 让机器学习模型不再是”黑盒子“
让机器学习模型不再是”黑盒子“
提高机器学习模型的可解释性和透明度,将有助于模型的除错、引导未来的数据收集方向、为特征构建和人类决策提供真正可靠的信息,最终在人与模型之间建立信任。
过去几年来,人工智能研究人员在图像识别、自然语言理解和棋类等领域取得了重大突破。但由于缺乏对复杂机器学习模型的真正理解,导致模型在传播时出现了偏见,这种偏见在零售、面部识别和语言理解等领域的应用中出现了多次。
说到底,机器学习模型大多数时候仍然是“黑盒子”,很多时候可以拿来用,但具体原理并不十分清楚,即缺乏足够的“可解释性”。
什么是模型的”可解释性“?不同人群定义不一样
所谓模型的可解释性,是指人类能够在何种程度上一致地估计、理解并遵循模型的预测,以及在模型出错时,在何种程度上能够成功检测到。
可解释性对不同的人群有着不同的含义:
对于数据科学家来说,意味着更好地理解模型,掌握模型性能好坏情况以及原因。这些信息有助于数据科学家构建性能更强大的模型。
对于业务利益相关者而言,模型具备可解释性有助于深入了解为什么人工智能系统做出特定决定以确保公平性,维护用户和品牌。
对于用户来说,这意味着要理解模型做出决策的原因,并在模型出错时允许进行有意义的挑战。
对于专家或监管机构来说,它意味着审核AI系统并遵循决策流程,尤其是在系统出现问题时。
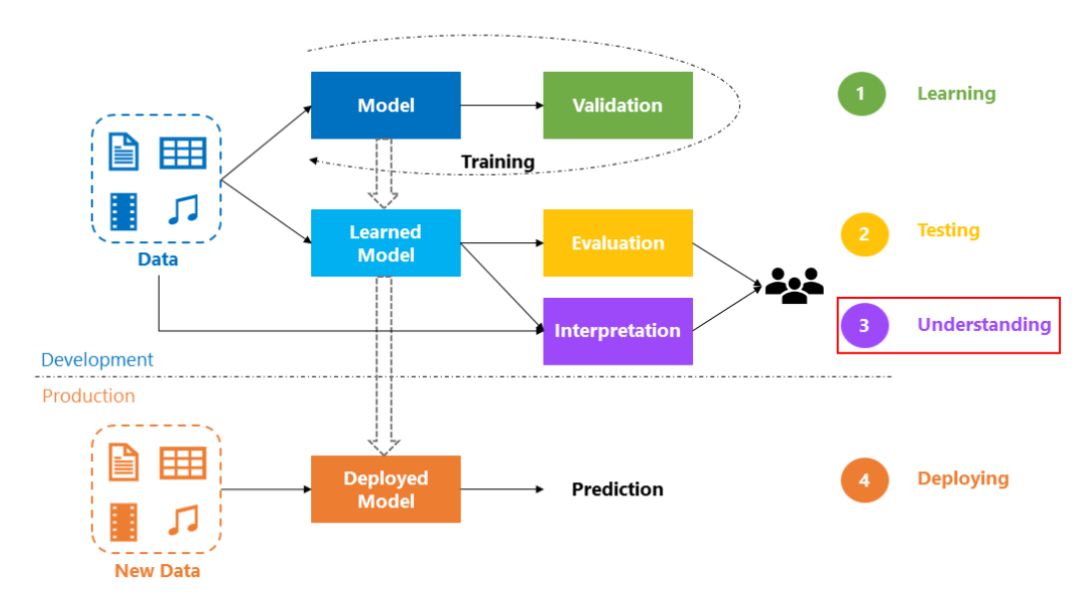
微软的团队数据科学流程(TDSP),其中一个重要环节就是对模型的理解
机器学习模型的可解释性可以展示模型正在学习什么内容,而洞悉模型的内部,要比大多数人预想的更加有用。
在过去的10年里,我采访了许多数据科学家,其中模型可解释性技术是我最喜欢的主题,在这一问题上,甚至可以将最优秀的数据科学家与普通科学家区分开来。
有些人认为机器学习模型是黑盒子,可以做出预测,但却无法理解。但最好的数据科学家知道如何从任何模型中提取出关于真实世界的见解。对于任何给定的模型,优秀的数据科学家可以轻松回答类似下面的问题:
模型认为哪些特征最重要?
对于来自模型的任何预测来说,数据的每个特征会对预测结果产生哪些影响?
不同特征之间的哪些相互作用对模型的预测结果影响最大?
回答这些问题比许多人意识到的更为广泛。无论你是从Kaggle学习技术还是从统计学习元素这样的综合资源中学习,这些技术都将彻底改变构建,验证和部署机器学习模型的方式。
提高模型可解释性有什么用?
关于模型的可解释性技术,以下是五个最重要的应用方式:
调试
为模型特征构建提供信息
指导未来的数据收集方向
为人类决策提供建议
在人与模型间建立信任
调试
世界上存在很多可靠性不高,杂乱无章、数量众多的数据。在编写预处理代码时,这些数据可能会成为潜在的错误源头,增加目标泄漏的可能性,在实际数据科学项目中的某些时候出现错误可以说是一种常态,而不是例外。
由于错误出现的频率和潜在的灾难性后果,除错是数据科学中最有价值的技能之一。了解模型发现的模式将帮助你确定,模型对现实世界的理解与你自己的观点出现了不一致,而这通常是查找错误的第一步。
为模型的特征构建提供信息
特征构建通常是提高模型精度的最有效的方法。这个过程通常涉及使用原始数据或先前创建的特征的转换重复创建新特征。
有时你可以只凭借关于底层主题的直觉来完成这个过程。但是,当模型有100个原始特征或缺乏有关您正在处理的主题的背景知识时,就需要更多指引了。这时候,如果模型仍是黑盒子,不可解释的,完成这一过程可能会非常困难,甚至是不可能的。
未来,随着越来越多的数据集的原始特征数量达到成百上千的级别,这种方式无疑会变得越来越重要。
指导未来的数据收集方向
对于从网上下载的数据集,你并没有控制能力。但是,许多利用数据科学的企业和组织都有机会扩展其收集的数据类型。收集新类型的数据可能成本高昂,又不方便,因此只有在知道某类数据值得收集,他们才会去这样做。
如果模型是可解释的,就可以很好地理解当前特征的价值,进而更有可能推断出哪些新型数据是最有用的,从而指导未来数据的收集方向。
为人类决策提供建议
有些决策行为是由模型自动完成的。比如,当你访问亚马逊的网站时,你所看到的网页内容并不是由真人匆忙决定的。不过,确实许多重要的决定都是由人做出的。对于这些决策,观点洞察可能比预测结果更有价值。
在人与模型间建立信任
在没有验证一些基本事实的情况下,许多人认为他们无法信任模型来进行重要决策。考虑到数据出现错误的几率,这是一个明智的预防措施。
在实际应用中,如果模型显示的结果符合他们对问题的一般见解,将有助于在人与模型间建立一种信任,即使对数据科学知之甚少的人而言也是如此。
不过,在Adrian Weller的一篇有趣的论文中,提出AI透明度应该是实现目标的手段,而不是目标本身。Weller认为,更高的模型透明度可能产生对所有人不利的结果,并可能使AI被恶意者滥用。
毫无疑问,AI系统必须足够安全,并且能够防范对抗性攻击,这样,讨论模型的可解释性和透明度才是有积极意义的。
-
人工智能
+关注
关注
1797文章
47901浏览量
240923 -
模型
+关注
关注
1文章
3376浏览量
49327 -
机器学习
+关注
关注
66文章
8455浏览量
133184
原文标题:告别AI模型黑盒子:可解释性将是数据科学的下一个“超能力”
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器学习模型市场前景如何
如何让陪伴机器人更懂家庭
【「具身智能机器人系统」阅读体验】2.具身智能机器人大模型
什么是机器学习?通过机器学习方法能解决哪些问题?

麻省理工学院推出新型机器人训练模型
AI大模型与深度学习的关系
AI大模型与传统机器学习的区别
构建语音控制机器人 - 线性模型和机器学习





 工商网监
工商网监
评论