 CVPR 2019:中科院、牛津等提出SiamMask网络,视频跟踪最高精度
CVPR 2019:中科院、牛津等提出SiamMask网络,视频跟踪最高精度
今年CVPR有一篇亮眼的视觉跟踪方面的论文,作者提出新算法SiamMask,在视频跟踪任务上达到最优性能,并且在视频目标分割上取得了当前最快的速度。作者来自中科院自动化所、牛津大学等,本文带来一作自动化所王强的解读。
今年的 CVPR 的结果已经完全公布,我参与的两篇文章SiamMask和SiamRPN++均被接收。遗憾的是 SiamMask 最终并没有被 reviewer 认可,只取得了 poster。
SiamMask 的测试代码:foolwood/SiamMask
视频跟踪经典工作
在两年前,当我们提起视觉跟踪(Visual Tracking),我们的脑海里总是灌满了相关滤波(KCF,SRDCF,CF2,CCOT,ECO... 等等经典工作在我的脑海里飘荡)。如果给这个时代截取一篇最经典的工作,我想我会选择 KCF。他是真的将视觉跟踪推向流行,让整个领域真的沸腾起来的工作。如果现在来分析他之所以能统治跟踪领域的原因,我觉得主要是两点:足够高效 + 开源。高效到只需要 10 行以内的代码就可以实现核心计算,随便一个 CPU 就可以跑到 200FPS 以上。这极大程度上拉低了视觉跟踪领域的门槛,让所有人很容易进入这个领域。开源,这个词汇现在看已经是土的不能再土的词汇。真的做起来却也存在很多阻力。
当然,除了怀旧以外。我们也会经常反思甚至有些诧异,似乎视觉跟踪和整个 CV 大领域走到了不同的方向,深度学习在跟踪领域并没有得到什么用武之地。当然,所有新的方向的产生大都遵循着量变到质变的基本原则。下图可以看到到 CVPR2018 时候的时间跟踪发展,相关滤波的发展已经经过了几代迭代,深度学习方向也在不断积攒(广度高而深度浅)。大家都在尝试可行的方向。目前来看,应该是以 SiamFC 为代表的 Siamese Tracker 脱颖而出。
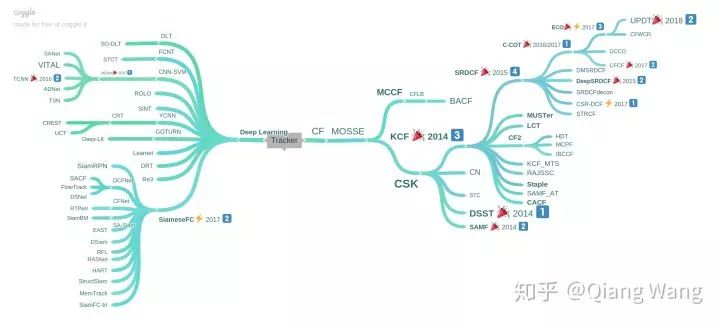
视觉跟踪在 CVPR2018 时的发展分布
而 Siamese 网络的概念应用于目标跟踪的源头应该从 SINT 这篇文章开始,但真正开始流行却是从 SiamFC 开始。简洁优雅的框架让它得变得流行,像极了上一波的 KCF。
有关 SiamFC 的讨论可以见上一篇:Qiang Wang:CVPR2018 视觉跟踪 (RASNet)
https://zhuanlan.zhihu.com/p/34222060
SiamMask:视频跟踪到底是跟踪什么
Motivation:视频跟踪到底是跟踪什么?
长久以来,我们的思维倾向于陷入舒适区。当 A 做了物体检测,我们尝试改网络,改 loss,别的领域 trick 拿来就是一篇。而我们常常忽略了更为重要的问题,到底这个问题的该如何定义,这点极为重要。
对于目标跟踪而言,一般论文开篇通常都会说在第一帧给定目标位置,在后续帧中预测目标的位置。然而如何对后续帧中表述的定义直接影响了整个跟踪领域的发展。
为了方便表述,早期的跟踪算法都是坐标轴对齐的的矩形框。但随着跟踪精度的不断提升,数据集的难度在不断提升,在 VOT2015 时即提出使用旋转矩形框来作为标记。在 VOT2016 的时候提出自动的通过 mask 来生成旋转框的方法。更为本质的,我们会发现,这个旋转的矩形框实际上就是 mask 的一种近似。我们所要预测的实际上就是目标物体的 mask。利用 mask 才能得到精度本身的上界。
我自己将 2013 年以后的跟踪分为几类,第一类是预测 score 的方法,这类算法以相关滤波和 SiameFC 为代表。通过预测候选区域的score map来得到物体的位置,物体的尺度大小通常是通过图像金字塔得到。同时无法得到物体的长宽比变化。
第二类就是以 GOTURN 和 SiamRPN 为代表的做 boundingbox regression 的方法。这也是 SiamRPN 取得当前最好结果的核心所在,充分挖取精度方向的红利。实际上并不是 SiamRPN 预测的有多稳定,而是在预测正确的时候,会给出更为精确的 box。利用网络预测长宽比可以调整 box,这个方向一直以来被大家所忽视,所以 SiamRPN 很快杀出重围。
而在物体发生旋转的时候,简单的 box 的表述通常会产生极大的损失,这实际上就是表述本身存在的缺陷。而为了进一步探索在精度上存在的问题。我们更进一步,直接预测物体的 mask。这种表述使得我们可以得到最为准确的 box。最直观的利用一个简单的事例的可视化就可以看出,这三种算法的区别(左中右分别是SiamFC | SiamRPN |SiamMask)。
同时,对于视频目标分割(VOS)领域,之前普遍流行的算法是利用语义分割网络在线进行一个二分类的训练,然后再后续帧进行预测。这种方法在训练过程中一般都会花费数分钟,给人一种电脑假死的感觉。最近越来越多的不需要在线 finetune 的算法被提出。但其速度仍然无法到达令人满意的状态,例如 FAVOS 和 OSMN 分别需要 1s / 帧,120ms / 帧。这距离真正的实时运行还是有一定差异。另一方面,VOS 算法的第一帧需要给定目标的 mask,这在人机交互的场景中很难时间,这个 mask 获取成本过高。
所以我们提出了对视觉目标跟踪(VOT)和视频目标分割(VOS)的统一框架 SiamMask。我们将初始化简化为视频跟踪的 box 输入即可,同时得到 box 和 mask 两个输出。

具体实现
当有了上述的 motivation 之后,具体实现非常简单,只需要在 siamese 网络架构中额外增加一个 Mask 分支即可。
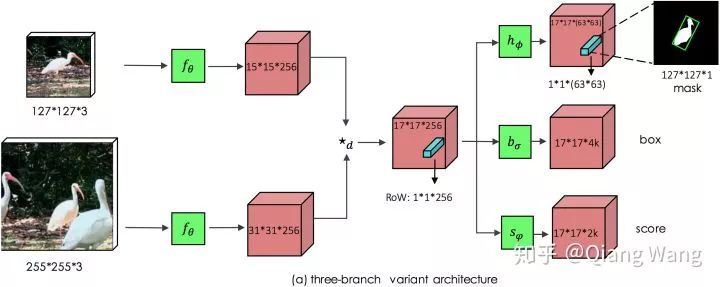
但是相较于预测 score 和 box,mask 的预测会更为困难。我们这里使用的表述方法,是利用一个 vector 来编码一个 RoW 的 mask。这使得每个 prediction 位置具有非常高的输出维度(63*63), 我们通过 depthwise 的卷积后级联 1x1 卷积来升维来实现高效运行。这样即构成了我们的主要模型框架。
但直接预测的 Mask 分支的精度并不太高。所以提出了如下图所示的Refine Module用来提升分割的精度,refine module 采用 top-down 的结构。
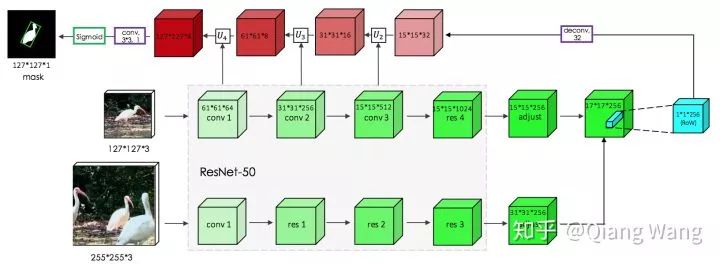
这一部分借鉴了 SharpMask 的思路。deepmask 和 sharpmask 是 facebook 在 2015-2016 年提出的物体分割 proposal 框架。我进行了一个重现foolwood/deepmask-pytorch。
https://github.com/foolwood/deepmask-pytorch
实验结果
对照实验(ablation study)结果方面,我们首先通过实验分析验证了所提出的 Mask 的输出表达对于跟踪问题的贡献。通过进行 Oracle 实验分析,可以明确得出,旋转矩形框的平均 IoU 会远好于只预测坐标轴对齐的矩形框。尤其是在更高的 IoU 阈值下,旋转矩形框的优势更为明显。当对比 SiamFC,SiamRPN 的时候,SiamMask 对于整体的精度提升非常显著。对于输出 mask 转换为 box,有多重选择,我们使用了较为容易生成的最小外包矩形(MBR)。按照 VOT 的优化方式生成的框的质量会更高,但按照优化算法生成太慢。如果有编码好的同学可以把这个加速,我相信我们算法的精度至少可以再提升一个百分点,非常欢迎尝试之后在我们的 github 上提 Pull Requests。
优化的 box 的 matlab:http://cmp.felk.cvut.cz/~vojirtom/dataset/votseg/data/optimize_bboxes.m
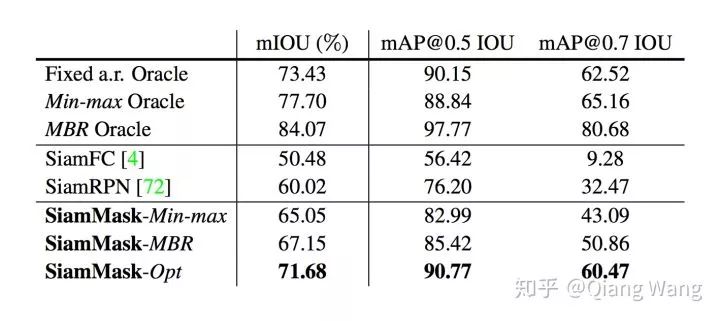
在视频跟踪领域(VOT),VOT2016 和 VOT2018 数据集上的性能,我们的方法已经到达到SOTA 的结果,同时保持了 55fps 的超实时的性能表现。
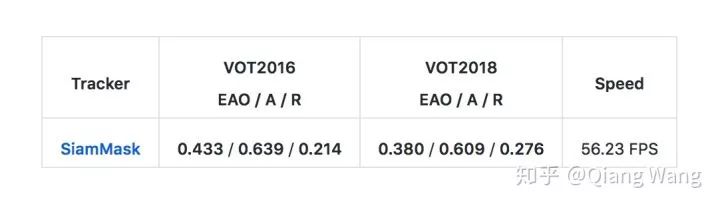
在视频目标分割领域(VOS),我们取得了当前最快的速度。在 DAVIS2017 和 Youtube-VOS 上,我们和最近发表的较为快速的算法对比,我们的算法可以取得可比较的分割精度,同时速度快了近一个数量级。对比经典的 OSVOS,我们的算法快了近三个数量级,使得视频目标分割可以得到实际使用。
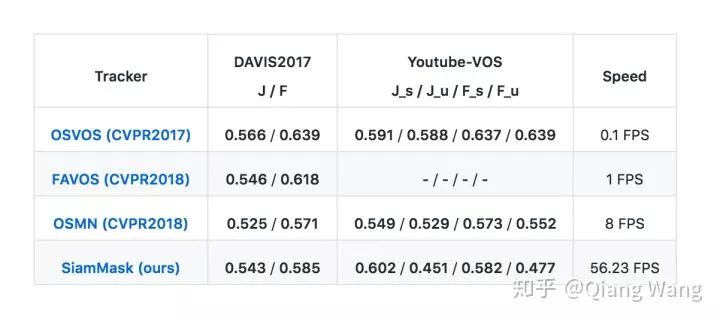
此外,我们需要强调的是,视频分割任务目前的视频片段都较短,我们的 decay 要远小于其他算法,这意味着在更长的视频片段中,我们的算法性能会保持的更好。
Adobe MAX 2018 FastMask 项目
我也使用 SiamMask 做了一个类似的项目,当然精度上和 Adobe 的 FastMask 肯定存在差距。但我们的方法可以很容易的生成一些表情包或者 b 站的智能防挡弹幕。
CVPR2019 跟踪领域发展
从今年接收的文章已经可以明显看出来,跟踪领域已经基本完成换代更新。接收的文章中 Siamese 网络的改进工作已经占据了主导的地位。
SiamRPN++,CIR两篇都是围绕如何使用深度网络主干这个问题,两篇文章都中了 oral。这个问题一直困扰着整个跟踪圈子,在此之前的所有工作都采用的是 alexnet 为主的网络架构。不能使用现代网络架构一直困扰着整个跟踪领域的发展。SiamRPN++ 通过数据增强的方法解决训练的空间位置偏见。CIR 通过 crop 操作从网络架构上减弱网络 padding 带来的学习偏见,通过大量的实验分析了感受野等因素对学习的影响。总的来说,当网络问题被解决了之后直接导致了现在在几乎所有的数据集上,SiamRPN++ 已经超过了相关滤波的方法。
在 SiamRPN++ 的基础上,网络主干问题已经被解决,我们可以做更多方向的探索。我们可以非常简单的让输出做更复杂的预测,这就催生了SiamMask这篇文章。
SPM和C-RPN两篇都算是多阶段的 SiamRPN 扩展。SPM 就是典型的 faster-RCNN 的思路做跟踪,只是最后的 score fusion 的方式可以再优雅一些。C-RPN 当然就是Cascade R-CNN: Delving into High Quality Object Detection在跟踪领域的翻版。两者的思路都很直接,通过第二 / N 阶段来学习更精细的判别。
Martin Danelljan大神的ATOM: Accurate Tracking by Overlap Maximization这篇肯定也是重量级的文章。Martin 大神并没有 fellow SiamRPN 的架构,转而使用粒子滤波采样搭配 IoU 预测,多次迭代得到目标结果。在多个库上取得了非常惊人的结果。这项工作我觉得最突破的点是网络学习的问题实际上更 hard,更符合跟踪的需求。
LaSOT这个测评集的接收也是常规操作。希望各位大佬能继续维护好这个库。最近跟踪的数据库相当多,人们都意识到之前的数据已经无法满足深度学习的跟踪算法。
关于 Siamese Tracking 的未来研究方向
当你阅读了一定的文章以及有现成的代码之后,下面当然是如何着手改进。我自己总结了一些小的可以改进的方向,仅供参考。
1)高效的在线学习算法:进展到目前为止,我的所有实验研究表明。Siamese 网络无法真正意义上抑制背景中的困难样本。离线的学习从本质上无法区分两个长相相似的人或者车。而 CF 相关算法可以通过分析整个环境的上下文关系来进行调整。如果对于提升整个算法的上界(偏学术)的角度考虑,在线学习有必要。如果正常的工程使用,我认为目前的算法只要在相应的场景中进行训练就足够了。
2)精确输出表达:今年我们的工作提出额外的 mask 输出。可直接扩展的思路为关键点输出(CornerNet / PoseTrack),极点预测(ExtremeNet),甚至 6D pose 跟踪。本质上是通过网络可以预测任何与目标相关的输出。大家可以任意的发散思维。
3)定制网络架构:其中包含两个子方向,一个是追求精度的去探索究竟什么样的网络架构会有利于当前的跟踪框架的学习。另一个有价值的子方向是如何构建超快速的小网络用于实际工程。工程项目中有时并没有 GPU 的资源供使用,如何提供 “廉价” 的高质量跟踪算法也具有很强的实际意义。当对网络进行裁剪之后,很容易达到 500FPS 的高性能算法来对传统的 KCF 进行真正的替换。
4)离线训练学习优化:目前的跟踪算法在相似性学习方向还是过于简单,如果去设计更为有效的度量学习方案,应该会有一定的提升。同时我们也并没有很好的掌握网络的训练。当前的训练策略是将网络主干的参数进行固定,先训练 head。然后逐步放开。实际上我们发现,当直接将所有层全部放开一起训练的时候,网络的泛化性能会显著下降。另一个方面,train from scratch 的概念已经在检测领域非常普遍了。跟踪的网络目前我们的经验在跟踪方面并不 work。
5)更细粒度预测:这一条实际上是上一条的续集,就是专注于 score 分支的预测。现在大家的做法是 > 0.6 IoU 的都当做前景(正样本),但实际上正样本之间还是有较大的差异的。跟踪本质上也是不断预测一个非常细小物体帧间运动的过程,如果一个网络不能很好的分辨细小的差异,他可能并不是一个最优的设计选择。这也是 ATOM 的 IoUNet 主攻的方向。
6)泛化性能提升:非常推荐自动化所黄凯奇老师组的GOT-10k数据集,数据组织的非常棒。黄老师组在 one-shot learning 领域有着深厚的积淀,所以站在这个领域的角度,他们提出了严格分离训练集和测试集的物体类别来验证泛化性能。所以原则上所有 one-shot learning 方向的一些嵌入学习方法都可以移过来用。同时,我觉得 Mask-X-RCNN,segment everything 这个思路可以借鉴。本质上我也不得不承认,基于深度学习的跟踪算法存在泛化性能问题。我们有理由怀疑跟踪是否会在未知的类别上有较好的泛化性能,实际上肯定是会下降。
7)long-term 跟踪框架:截止到目前为止,虽然 VOT 组委会以及牛津这边的 OxUVA 都有专门的 long-term 的数据集,但 long-term 算法并没有一个较好的统一框架出来。关于这方面的研究似乎有点停滞,今年大连理工的文章非常可惜,我觉得质量非常不错。
-
自动化
+关注
关注
29文章
5509浏览量
79081 -
数据集
+关注
关注
4文章
1205浏览量
24636 -
深度学习
+关注
关注
73文章
5492浏览量
120958
原文标题:CVPR 2019:中科院、牛津等提出SiamMask网络,视频跟踪最高精度
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论