 什么是Transition-based基于转移的框架?
什么是Transition-based基于转移的框架?
什么是依存句法树
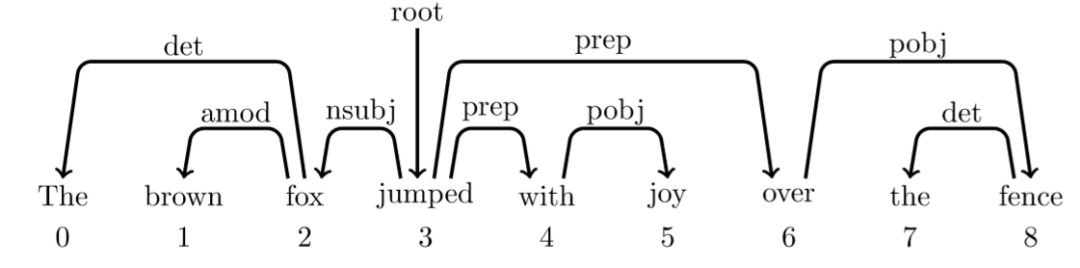
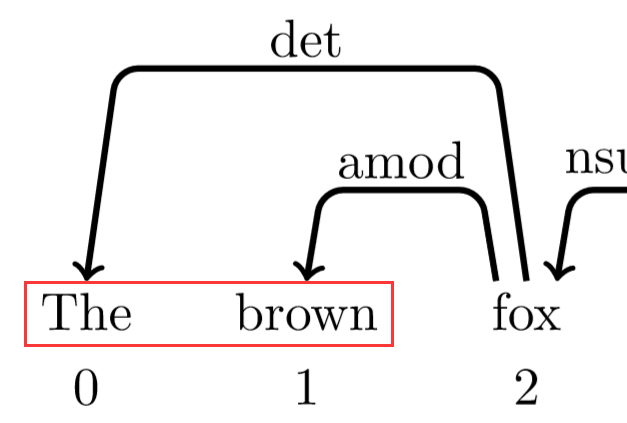
依存句法树就是表示一个句子中词与词之间的依存关系,如下图
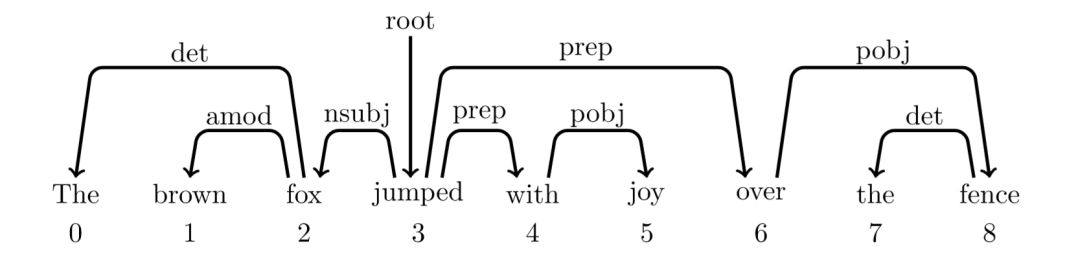
其中两个词之前的弧表示这两个词有依存关系,弧上的标签为二者的关系,弧的始发点为父亲节点,箭头指向为孩子节点。比如The 和 fox 是冠词+名词(det)的名词短语。
除了一个词,即根节点(这里为jumped)外,其他词都有词作为父亲节点,而该根节点(jumped)的父亲节点为root。
但是注意,依存句法树是不允许弧之间有交叉或者回路!
依存句法树数据表示
依存句法树的文本表示格式为conll格式,如表
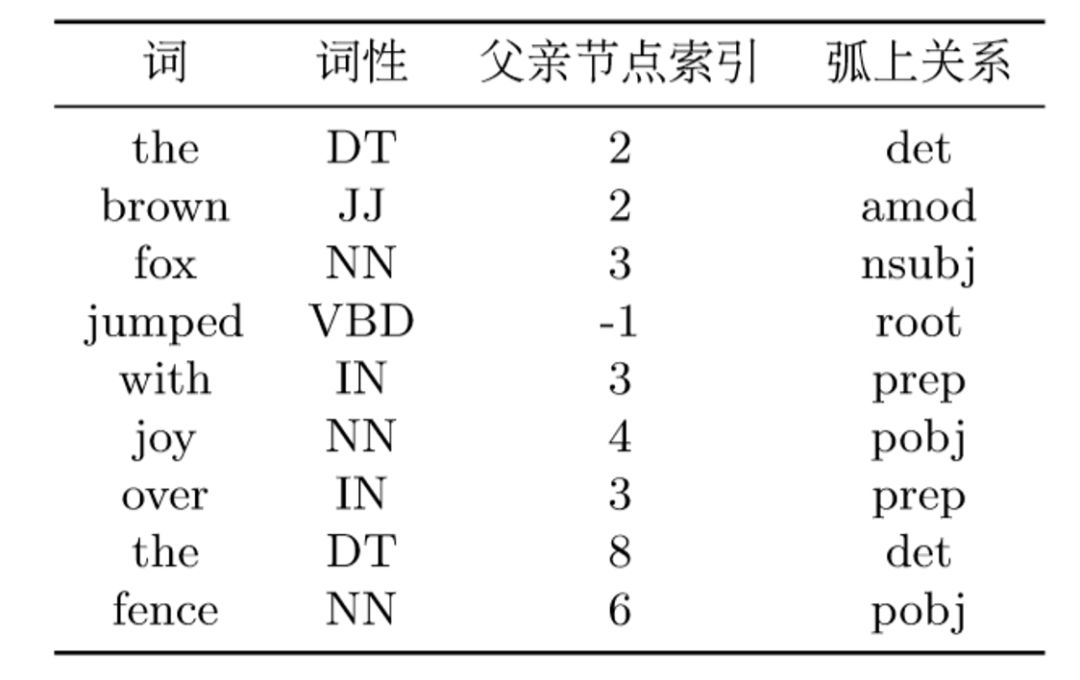
根据该表的父亲节点索引和对应的弧上关系就能还原该依存句法树。其中-1表示根节点。
依存句法树的用途
我们通常将依存句法的特征融入到其他任务模型里,比如机器翻译、意见挖掘、语篇分析等,一般能得到更好的性能。
那怎么得到依存句法特征呢?通常有两种方法:
将依存句法树喂给递归神经网络,得到的隐层表示可以作为该依存句法的特征表示。
将依存句法树交给特征模板,从而得到该依存句法的特征表示。
什么是Transition-based基于转移的框架?
这个框架由状态和动作两部分构成,其中状态用来记录不完整的预测结果,动作则用来控制状态之间的转移。
用在生成依存句法树上,则具体表示为从空状态开始,通过动作转移到下一个状态,一步一步生成依存句法树,最后的状态保存了一个完整的依存树。依存分析就是用来预测词与词之间的关系,现在转为预测动作序列。在基于转移的框架中,我们定义了4种动作(栈顶的元素越小表示离栈顶越近):
移进(shift):队列首元素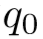 出栈,压入栈成为
出栈,压入栈成为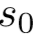 。
。
左规约(arc_left_l):栈顶2个元素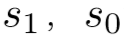 规约,
规约,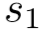 下沉成为
下沉成为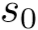 的左孩子节点,l为弧上关系。
的左孩子节点,l为弧上关系。
右规约(arc_right_l):栈顶2个元素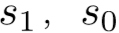 规约,
规约,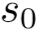 下沉成为
下沉成为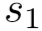 的右孩子节点,l为弧上关系。
的右孩子节点,l为弧上关系。
根出栈(pop_root):根节点出栈,分析完毕。
ps:下沉的意思
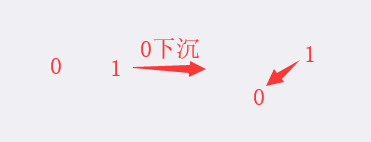
0下沉,视觉效果能看出是1的孩子
所以,我们基于转移的依存句法分析器就由预测树结构问题转为预测动作序列问题。使得问题简单了不少。
Transition-based基于转移的具体例子
还是以上面的依存树为例:
一整套依存分析的动作序列(金标,训练数据)就变为:
详细解释下:
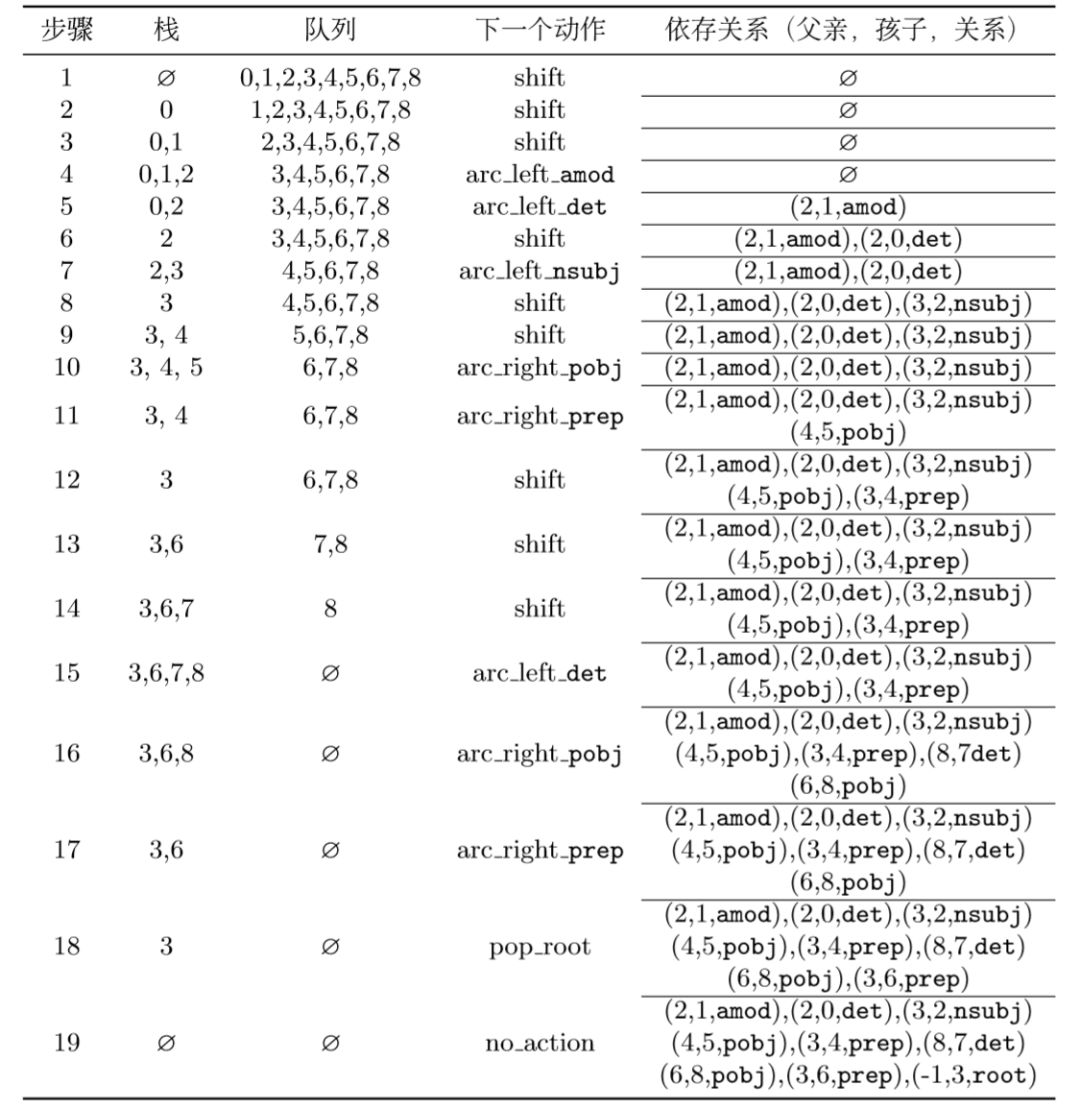
初始状态

栈为空,队列为整个文本的数字序列。这个时候只能进行移进shift操作:
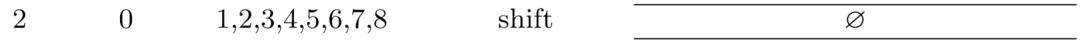
因为左边栈对一个元素0,还是只能进行移进shift操作:
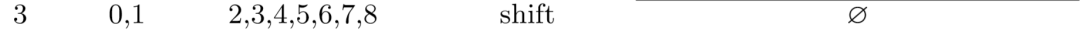
这个时候栈中有2个元素,我们此时看依存树
0、1之间并没有弧,不能进行规约,所以还是只能shift:
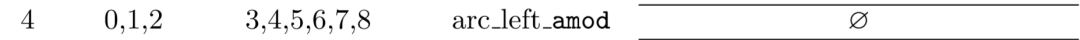
此时看栈顶两元素,发现依存树中1、2之间有依存关系
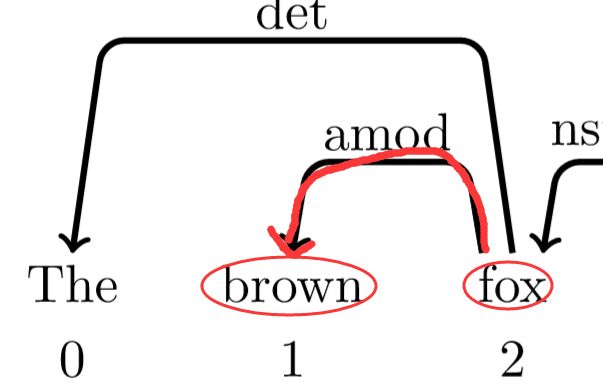
而且1为2的孩子,所以此时的动作为左规约arc_left,1下沉,为2的孩子(此时实际操作为1被踢出栈,栈里剩为0、2,踢出是因为最后能根据动作序列还原整个依存树,当然也为了接下来的操作方便),此时标签为amod:
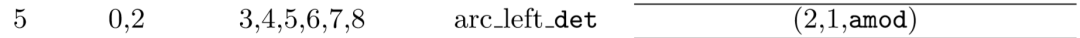
此时栈里为0、2,再次查看依存树
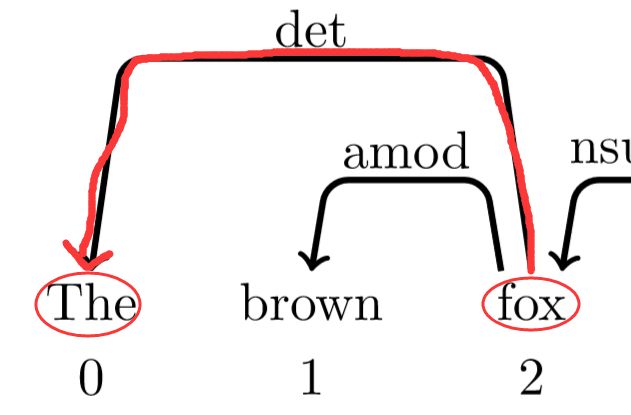
发现0、2之间有依存关系,其中0为2的孩子,所以此时操作为左规约,此时标签为det
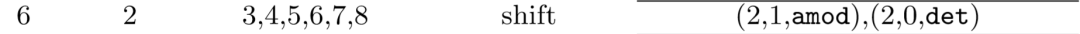
...
中间略过一些步骤,因为都是同理,这次说下第9步:
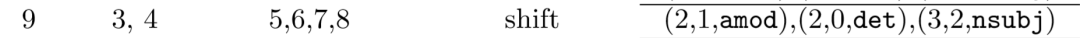
此时栈中为3、4,查看依存树
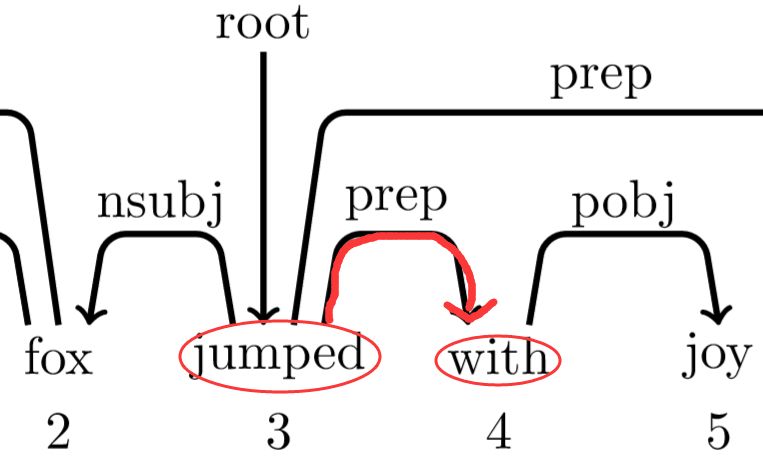
按照正常操作,此时应该arc_right右规约,但是如果真的4就下沉,就没了。而一会5要入栈,再查看依存树发现4是自己的爸爸,天呐,5的爸爸没了,找不到了,消失了,其他词都有爸爸,就5没有,还有比这个更惨的吗?这就没发再进行操作了!所以,还有一个潜规则如果操作为栈顶元素要进行arc_right时,不执行该操作,而选择shift。
而你可能会问arc_left会有这样的问题吗?不会啦,比如3、4进行arc_left操作,3下沉,如果右边的队列中有父亲节点是3,那么就表示该依存树有交叉或者回路!这种是不可能发生的,因为依存树不允许有交叉或者回路!(不信的话,你自己画画试试)
最后说下,pop_root根弹出操作,只能发生在最后

右下角的数据为词与词之间的关系,这个就是根据动作序列生成的依存关系(父亲,孩子,关系),根据该关系,就能还原成原来的依存树。
神经网络模型
我们用神经网络来进行特征抽取,该网络共分为2部分:
编码端:用来负责计算词的隐层向量表示
解码端:用来解码计算当前状态的所有动作得分
编码端
我们用Bi-LSTM来编码一个句子
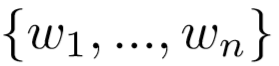
,计算对应的隐层表示
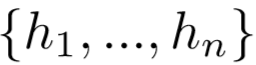
。公式表示为:
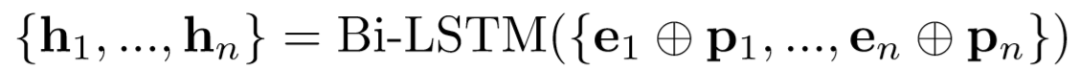
其中,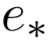 为词向量,
为词向量,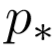 为词性向量,
为词性向量, 为向量拼接。
为向量拼接。
具体解释:
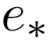 就是咱们平时用的词的embedding
就是咱们平时用的词的embedding
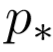 就是词性,比如是NN,VV,VP等。将它当成词的操作一样,用它自己的embedding(和词的embedding不是一个!)表示。
就是词性,比如是NN,VV,VP等。将它当成词的操作一样,用它自己的embedding(和词的embedding不是一个!)表示。
 就是向量拼接,咋拼接都行,cat呀,add呀都行的。自己尝试哪个效果好用哪个,没有死规定。而我们这里用的是cat。
就是向量拼接,咋拼接都行,cat呀,add呀都行的。自己尝试哪个效果好用哪个,没有死规定。而我们这里用的是cat。
解码端
解码端就需要对每一个状态打出所有动作的得分。根据经验,认为栈顶三元素和队列首元素为动作预测关键特征,于是将栈顶三元素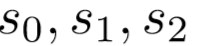 (下标越小离栈顶越近)和队列首元素
(下标越小离栈顶越近)和队列首元素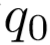 进行拼接。然后用线性变换计算每一个动作的分数:
进行拼接。然后用线性变换计算每一个动作的分数:

模型预测
对每一个动作的分数进行Softmax概率化,然后输入到交叉熵中,作为目标函数。然后再用Adam来进行更新模型参数,最小化目标函数:
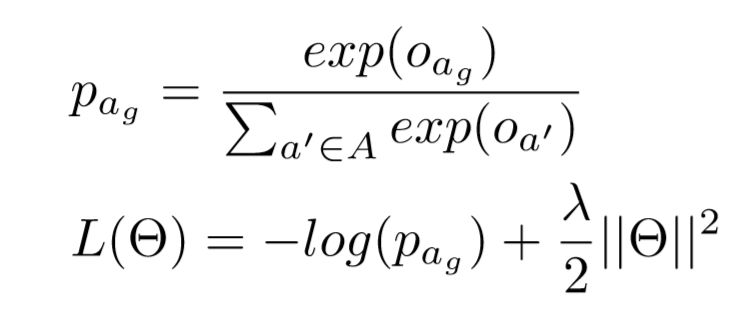
其中 为金标动作序列的概率,
为金标动作序列的概率, 为模型参数。
为模型参数。
-
神经网络
+关注
关注
42文章
4762浏览量
100535 -
框架
+关注
关注
0文章
398浏览量
17432 -
机器翻译
+关注
关注
0文章
139浏览量
14872
原文标题:详解Transition-based Dependency parser基于转移的依存句法解析器
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Slew time和Transition time是否一样?
关于EBD和NBD
HOOFR-SLAM的系统框架及其特征提取
Gowin RAM Based Shift Register IP参考设计
ECC Based Threshold Decryption
Frequency Inverter Based Drawi
Transition Mode PFC Controller
以PC Based Controller设计Modbus通信
Architecture of a DSP Based Du
Model Based Design with VisSim EMBEDDED
RFID标签所有权转移协议
如何来手动修复max transition和max capacitance

Gowin RAM Based Shift Register参考设计






 工商网监
工商网监
评论