 8种经常被忽视的SQL错误用法详细说明
8种经常被忽视的SQL错误用法详细说明
yq.aliyun.com/articles/72501
sql语句的执行顺序:
FROM
1、LIMIT 语句
分页查询是最常用的场景之一,但也通常也是最容易出问题的地方。比如对于下面简单的语句,一般 DBA 想到的办法是在 type, name, create_time 字段上加组合索引。这样条件排序都能有效的利用到索引,性能迅速提升。
SELECT*FROMoperationWHEREtype='SQLStats'ANDname='SlowLog'ORDERBYcreate_timeLIMIT1000,10;
好吧,可能90%以上的 DBA 解决该问题就到此为止。但当 LIMIT 子句变成 “LIMIT 1000000,10” 时,程序员仍然会抱怨:我只取10条记录为什么还是慢?
要知道数据库也并不知道第1000000条记录从什么地方开始,即使有索引也需要从头计算一次。出现这种性能问题,多数情形下是程序员偷懒了。
在前端数据浏览翻页,或者大数据分批导出等场景下,是可以将上一页的最大值当成参数作为查询条件的。SQL 重新设计如下:
SELECT*FROMoperationWHEREtype='SQLStats'ANDname='SlowLog'ANDcreate_time>'2017-03-1614:00:00'ORDERBYcreate_timelimit10;
在新设计下查询时间基本固定,不会随着数据量的增长而发生变化。
2、隐式转换
SQL语句中查询变量和字段定义类型不匹配是另一个常见的错误。比如下面的语句:
mysql>explainextendedSELECT*>FROMmy_balanceb>WHEREb.bpn=14000000123>ANDb.isverifiedISNULL;mysql>showwarnings;|Warning|1739|Cannotuserefaccessonindex'bpn'duetotypeorcollationconversiononfield'bpn'
其中字段 bpn 的定义为 varchar(20),MySQL 的策略是将字符串转换为数字之后再比较。函数作用于表字段,索引失效。
上述情况可能是应用程序框架自动填入的参数,而不是程序员的原意。现在应用框架很多很繁杂,使用方便的同时也小心它可能给自己挖坑。
3、关联更新、删除
虽然 MySQL5.6 引入了物化特性,但需要特别注意它目前仅仅针对查询语句的优化。对于更新或删除需要手工重写成 JOIN。
比如下面 UPDATE 语句,MySQL 实际执行的是循环/嵌套子查询(DEPENDENT SUBQUERY),其执行时间可想而知。
UPDATEoperationoSETstatus='applying'WHEREo.idIN(SELECTidFROM(SELECTo.id,o.statusFROMoperationoWHEREo.group=123ANDo.statusNOTIN('done')ORDERBYo.parent,o.idLIMIT1)t);
执行计划:
+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+|1|PRIMARY|o|index||PRIMARY|8||24|Usingwhere;Usingtemporary||2|DEPENDENTSUBQUERY||||||||ImpossibleWHEREnoticedafterreadingconsttables||3|DERIVED|o|ref|idx_2,idx_5|idx_5|8|const|1|Usingwhere;Usingfilesort|+----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+
重写为 JOIN 之后,子查询的选择模式从 DEPENDENT SUBQUERY 变成 DERIVED,执行速度大大加快,从7秒降低到2毫秒。
UPDATEoperationoJOIN(SELECTo.id,o.statusFROMoperationoWHEREo.group=123ANDo.statusNOTIN('done')ORDERBYo.parent,o.idLIMIT1)tONo.id=t.idSETstatus='applying'
执行计划简化为:
+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+|1|PRIMARY||||||||ImpossibleWHEREnoticedafterreadingconsttables||2|DERIVED|o|ref|idx_2,idx_5|idx_5|8|const|1|Usingwhere;Usingfilesort|+----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+
4、混合排序
MySQL 不能利用索引进行混合排序。但在某些场景,还是有机会使用特殊方法提升性能的。
SELECT*FROMmy_orderoINNERJOINmy_appraiseaONa.orderid=o.idORDERBYa.is_replyASC,a.appraise_timeDESCLIMIT0,20
执行计划显示为全表扫描:
+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra+----+-------------+-------+--------+-------------+---------+---------+---------------+---------+-+|1|SIMPLE|a|ALL|idx_orderid|NULL|NULL|NULL|1967647|Usingfilesort||1|SIMPLE|o|eq_ref|PRIMARY|PRIMARY|122|a.orderid|1|NULL|+----+-------------+-------+--------+---------+---------+---------+-----------------+---------+-+
由于 is_reply 只有0和1两种状态,我们按照下面的方法重写后,执行时间从1.58秒降低到2毫秒。
SELECT*FROM((SELECT*FROMmy_orderoINNERJOINmy_appraiseaONa.orderid=o.idANDis_reply=0ORDERBYappraise_timeDESCLIMIT0,20)UNIONALL(SELECT*FROMmy_orderoINNERJOINmy_appraiseaONa.orderid=o.idANDis_reply=1ORDERBYappraise_timeDESCLIMIT0,20))tORDERBYis_replyASC,appraisetimeDESCLIMIT20;
5、EXISTS语句
MySQL 对待 EXISTS 子句时,仍然采用嵌套子查询的执行方式。如下面的 SQL 语句:
SELECT*FROMmy_neighbornLEFTJOINmy_neighbor_applysraONn.id=sra.neighbor_idANDsra.user_id='xxx'WHEREn.topic_status< 4 AND EXISTS(SELECT 1 FROM message_info m WHERE n.id = m.neighbor_id AND m.inuser = 'xxx') AND n.topic_type <>5
执行计划为:
+----+--------------------+-------+------+-----+------------------------------------------+---------+-------+---------+-----+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+--------------------+-------+------+-----+------------------------------------------+---------+-------+---------+-----+|1|PRIMARY|n|ALL||NULL|NULL|NULL|1086041|Usingwhere||1|PRIMARY|sra|ref||idx_user_id|123|const|1|Usingwhere||2|DEPENDENTSUBQUERY|m|ref||idx_message_info|122|const|1|Usingindexcondition;Usingwhere|+----+--------------------+-------+------+-----+------------------------------------------+---------+-------+---------+-----+
去掉 exists 更改为 join,能够避免嵌套子查询,将执行时间从1.93秒降低为1毫秒。
SELECT*FROMmy_neighbornINNERJOINmessage_infomONn.id=m.neighbor_idANDm.inuser='xxx'LEFTJOINmy_neighbor_applysraONn.id=sra.neighbor_idANDsra.user_id='xxx'WHEREn.topic_status< 4 AND n.topic_type <>5
新的执行计划:
+----+-------------+-------+--------+-----+------------------------------------------+---------+-----+------+-----+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+-------+--------+-----+------------------------------------------+---------+-----+------+-----+|1|SIMPLE|m|ref||idx_message_info|122|const|1|Usingindexcondition||1|SIMPLE|n|eq_ref||PRIMARY|122|ighbor_id|1|Usingwhere||1|SIMPLE|sra|ref||idx_user_id|123|const|1|Usingwhere|+----+-------------+-------+--------+-----+------------------------------------------+---------+-----+------+-----+
6、条件下推
外部查询条件不能够下推到复杂的视图或子查询的情况有:
1、聚合子查询; 2、含有 LIMIT 的子查询; 3、UNION 或 UNION ALL 子查询; 4、输出字段中的子查询;
如下面的语句,从执行计划可以看出其条件作用于聚合子查询之后:
SELECT*FROM(SELECTtarget,Count(*)FROMoperationGROUPBYtarget)tWHEREtarget='rm-xxxx'+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+------------+-------+---------------+-------------+---------+-------+------+-------------+|1|PRIMARY|
确定从语义上查询条件可以直接下推后,重写如下:
SELECTtarget,Count(*)FROMoperationWHEREtarget='rm-xxxx'GROUPBYtarget
执行计划变为:
+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+|1|SIMPLE|operation|ref|idx_4|idx_4|514|const|1|Usingwhere;Usingindex|+----+-------------+-----------+------+---------------+-------+---------+-------+------+--------------------+
关于 MySQL 外部条件不能下推的详细解释说明请参考以前文章:MySQL · 性能优化 · 条件下推到物化表http://mysql.taobao.org/monthly/2016/07/08
7、提前缩小范围**
先上初始 SQL 语句:
SELECT*FROMmy_orderoLEFTJOINmy_userinfouONo.uid=u.uidLEFTJOINmy_productinfopONo.pid=p.pidWHERE(o.display=0)AND(o.ostaus=1)ORDERBYo.selltimeDESCLIMIT0,15
该SQL语句原意是:先做一系列的左连接,然后排序取前15条记录。从执行计划也可以看出,最后一步估算排序记录数为90万,时间消耗为12秒。
+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+|1|SIMPLE|o|ALL|NULL|NULL|NULL|NULL|909119|Usingwhere;Usingtemporary;Usingfilesort||1|SIMPLE|u|eq_ref|PRIMARY|PRIMARY|4|o.uid|1|NULL||1|SIMPLE|p|ALL|PRIMARY|NULL|NULL|NULL|6|Usingwhere;Usingjoinbuffer(BlockNestedLoop)|+----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+
由于最后 WHERE 条件以及排序均针对最左主表,因此可以先对 my_order 排序提前缩小数据量再做左连接。SQL 重写后如下,执行时间缩小为1毫秒左右。
SELECT*FROM(SELECT*FROMmy_orderoWHERE(o.display=0)AND(o.ostaus=1)ORDERBYo.selltimeDESCLIMIT0,15)oLEFTJOINmy_userinfouONo.uid=u.uidLEFTJOINmy_productinfopONo.pid=p.pidORDERBYo.selltimeDESClimit0,15
再检查执行计划:子查询物化后(select_type=DERIVED)参与 JOIN。虽然估算行扫描仍然为90万,但是利用了索引以及 LIMIT 子句后,实际执行时间变得很小。
+----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+|id|select_type|table|type|possible_keys|key|key_len|ref|rows|Extra|+----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+|1|PRIMARY|
8、中间结果集下推
再来看下面这个已经初步优化过的例子(左连接中的主表优先作用查询条件):
SELECTa.*,c.allocatedFROM(SELECTresourceidFROMmy_distributedWHEREisdelete=0ANDcusmanagercode='1234567'ORDERBYsalecodelimit20)aLEFTJOIN(SELECTresourcesid,sum(ifnull(allocation,0)*12345)allocatedFROMmy_resourcesGROUPBYresourcesid)cONa.resourceid=c.resourcesid
那么该语句还存在其它问题吗?不难看出子查询 c 是全表聚合查询,在表数量特别大的情况下会导致整个语句的性能下降。
其实对于子查询 c,左连接最后结果集只关心能和主表 resourceid 能匹配的数据。因此我们可以重写语句如下,执行时间从原来的2秒下降到2毫秒。
SELECTa.*,c.allocatedFROM(SELECTresourceidFROMmy_distributedWHEREisdelete=0ANDcusmanagercode='1234567'ORDERBYsalecodelimit20)aLEFTJOIN(SELECTresourcesid,sum(ifnull(allocation,0)*12345)allocatedFROMmy_resourcesr,(SELECTresourceidFROMmy_distributedWHEREisdelete=0ANDcusmanagercode='1234567'ORDERBYsalecodelimit20)aWHEREr.resourcesid=a.resourcesidGROUPBYresourcesid)cONa.resourceid=c.resourcesid
但是子查询 a 在我们的SQL语句中出现了多次。这种写法不仅存在额外的开销,还使得整个语句显的繁杂。使用 WITH 语句再次重写:
WITHaAS(SELECTresourceidFROMmy_distributedWHEREisdelete=0ANDcusmanagercode='1234567'ORDERBYsalecodelimit20)SELECTa.*,c.allocatedFROMaLEFTJOIN(SELECTresourcesid,sum(ifnull(allocation,0)*12345)allocatedFROMmy_resourcesr,aWHEREr.resourcesid=a.resourcesidGROUPBYresourcesid)cONa.resourceid=c.resourcesid
总结
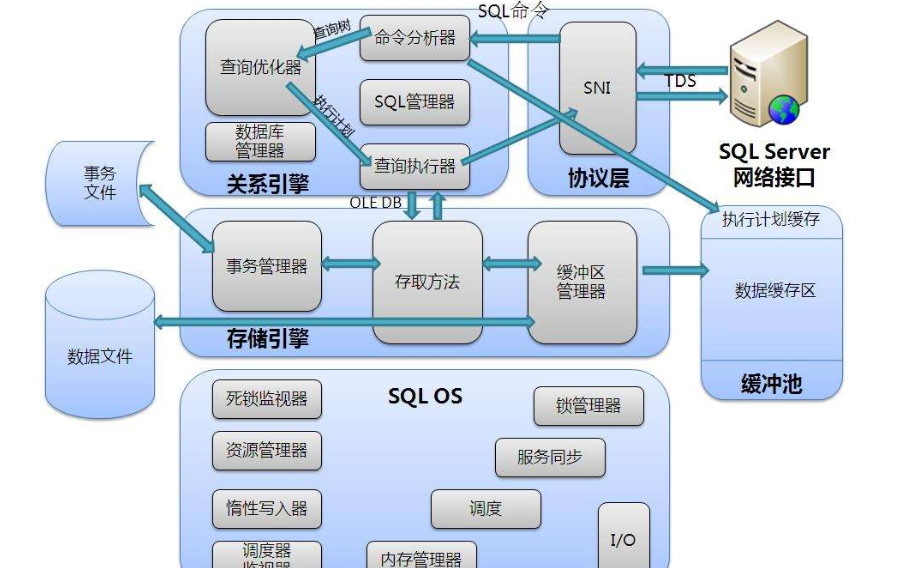
数据库编译器产生执行计划,决定着SQL的实际执行方式。但是编译器只是尽力服务,所有数据库的编译器都不是尽善尽美的。
上述提到的多数场景,在其它数据库中也存在性能问题。了解数据库编译器的特性,才能避规其短处,写出高性能的SQL语句。
程序员在设计数据模型以及编写SQL语句时,要把算法的思想或意识带进来。
编写复杂SQL语句要养成使用 WITH 语句的习惯。简洁且思路清晰的SQL语句也能减小数据库的负担 。
-
SQL
+关注
关注
1文章
775浏览量
44312 -
数据库
+关注
关注
7文章
3856浏览量
64805 -
编译器
+关注
关注
1文章
1642浏览量
49345
原文标题:8 种常被忽视的 SQL 错误用法
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
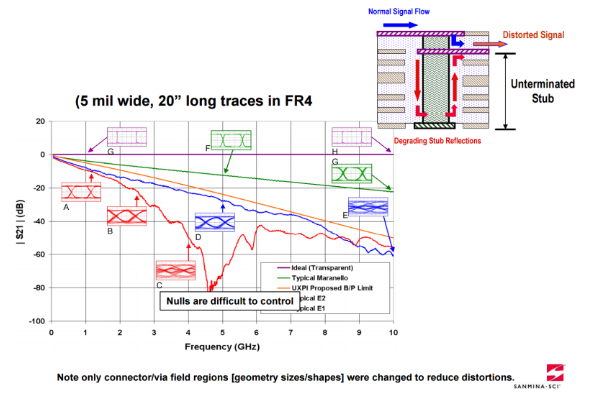
pcb设计信号失真常被忽视的来源——过孔








 工商网监
工商网监
评论