 Google开源了一款名为TensorFlow Federated的框架
Google开源了一款名为TensorFlow Federated的框架
【导语】据了解,全球有 30 亿台智能手机和 70 亿台边缘设备。每天,这些电话与设备之间的交互不断产生新的数据。传统的数据分析和机器学习模式,都需要在处理数据之前集中收集数据至服务器,然后进行机器学习训练并得到模型参数,最终获得更好的产品。
但如果这些需要聚合的数据敏感且昂贵的话,那么这种中心化的数据收集手段可能就不太适用了。
去掉这一步骤,直接在生成数据的边缘设备上进行数据分析和机器学习训练呢?
近日,Google 开源了一款名为 TensorFlow Federated (TFF)的框架,可用于去中心化(decentralized)数据的机器学习及运算实验。它实现了一种称为联邦学习(Federated Learning,FL)的方法,将为开发者提供分布式机器学习,以便在没有数据离开设备的情况下,便可在多种设备上训练共享的 ML 模型。其中,通过加密方式提供多一层的隐私保护,并且设备上模型训练的权重与用于连续学习的中心模型共享。
传送门:https://www.tensorflow.org/federated/
实际上,早在 2017 年 4 月,Google AI 团队就推出了联邦学习的概念。这种被称为联邦学习的框架目前已应用在 Google 内部用于训练神经网络模型,例如智能手机中虚拟键盘的下一词预测和音乐识别搜索功能。

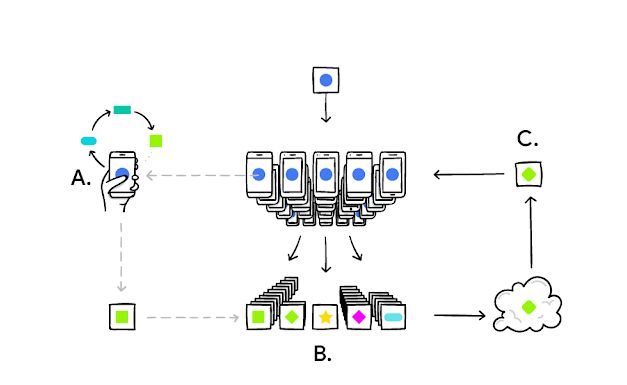
图注:每台手机都在本地训练模型(A);将用户更新信息聚合(B);然后形成改进的共享模型(C)。
DeepMind 研究员Andrew Trask 随后发推称赞:“Google 已经开源了Federated Learning……可在数以百万计的智能手机上共享模型训练!”
让我们一起来看看使用教程:
从一个著名的图像数据集 MNIST 开始。MNIST 的原始数据集为 NIST,其中包含 81 万张手写的数字,由 3600 个志愿者提供,目标是建立一个识别数字的 ML 模型。
传统手段是立即将 ML 算法应用于整个数据集。但实际上,如果数据提供者不愿意将原始数据上传到中央服务器,就无法将所有数据聚合在一起。
TFF 的优势就在于,可以先选择一个 ML 模型架构,然后输入数据进行训练,同时保持每个数据提供者的数据是独立且保存在本地。
下面显示的是通过调用 TFF 的 FL API,使用已由 GitHub 上的“Leaf”项目处理的 NIST 数据集版本来分隔每个数据提供者所写的数字:
GitHub 传送链接:https://github.com/TalwalkarLab/leaf
#Loadsimulationdata.source,_=tff.simulation.datasets.emnist.load_data()defclient_data(n):dataset=source.create_tf_dataset_for_client(source.client_ids[n])returnmnist.keras_dataset_from_emnist(dataset).repeat(10).batch(20)#WrapaKerasmodelforusewithTFF.defmodel_fn():returntff.learning.from_compiled_keras_model(mnist.create_simple_keras_model(),sample_batch)#Simulateafewroundsoftrainingwiththeselectedclientdevices.trainer=tff.learning.build_federated_averaging_process(model_fn)state=trainer.initialize()for_inrange(5):state,metrics=trainer.next(state,train_data)print(metrics.loss)
除了可调用 FL API 外,TFF 还带有一组较低级的原语(primitive),称之为 Federated Core (FC) API。这个 API 支持在去中心化的数据集上表达各种计算。
使用 FL 进行机器学习模型训练仅是第一步;其次,我们还需要对这些数据进行评估,这时就需要 FC API 了。
假设我们有一系列传感器可用于捕获温度读数,并希望无需上传数据便可计算除这些传感器上的平均温度。调用 FC 的 API,就可以表达一种新的数据类型,例如指出 tf.float32,该数据位于分布式的客户端上。
READINGS_TYPE=tff.FederatedType(tf.float32,tff.CLIENTS)
然后在该类型的数据上定义联邦平均数。
@tff.federated_computation(READINGS_TYPE)defget_average_temperature(sensor_readings):returntff.federated_average(sensor_readings)
之后,TFF 就可以在去中心化的数据环境中运行。从开发者的角度来讲,FL 算法可以看做是一个普通的函数,它恰好具有驻留在不同位置(分别在各个客户端和协调服务中的)输入和输出。

例如,使用了 TFF 之后,联邦平均算法的一种变体:
参考链接:https://arxiv.org/abs/1602.05629
@tff.federated_computation(tff.FederatedType(DATASET_TYPE,tff.CLIENTS),tff.FederatedType(MODEL_TYPE,tff.SERVER,all_equal=True),tff.FederatedType(tf.float32,tff.SERVER,all_equal=True))deffederated_train(client_data,server_model,learning_rate):returntff.federated_average(tff.federated_map(local_train,[client_data,tff.federated_broadcast(server_model),tff.federated_broadcast(learning_rate)]))
目前已开放教程,可以先在模型上试验现有的 FL 算法,也可以为 TFF 库提供新的联邦数据集和模型,还可以添加新的 FL 算法实现,或者扩展现有 FL 算法的新功能。
据了解,在 FL 推出之前,Google 还推出了 TensorFlow Privacy,一个机器学习框架库,旨在让开发者更容易训练具有强大隐私保障的 AI 模型。目前二者可以集成,在差异性保护用户隐私的基础上,还能通过联邦学习(FL)技术快速训练模型。
-
Google
+关注
关注
5文章
1772浏览量
57883 -
机器学习
+关注
关注
66文章
8454浏览量
133170 -
数据集
+关注
关注
4文章
1210浏览量
24865
原文标题:让数百万台手机训练同一个模型?Google把这套框架开源了
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络的实现工具与框架
Google AI Edge Torch的特性详解

介绍一款Java开发的开源MES系统





 工商网监
工商网监
评论