了详细论证。因为作者也没太读懂公式,有兴趣可以继续查阅原论文。
这一优化方式把上一部分的单向搜索,转化为从起点和终点向中间搜索公共snake的问题。只要找到一对相反并且同时达到最远的重合路径,就可以停止并输出这个snake或终止点。最差情况需计算两条D-path,这对时间复杂度影响不大。
优化后的算法采用二分法递归查找最佳路径,只需要线性的存储空间,和O((M+N)D)的时间复杂度。这对于较大数据量的对比十分有利。是git和unix系统共同采用的diff方式。
-
存储
+关注
关注
13文章
4892浏览量
90292 -
Git
+关注
关注
0文章
207浏览量
17053
发布评论请先 登录
Git常用的超级实用命令
git命令的基本使用
Git命令之本地分支与远程分支关联和解除

git shell 常用命令
Git 命令+原理 程序员必备的基础

git rebase与相关git merge命令比较
git的命令和参数
Git命令的综合手册怎么找
如何在Linux下打patch(下)
git基本操作命令用法
Git中的最常用命令详解
Git中最常用的命令介绍



评论