 注意力机制的诞生、方法及几种常见模型
注意力机制的诞生、方法及几种常见模型
注意力机制(Attention)已经成为深度学习必学内容之一,无论是计算机视觉还是自然语言处理都可以看到各种各样注意力机制的方法。之前我们曾在一篇干货文章《关于深度学习中的注意力机制,这篇文章从实例到原理都帮你参透了》中,从实例到原理帮助大家参透注意力机制的工作原理。今天,我们将再度为大家梳理全部理论要点,是大家学习的必备资料之一,并为后续掌握最新流行的注意力机制保驾护航。
在本篇博客中,作者不仅概述了注意力机制是如何被创造出来的,也详细探讨了时下最流行的注意力机制相关的方法和模型,比如Transformer、SNAIL、神经图灵机(Neural Turing Machines)以及自注意力生成对抗网络(SAGAN),一度成为不少学习者的参考资料。
该篇博客结构如下:
序列到序列(Seq2Seq)模型究竟有什么问题?
为翻译而生
定义
注意力机制模型家族
归纳总结
自注意力机制(Self-attention)
Soft & Hard Attention
Global & Local Attention
神经图灵机
读写机制
注意力机制
指针网络(Pointer Network)
Transformer
Key, Value and Query
多头自注意力机制(Multi-Head Self-Attention)
编码器(Encoder)
解码器(Decoder)
完整的结构
SNAIL
自注意力生成对抗网路(Self-Attention GAN)
参考
在某种程度上,注意力取决于我们如何对图像的不同区域进行视觉注意或将一个句子中的单词关联起来。
以图1 中的柴犬图为例。
图1 一只可爱的柴犬穿着一件人类的外套。该图片来自于Instagram @mensweardog
人类的视觉注意力机制使我们能够以一种“高分辨率”的形式关注到图像的某个区域(例如当你观察图中黄色框标注的狗耳朵的时候),而同时以一种“低分辨率”的形式感知着周围的图像(例如这个时候你的余光中雪的背景,还有柴犬所穿的外套的样子),然后调整眼睛所关注的焦点或者相应地进行推断。
如果将图像扣掉一小块,我们也可以根据图像中其余的内容线索推测出被扣掉的内容究竟是什么。比如可以推测出被黄色框扣掉的内容是一个尖尖的耳朵,因为我们看到了一个狗的鼻子,右边另一个尖尖的耳朵以及柴犬的神秘眼神(图中红色框所示的内容)。对于耳朵的预测,底部的毛衣和毯子就不如上述狗的特征有用。
类似的,我们同样可以解释,一个句子或近似语境中单词之间的关系。在一句话中,当我们看到“吃”这个单词的时候,我们很快就会遇到一个食物词(apple)。虽然颜色术语(green)描述了食物,但可能跟“吃”之间没有直接的关系。
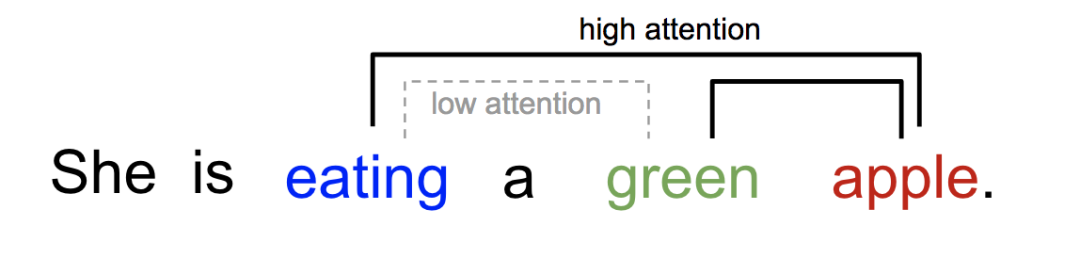
图2 同一个句子当中,不同词之间具有不同的关系
简而言之,深度学习中的注意力机制可以被广义地定义为一个描述重要性的权重向量:通过这个权重向量为了预测或者推断一个元素,比如图像中的某个像素或句子中的某个单词,我们使用注意力向量定量地估计出目标元素与其他元素之间具有多么强烈的相关性,并由注意力向量的加权和作为目标的近似值。
序列到序列(Seq2Seq)模型究竟有什么问题?
seq2seq模型最早是在2014年由Sutskever提出的,他主要针对的是语言模型。从广义上来讲,它的目的是将输入序列(源序列)转换成一个新的序列(目标序列),而且两个序列的长度可以是任意的。转换任务包括文本或者语音上的多语种机器翻译,问答对话的生成或者生成句子的语法树等任务。
seq2seq模型通常具有一种编码器-解码器(encoder-decoder)结构,由下面两部分构成:
Encoder:编码器处理输入序列,然后将其中包含的信息压缩成固定长度的上下文向量(context vector),上下文向量也可以叫做句子嵌入(sentence embedding)。这种表示方式可以用来对一整个句子的含义做出一个很好的总结。
Decoder:利用Encoder产生的上下文向量来初始化解码器以产生变换后的输出序列。早期的工作仅仅使用编码器网络的最后状态作为解码器的初始状态。
编码器和解码器都可以是递归神经网络,例如使用LSTM和GRU单元。
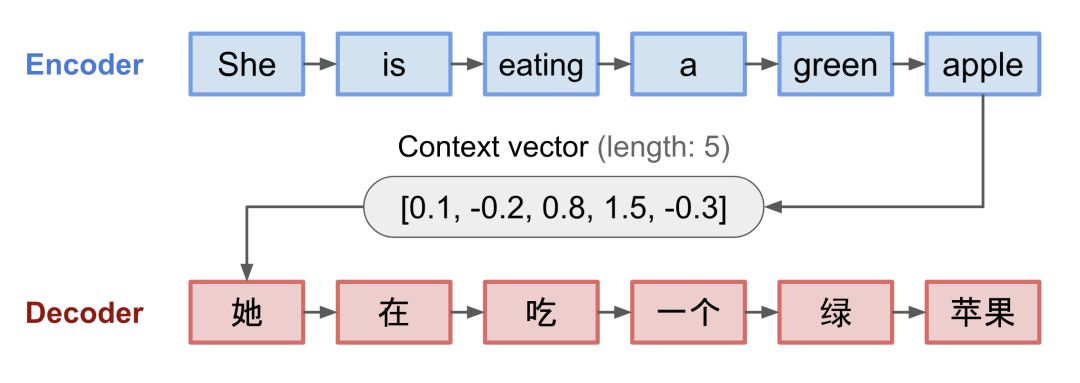
图3 encoder-decoder模型,用来将“she is eating a green apple”翻译成中文,图中是对编码器和解码器随着时间步而展开的可视化效果
这种固定长度的上下文向量设计的一个关键的和明显的缺点在于,它无法记住很长的句子,对很长的时序信息来说,一旦它完成了对整个序列的处理,它通常会忘记最开始的部分,从而丢失很多有用的信息。因此,在2015年Bahdanau等人为了解决长时依赖问题,提出了注意力机制。
为翻译而生
注意力机制的诞生,最开始是为了帮助神经机器翻译(NMT)记住较长的源句。注意力机制的秘方在于,它建立了一个上下文向量与整个源句之间的快捷方式,而不只是通过编码器最后一步的隐层状态来生成上下文向量。这些快捷方式的连接权重是根据每个输出元素自适应计算出来的。
既然上下文向量可以访问到整个句子中的每个单词,那我们根本不用担心之前的信息会被遗忘。源序列和目标序列之间的对齐(alignment)就通过这个上下文向量来学习和控制,从本质上讲,要计算上下文向量需要三个必要信息:
编码器的隐含层状态
解码器的隐含层状态
源和目标序列之间的对齐方式
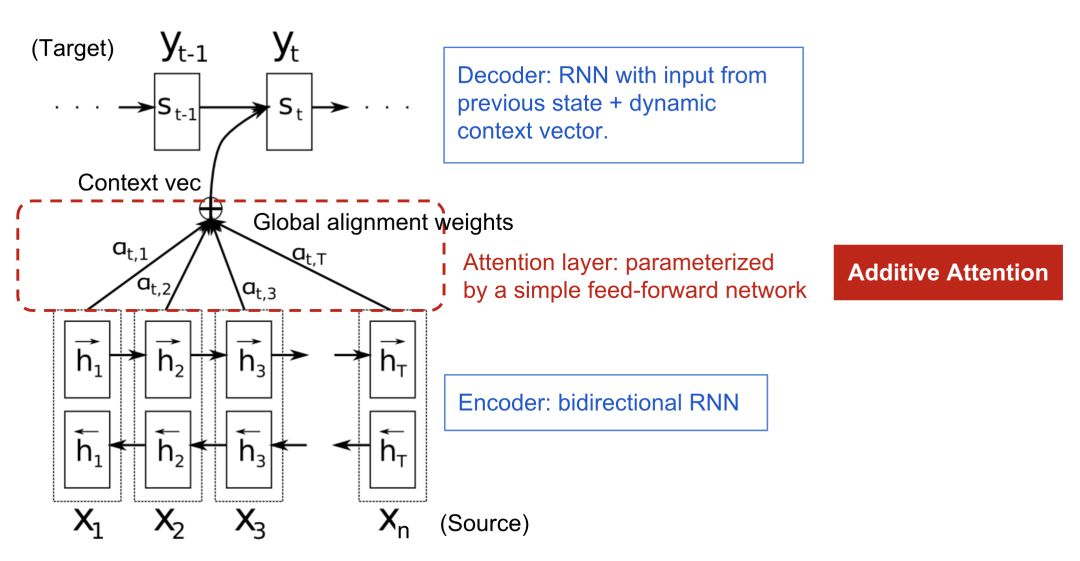
图4 加入注意力机制的encoder-decoder模型(Bahdanau等人,2015)
定义
现在让我们以科学的方式来定义神经机器翻译系统中引入的注意力机制。比方说,我们有一个长度为n的源序列x,并尝试输出长度为m的目标序列y:
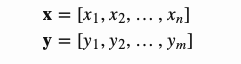
(加粗的变量代表他们是一个向量,本博客中所有情况相同)
这里的编码器是双向LSTM(或者其他你认为合适的递归神经网络),前向的隐含层状态定义为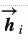 ,后向的隐含层状态定义为
,后向的隐含层状态定义为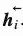 。将两种表示简单地串联起来构成编码器的整个隐含层状态表示。这种表示方法意在描述当前单词的时候包含有它之前和之后词的释义。
。将两种表示简单地串联起来构成编码器的整个隐含层状态表示。这种表示方法意在描述当前单词的时候包含有它之前和之后词的释义。
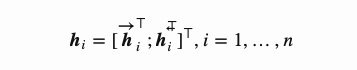
解码器网络对于第t时刻的输出单词的隐含层状态可以表示为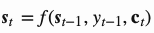 , 其中上下文向量
, 其中上下文向量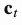 是输入序列的隐含层状态的加权和,权重由对齐函数计算得来:
是输入序列的隐含层状态的加权和,权重由对齐函数计算得来:

对齐函数得到的分数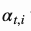 是根据第i个位置的输入和第t个位置的输出对
是根据第i个位置的输入和第t个位置的输出对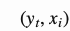 得来的,它衡量了二者的匹配程度。
得来的,它衡量了二者的匹配程度。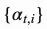 的集合衡量了输出关注到多少源序列的隐层状态。在Bahdanau的文章中,对齐分数
的集合衡量了输出关注到多少源序列的隐层状态。在Bahdanau的文章中,对齐分数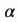 的参数由一个前馈神经网络参数化,其输入仅仅是输入序列和输出序列的隐含层状态,这个模型跟整体模型的其它部分一起参与训练,从而学到所谓的注意力权重。因此对齐分数函数的定义如下面所示,给定tanh作为非线性激活函数:
的参数由一个前馈神经网络参数化,其输入仅仅是输入序列和输出序列的隐含层状态,这个模型跟整体模型的其它部分一起参与训练,从而学到所谓的注意力权重。因此对齐分数函数的定义如下面所示,给定tanh作为非线性激活函数:
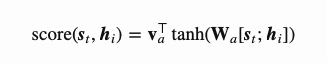
其中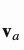 和
和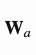 是可学习的参数,作为整体模型参数的一部分参与到训练的过程当中。
是可学习的参数,作为整体模型参数的一部分参与到训练的过程当中。
对齐分数矩阵是一个很好的副产品,它可以很好的显示出源单词和目标单词之间的相关性。

图5 对齐分数矩阵,表现了源句法语“L’accord sur l’Espace économique européen a été signé en août 1992”到目标语句英语“The agreement on the European Economic Area was signed in August 1992”翻译的单词之间相关性的结果。
点击下面链接可以获得具体的实施方法,这是Tensorflow团队提供的一份优秀的教程。
https://www.tensorflow.org/versions/master/tutorials/seq2seq
注意力机制模型家族
有了注意力机制,源序列和目标序列的依赖关系再也不需要二者之间的相对距离了!有了机器翻译领域上巨大的进展,注意力机制在包括计算机视觉(Xu et al.2015)在内的其它领域也都随之有了广泛的应用,研究者们也相继探索出各种不同的注意力机制模型以适用于不同的应用场合(Luong, et al., 2015; Britz et al., 2017; Vaswani, et al., 2017)。
归纳总结
下面的表格,我们总结了几种流行的注意力机制以及相应的对齐分数函数:

(*)在Luong等人的文章中被称为“concat”,在Vaswani等人的文章中被称为“附加注意”。
(^)它增加了一个比例因子`$1/sqrt{n}$`,因为当输入较大时,softmax函数的梯度可能非常小,难以进行有效的学习。
下面总结了一些更广义的应用到注意力机制的方法:

(&)此外,Cheng等人在2016等论文中也将其称为内注意力机制(intra-attention)。
自注意力机制(Self-attention)
自注意力机制,又称内注意力机制,是一种将单个序列的不同位置关联起来以计算同一序列的表示的注意机制。它在机器阅读、抽象摘要或图像描述生成中非常有用。
在“Long short-term memory network”这篇文章中使用自注意力机制去做机器阅读。在下面的例子中,自注意机制使我们能够学习当前单词和句子前一部分之间的相关性。
相关链接:https://arxiv.org/pdf/1601.06733.pdf

图6 当前单词为红色,蓝色阴影的大小表示激活级别也就是相关性的大小。(图片来自于Cheng et al.,2016)
在“Show,attend and tell”这篇文章中,自注意力机制应用于图像以生成适当的描述。图像首先由卷积神经网络进行编码,具有自注意力机制的递归神经网络利用卷积特征映射逐条生成描述性词语。注意力权重的可视化清晰地展示了模型为了输出某个单词而关注图像的某些区域。
相关链接:http://proceedings.mlr.press/v37/xuc15.pdf
图7 机器根据图像得到的描述“一个女人正在一个公园里扔飞碟”。(图像来自于Xu et al. 2015)
Soft & Hard Attention
soft vs hard 注意力记住是区分注意力定义的另一种方式。最初的想法是在“Show, attend and tell paper”论文中提出的,其主要思想在于:注意力是否可以访问整个图像或只访问图像中的一部分:
Soft Attention:所学习的对齐权重关注于整个输入图像中的各个部分,关键思想和Bahdanau在2015年的论文如出一辙。
优点:模型是平滑可微的
缺点:当输入序列非常长的时候,计算量会很大
Hard Attention:每一步只关注到图像中的一部分
优点: 预测阶段具有很小的运算量
缺点:模型是不可导的而且需要更加复杂的训练技术,例如强化学习和方差降低(variance reduction)
Global & Local Attention
“Luong, et al.,2015” 首次提出了“global”和“local”注意力机制。global注意力机制和soft注意力机制类似,然而local是hard和soft的有趣的融合,它是对hard attention的一种改进,使得它变得可导:该模型首先预测一个当前目标词对齐的位置和一个围绕源位置的窗口,然后用于计算上下文向量。
相关链接:https://arxiv.org/pdf/1508.04025.pdf
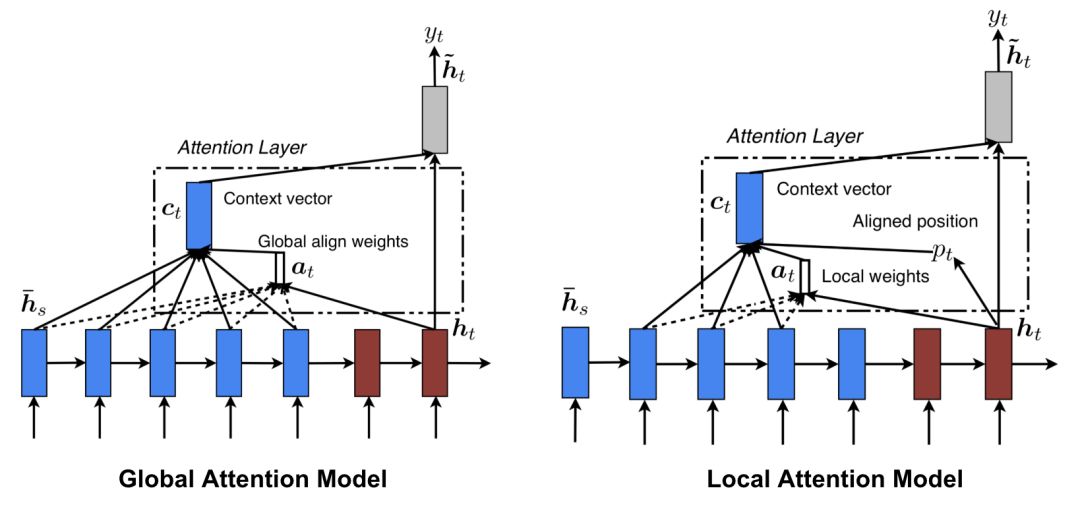
图8 全局和局部注意力机制(图片来自于Luong,et al.,2015中图2和图3)
神经图灵机
1936年,阿兰·图灵提出了一个计算机的最小模型。它由一个无限长的磁带和一个与磁带交互的磁头组成。磁带上有无数的单元格,每个单元格都填有一个符号:0,1或空格(“ ”)。操作头可以读取符号、编辑符号,并可以在磁带上左右移动。理论上,图灵机可以模拟任何计算机算法,不管这个过程有多复杂或多耗时。无限内存给图灵机带来了数学上无限的优势。然而,无限内存在真正的现代计算机中是不可行的。
图9 图灵机的样子:一个磁带+一个处理磁带的磁头。(图片来源:http: aturingmachine.com)
神经图灵机(NTM,Graves, Wayne & Danihelka, 2014)是一种神经网络与外部存储器耦合的模型结构。存储器模仿图灵机磁带,神经网络控制操作头从磁带读取或者向磁带中写。然而,NTM中的内存是有限的,因此它看起来更像是一台“神经冯诺伊曼机器”。
NTM包含两个主要部件:一个由神经网络构成的控制器和存储器。控制器:负责对内存执行操作。它可以是任何类型的神经网络(前馈神经网络或递归神经网络)。存储器:保存处理过的信息。它是一个大小为`$N imes M$`的矩阵,其中包含N行向量,每个向量都有M个维度。
在一次更新迭代的过程中,控制器处理输入信号并相应地与存储器进行交互以生成输出。交互由一组并行读写头处理。读和写操作都是模糊的,因为它们都需要访问所有内存地址。
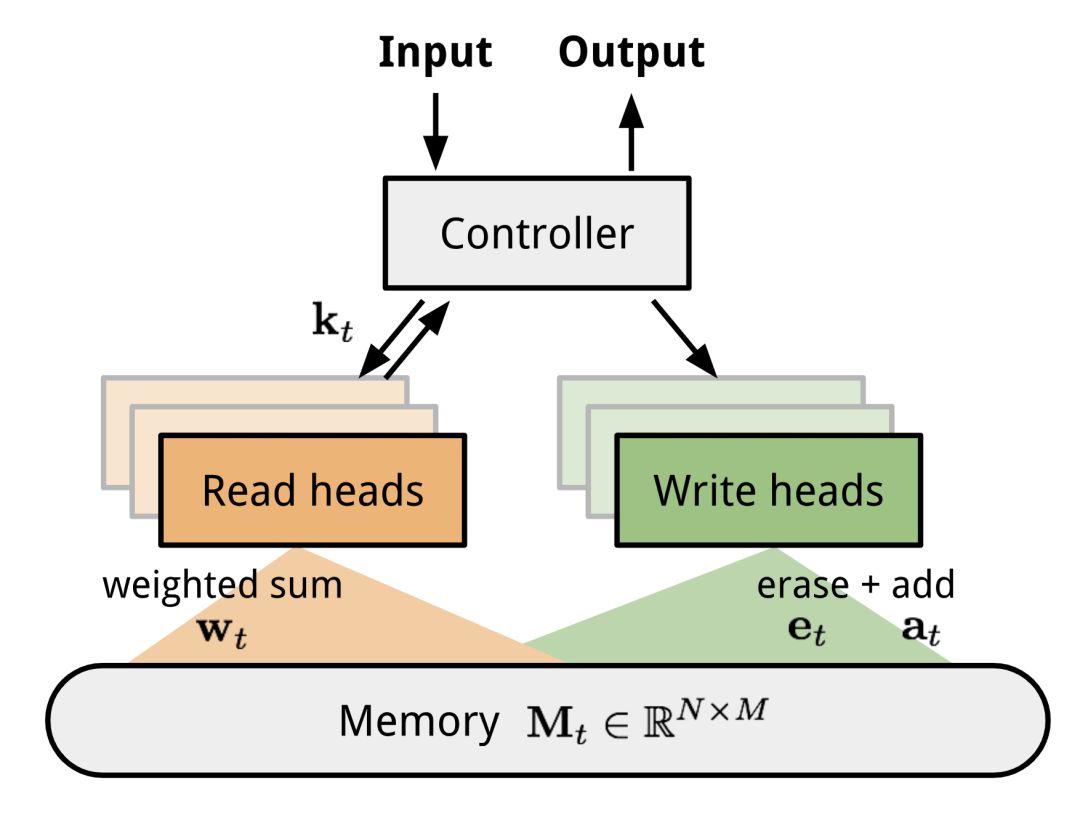
图10 神经图灵机的结构
读写机制
当在时刻t(注意力向量大小为N)从内存中读取数据时,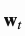 控制分配给不同内存位置(矩阵行)的注意量。读取向量
控制分配给不同内存位置(矩阵行)的注意量。读取向量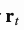 是记忆内存的加权和,权重根据注意力强度来衡量。
是记忆内存的加权和,权重根据注意力强度来衡量。
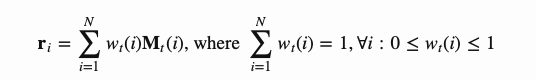
其中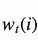 代表向量
代表向量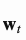 的第i个元素,
的第i个元素,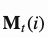 是存储矩阵的第i行向量。
是存储矩阵的第i行向量。
在t时刻写入内存时,受LSTM中输入和遗忘门的启发,写入磁头首先根据一个擦除向量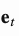 擦除一些旧的内容,然后通过一个加法向量
擦除一些旧的内容,然后通过一个加法向量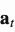 添加新的信息到存储器中。
添加新的信息到存储器中。
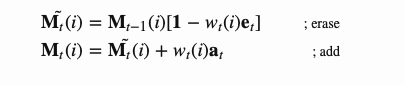
注意力机制
在神经图灵机中,如何产生注意力分布wt取决于寻址机制:神经图灵机使用基于内容和基于位置的寻址的混合寻址方式。
基于内容的寻址方式
基于内容的寻址方式,就是根据控制器从输入行和内存行提取的关键向量kt之间的相似性来创建注意向量。基于内容的注意力机制用余弦相似度来计算相似性,然后用softmax函数进行归一化。此外,神经图灵机增加了放大器βt用来放大或衰减分布的重点。
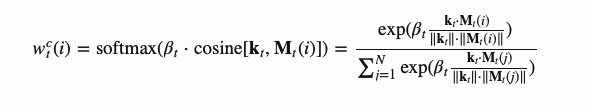
插值
然后利用插值门,也就是一个标量gt将新生成的基于内容的注意向量与上一步的注意权值进行混合:
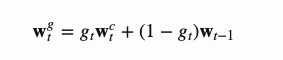
基于位置的寻址方式
基于位置的寻址将注意向量中不同位置的值相加,并通过允许的整数移位上的加权分布进行加权。它等价于与核函数st(.)的一维卷积,st(.)是位置偏移的函数。定义这个分布有多种方法。参见图11以获得启发。
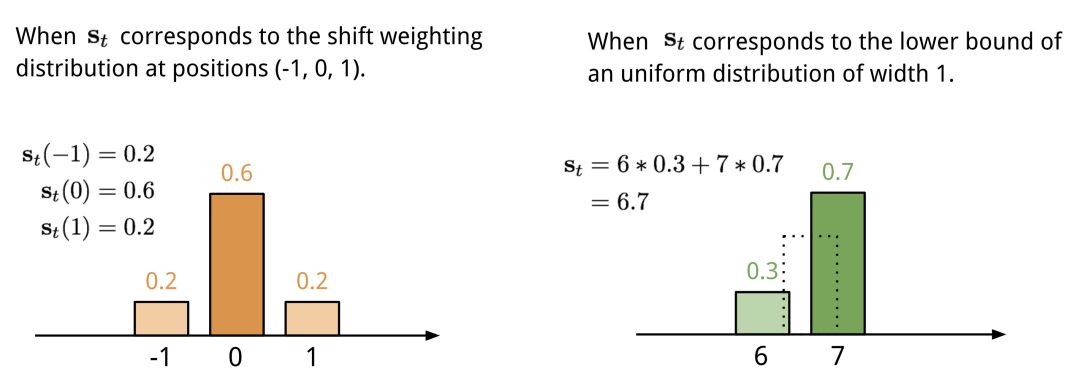
图11 两种表示位移权重分布st的方式
最后注意分布由标量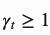 进行锐化增强。
进行锐化增强。
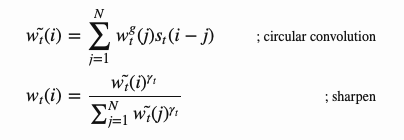
注意向量wt在时间步长t上生成的完整过程如图12所示。控制器产生的每个磁头的所有参数都是唯一的。如果有多个读写头并行,控制器将输出多个集合。
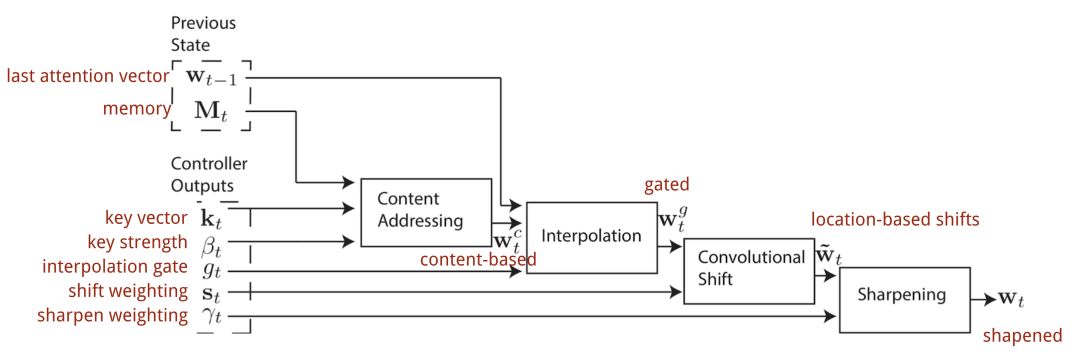
图12 神经图灵机寻址机构流程图
指针网络(Pointer Network)
在排序或旅行推销员(travelling salesman)等问题中,输入和输出都是顺序的数据。不幸的是,传统的seq-2-seq或NMT模型都不能很容易地解决这些问题,因为输出元素的离散类别不是预先确定的,而是取决于可变的输入大小。指针网络(Ptr-Net;(Vinyals, et al. 2015)的提出就是为了解决这类问题:当输出元素对应于输入序列中的位置时。指针网络没有使用注意力机制将编码器的隐藏单元混合到上下文向量中(参见图8),而是使用注意力机制直接作用在编码器上,选择输入序列中某个元素作为解码器的输出。
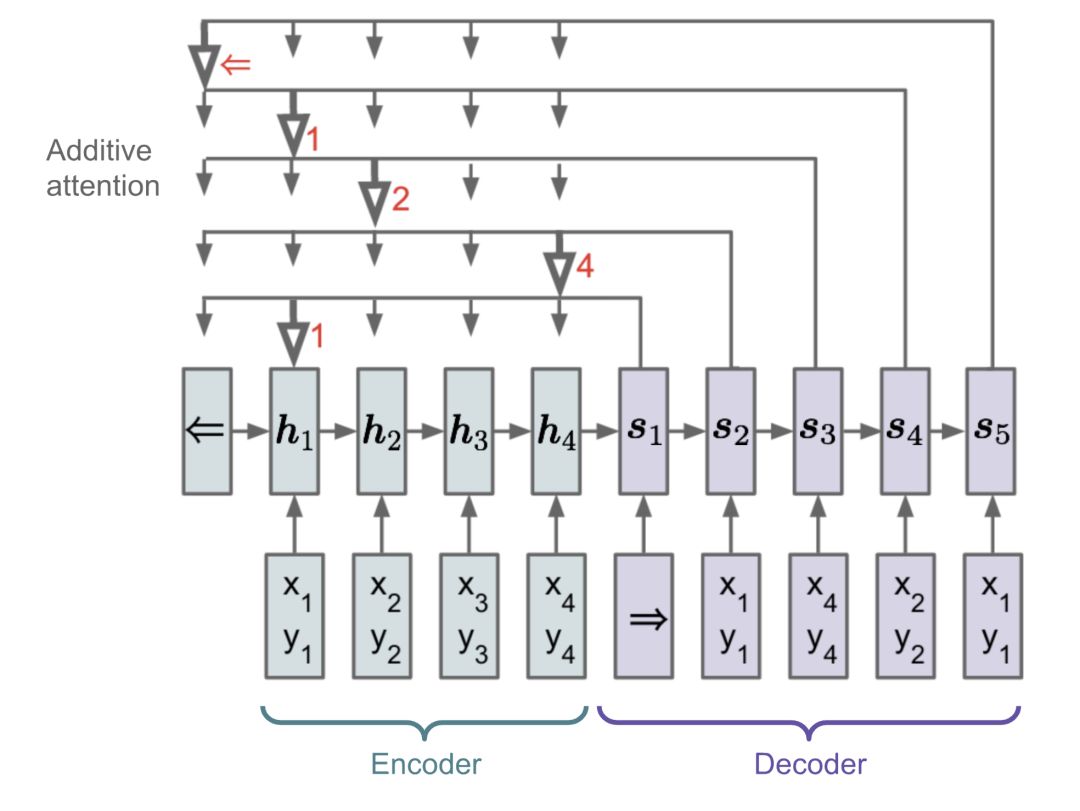
图13 指针网络模型的结构图(图片来自于https://lilianweng.github.io/lil-log/assets/images/ptr-net.png)
当给定输入序列为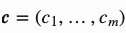 ,指针网络的输出是一个由整数索引构成的序列
,指针网络的输出是一个由整数索引构成的序列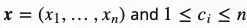 。指针网络依然是以编码器-解码器的结构作为基础。其中编码器和解码器的隐含层状态分别表示为
。指针网络依然是以编码器-解码器的结构作为基础。其中编码器和解码器的隐含层状态分别表示为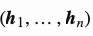 和
和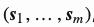 。指针网络使用addictive attention作为对分数齐函数,然后同样使用softmax进行归一化从而建立输出条件概率模型:
。指针网络使用addictive attention作为对分数齐函数,然后同样使用softmax进行归一化从而建立输出条件概率模型:
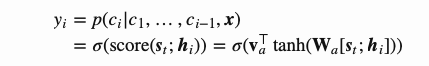
可以看到,在指针网络中注意机制被简化了,因为它没有将编码器状态与注意权重混合到输出中。这样,输出只响应位置,而不响应输入内容。
Transformer
“Attention is All you Need”这篇文章(Vaswani, et al., 2017),无疑是2017年最有影响力和最有趣的论文之一。它对soft attention进行了大量的改进,使得在不需要递归神经网络单元(LSTM,GRU)的情况下进行seq2seq建模成为了可能。它提出的 Transformer 模型完全建立在自注意力机制(self-attention)的基础上,没有使用任何序列对齐的递归结构。
其模型结构如下:
Key, Value and Query
Transformer的主要部件是一个叫做“多头自注意力机制”的单元(multi-head self-attention mechanism)。Transformer将输入的编码表示形式视为一组键key-值value对(K,V),它们的维度都是n(输入序列长度);在NMT的上下文中,key和value都是编码器的隐含层状态。在解码器中,上一步的输出被压缩为一个查询query(Q的维度为m),下一步的输出是通过映射这个查询query到一组键key和值value的集合生成的。Attention 函数的本质可以被描述为一个查询到一系列键-值对的映射。
Transformer选择缩放点积(scaled dot-product attention)作为注意力机制:输出为各个值key的加权和,其中每个值value的权重定义为查询query作用于所有键key的缩放点积:
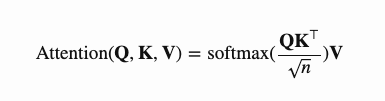
多头自注意力机制(Multi-Head Self-Attention)
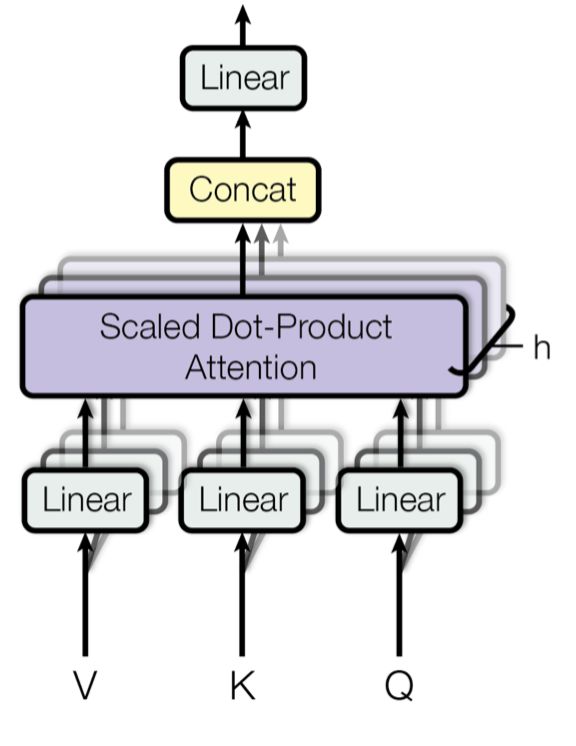
图14 多头缩放点积注意力机制的结构图
多头注意力机制会并行计算缩放点积很多次,而不是仅仅计算一次。然后将相互独立的注意力计算单元的输出简单的拼接在一起,最后通过一个线性单元转换成期望大小的维度。我认为这样做的动机是因为合并总是有效的?根据作者在文章中的描述,“多头注意力机制允许模型共同关注来自不同位置的不同子空间的信息。而仅仅有一个注意力机制,是不能得到这么丰富的信息的。”

其中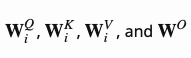 为可学习的参数。
为可学习的参数。
编码器(Encoder)
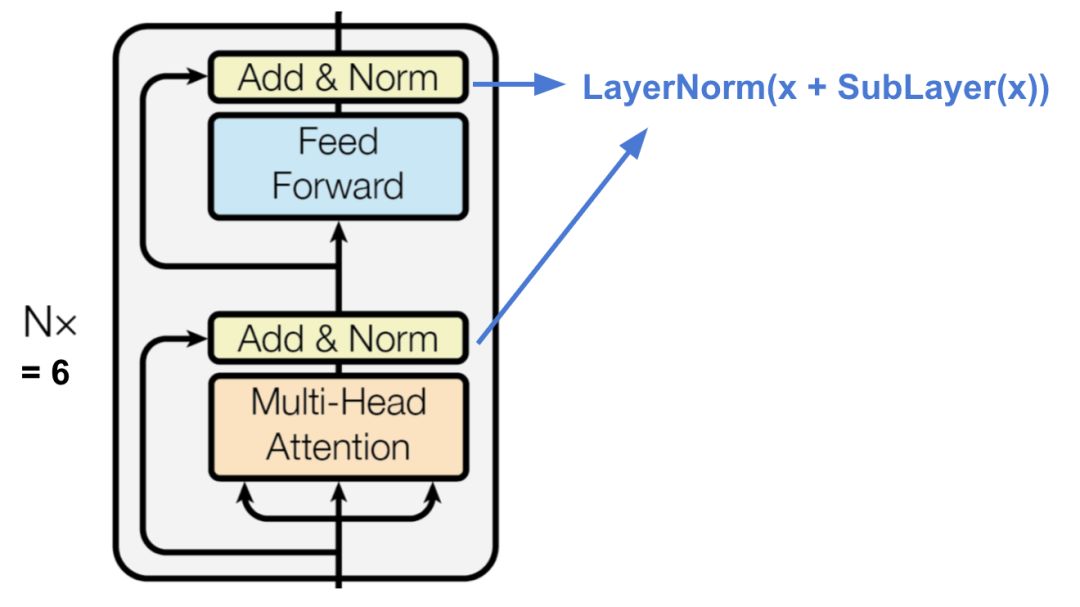
图15 Transformer的编码器结构
编码器可以生成基于注意力的表示,其能够从可能无限大的上下文中定位到特定的信息。
6个相同的层堆叠在一起
每个编码层都有一个多头自注意力机制层和一个全连接前馈神经网络单元
每个编码子层之间都采用残差连接方式,并且使用层归一化(layer normalization)。
每个子层的输出数据都是相同的维度`$d_ ext{model} = 512$`
解码器(Decoder)
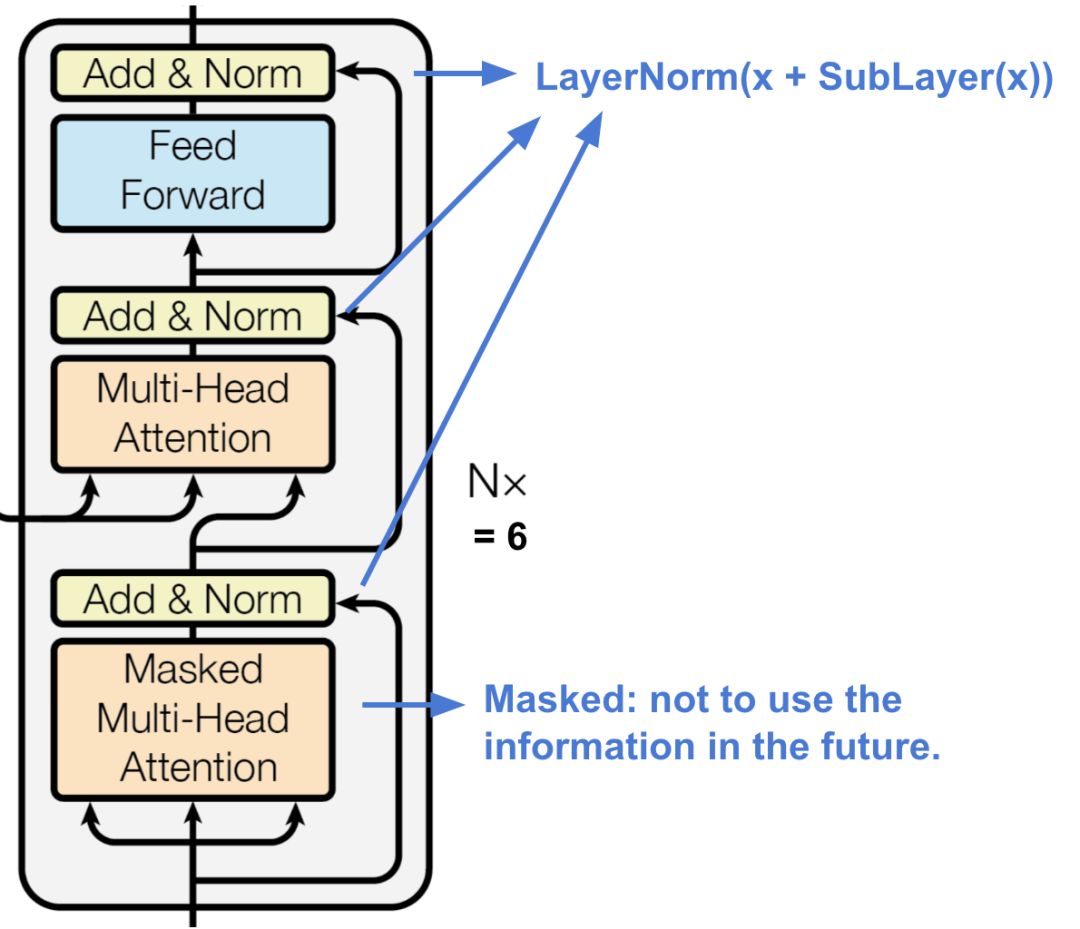
图16 Transformer的解码器结构
解码器能够对已编码的表示进行检索。
6个相同的层堆叠在一起
每个解码层含有两个子层结构,一个是多头注意力机制,另一个是全连接前馈神经网络单元
与编码器结构类似,每个解码器子层之间都采用残差连接方式,并且使用层归一化(layer normalization)。
第一个多头注意子层被修改,以防止当前位置参与到后面的子序列的位置中,因为我们不想在预测当前的位置时有目标序列的未来信息对其进行干扰。
完整的结构
有了前面对编码器和解码器结构的介绍,下面将引出Transformer的整体结构:
源序列和目标序列都先要经过一个embedding层,将其嵌入到相同的维度,例如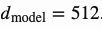 。
。
为了保存序列的位置信息,使用基于正弦函数的位置编码器对每个输入向量进行编码,将编码向量合并在嵌入向量之后。
softmax函数和线性层加入到最后解码器的输出上。
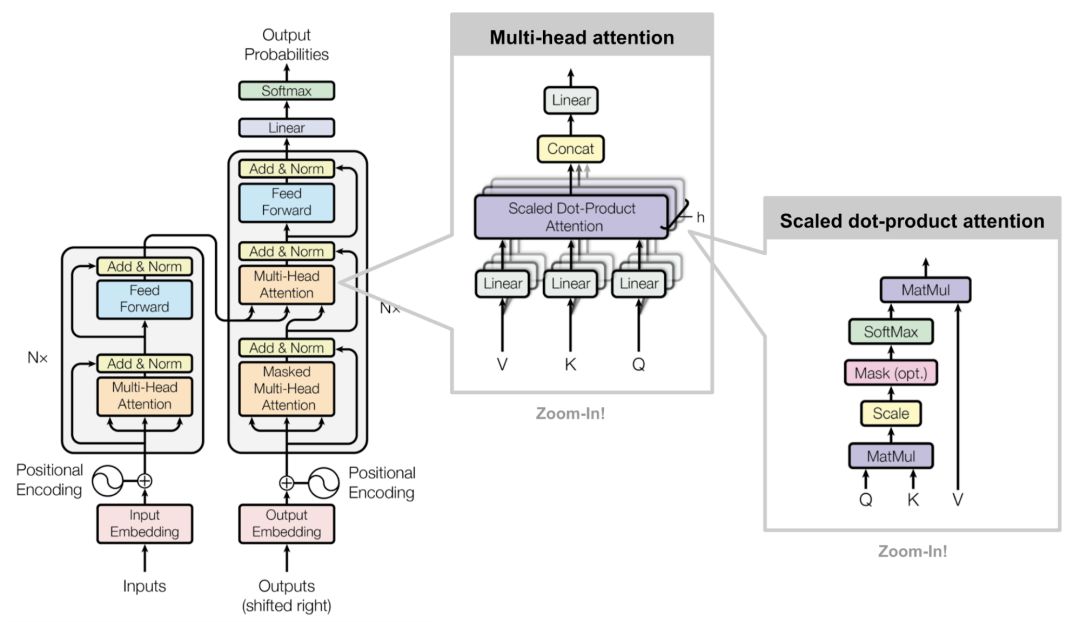
图17 Transformer的整体结构
注:作者实现的一个Transformer模型:lilianweng/transformer-tensorflow
SNAIL
Transformer模型没有递归结构或者卷积结构,即便加入位置编码单元对嵌入向量的位置进行编码,对序列的顺序表示也很弱。对于像强化学习这种对位置依赖性十分敏感的问题,这可能是一个大问题。
简单神经注意力元学习(Simple Neural Attention Meta-Learner)简称SNAIL,通过将Transformer的自注意力机制与时序卷积相结合,部分解决了模型中位置编码的问题。它已被证明擅长解决监督学习和强化学习任务。
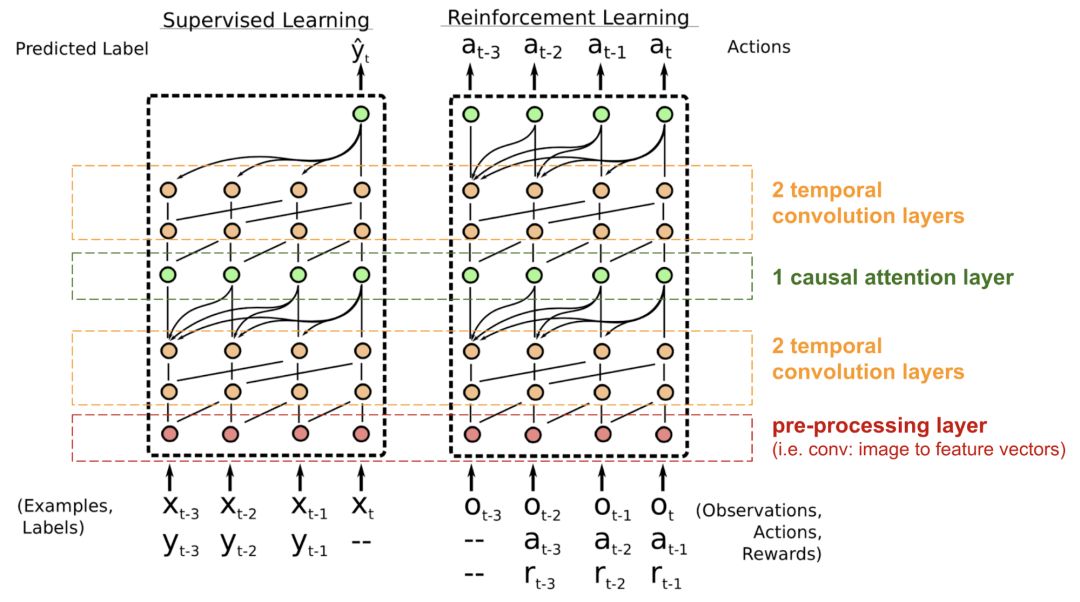
图18 SNAIL模型的结构图
SNAIL的产生归功于元学习,这是另一个值得写一篇文章来归纳的大话题。但简单来说,元学习用来预测那些新颖的但未被观察到的、具有跟已知样本有相同分布的样本数据。
自注意力生成对抗网路(Self-Attention GAN)
最后,我想提到一个最新发布的生成对抗网络模型,自注意力生成对抗网路,我们来看看注意力机制是如何应用到生成对抗网络上以提高生成图像的质量的。
经典的DGGAN(深度卷积生成对抗网络)将生成器和判别器都表示成多层卷积神经网络。然而,表示的能力受到滤波器大小的限制,因为一个像素的特征受限于一块小的局部区域。为了连接相隔很远的区域,必须通过卷积操作来稀释这些特征,尽管如此,他们之间的依赖性也未必能得到很好的保证。
在计算机视觉中,由于上下文向量可以通过soft-attention明确地学习到一个像素与其他位置所有像素之间的关系,即便是相距甚远的区域,它也可以轻松捕获全局的依赖关系。因此,如果将self-attention与GAN相结合,有望处理更多细节信息。
图19 卷积操作和自注意力机制访问到的区域大有不同
SAGAN采用非局部神经网络(non-local neural network)的注意力方法来计算。卷积图像的特征图构成三个分支,分别对应于Transformer模型中的键、值和查询三个概念。
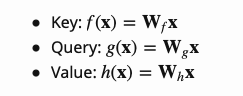
然后我们使用点积(dot-product)注意力机制来得到自注意特征图:
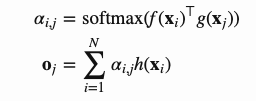
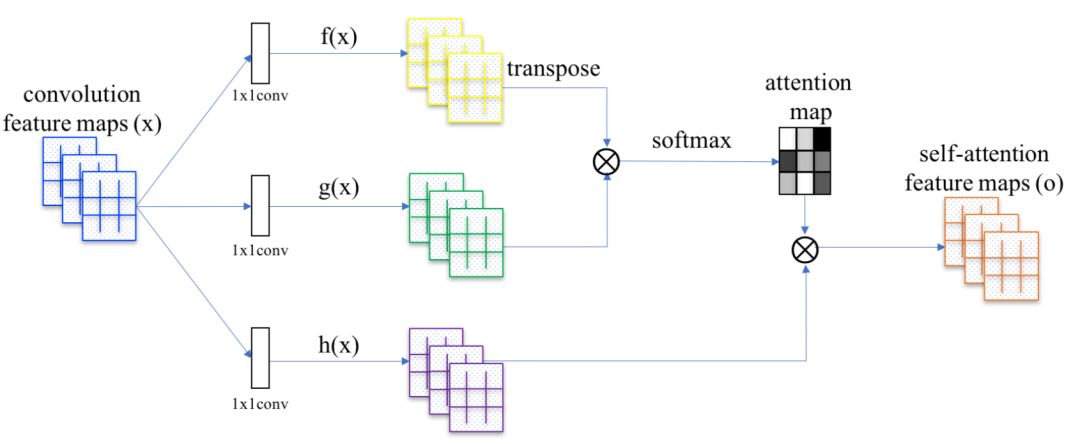
图20 SAGAN中的自注意力机制
注意到,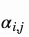 是注意力图(attention map)中的一个元素,它表示模型在生成第j个位置时对第i个位置应该注意多少程度。
是注意力图(attention map)中的一个元素,它表示模型在生成第j个位置时对第i个位置应该注意多少程度。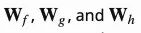 都是1x1的卷积核。
都是1x1的卷积核。
如果你不太明白1x1的卷积是什么意思,请参看Andrew Ng的一个简短的教程
(链接:https://www.youtube.com/watch?v=9EZVpLTPGz8)。
列向量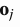 是最终的输出结果,
是最终的输出结果,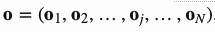 。
。
之后,输出的注意层(attention layer)乘以一个比例系数,再放回到原始的特征图中,这类似于残差连接方式:
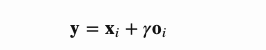
尽管缩放系数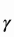 在训练期间从0逐渐增加,但是网络被配置为一开始依赖局部区域中的信息,然后通过分配更多权重给更远区域逐渐学习到更远区域的信息。
在训练期间从0逐渐增加,但是网络被配置为一开始依赖局部区域中的信息,然后通过分配更多权重给更远区域逐渐学习到更远区域的信息。
图21 SAGAN生成的大小为128×128的不同类别的示例图像
-
计算机视觉
+关注
关注
8文章
1703浏览量
46317 -
深度学习
+关注
关注
73文章
5530浏览量
122026 -
自然语言处理
+关注
关注
1文章
624浏览量
13780
原文标题:Deep Reading | 从0到1再读注意力机制,此文必收藏!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
注意力机制或将是未来机器学习的核心要素
基于注意力机制的深度兴趣网络点击率模型

基于注意力机制的深度学习模型AT-DPCNN

基于层次注意力机制的多模态围堵情感识别模型

基于多层CNN和注意力机制的文本摘要模型

联合评论文本层级注意力和外积的推荐方法

基于循环卷积注意力模型的文本情感分类方法






 工商网监
工商网监
评论