 谷歌大脑打造“以一当十”的GAN:仅用10%标记数据,生成图像却更逼真
谷歌大脑打造“以一当十”的GAN:仅用10%标记数据,生成图像却更逼真
近日,谷歌大脑研究人员提出了一种基于自监督和半监督学习的“条件GAN”,使用的标记数据量大降90%,生成图像的质量比现有全监督最优模型BigGAN高出20%(以FID得分计),有望缓解图像生成和识别领域标记数据量严重不足的问题。
生成对抗网络(GAN)是一类强大的深度生成模型。GAN背后的主要思想是训练两个神经网络:生成器负责学习如何合成数据,而判别器负责学习如何区分真实数据与生成器合成的虚假数据。目前,GAN已成功用于高保真自然图像合成,改善学习图像压缩质量,以及数据增强等任务。
对于自然图像合成任务来说,现有的最优结果是通过条件GAN实现的。与无条件GAN不同,条件GAN在训练期间要使用标签(比如汽车,狗等)。虽然数据标记让图像合成任务变得更容易实现,在性能上获得了显著提升,但是这种方法需要大量标记数据,而在实际任务中很少有大量标记数据可用。
随着ImageNet上训练过程的持续,生成的图像逼真度进步明显
谷歌大脑的研究人员在最近的《用更少的数据标签生成高保真图像》中,提出了一种新方法来减少训练最先进条件GAN所需的标记数据量。文章提出结合大规模GAN的最新进展,将高保真自然图像合成技术与最先进技术相结合,使数据标记数量减少到原来的10%。
在此基础上,研究人员还发布了Compare GAN库的重大更新,其中包含了训练和评估现代GAN所需的所有组件。
利用半监督和自监督方式提升预测性能
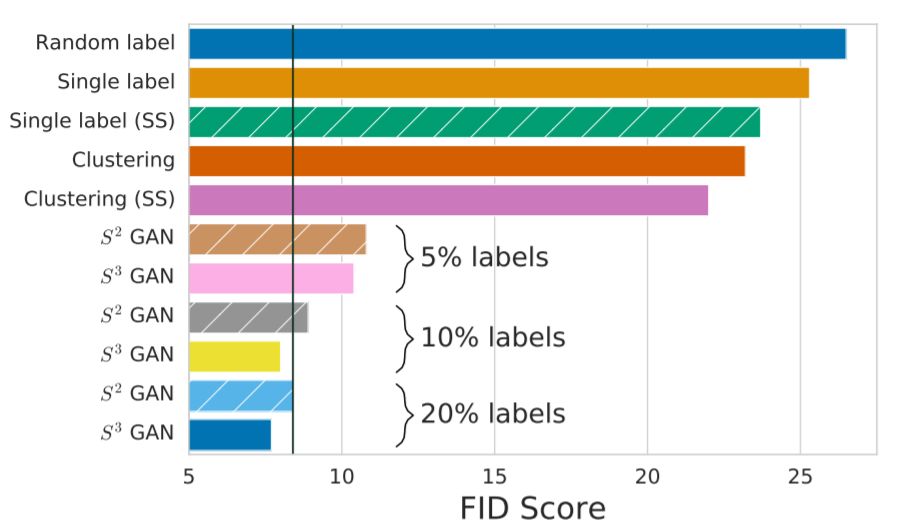
条件GAN与基线BigGAN的FID分数对比,图中黑色竖线为BigGAN基线模型(使用全部标记数据)得分。S3GAN在仅使用10%标记数据的情况下,得分比基线模型最优得分高20%
在条件GAN中,生成器和判别器通常都以分类标签为应用条件。现在,研究人员建议使用推断得出的数据标签,来替换手工标记的真实标签。
上行:BigGAN全监督式学习生成的128×128像素最优图像样本。下行为S3GAN生成的图像样本,标记数据量降低了90%,FID得分与BigGAN表现相当
为了推断大型数据集中多数未标记数据的高质量标签,可以采取两步方法:首先,仅使用数据集的未标记部分来学习特征表示。
为了学习特征表示,需要利用新方法,以不同的方法利用自我监督机制:将未标记的图像进行随机旋转,由深度卷积神经网络负责预测旋转角度。这背后的思路是,模型需要能够识别主要对象及其形状,才能在此类任务中获得成功。
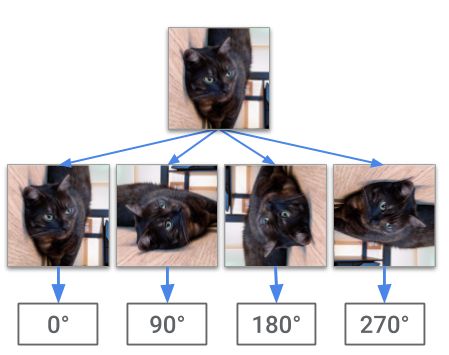
对一幅未标记的图像进行随机旋转,网络的任务是预测旋转角度。成功的模型需要捕捉有意义的语义图像特征,这些特征可用于完成其他视觉任务
研究人员将训练网络的一个中间层的激活模式视为输入的新特征表示,并训练分类器,以使用原始数据集的标记部分识别该输入的标签。由于网络经过预训练,可以从数据中提取具有语义意义的特征,因此,训练此分类器比从头开始训练整个网络更具样本效率。最后使用分类器对未标记的数据进行标记。
为了进一步提高模型质量和训练的稳定性,最好让判别器网络学习有意义的特征表示。通过这些改进手段,在加上大规模的训练,使得新的条件GAN在ImageNet图像合成任务上达到了最优性能。
给定潜在向量,由生成器网络生成图像。在每行中,最左侧和最右侧图像的潜在代码之间的线性插值导致图像空间中的语义插值
CompareGAN:用于训练和评估GAN的库
对GAN的前沿研究在很大程度上依赖于经过精心设计和测试的代码库,即使只是复制或再现先前的结果和技术,也需要付出巨大努力。
为了促进开放科学并让研究界从最近的进步中获益,研究人员发布了Compare GAN库的重大更新。该库包括现代GAN中常用的损失函数,正则化和归一化方案,神经架构和量化指标,现已支持:
GPU和TPU训练
通过Gin进行轻量级配置(含实例)
通过TensorFlow数据集库提供大量数据集
未来方向:自监督学习会让GAN更强大
由于标记数据源和未标记数据源之间的差距越来越大,让模型具备从部分标记的数据中学习的能力变得越来越重要。
目前来看,自监督学习和半监督学习的简单而有力的结合,有助于缩小GAN的这一现实差距。自监督是一个值得研究的领域,值得在该领域开展面向其他生成建模任务的研究。
-
谷歌
+关注
关注
27文章
6178浏览量
105713 -
GaN
+关注
关注
19文章
1952浏览量
73829
原文标题:谷歌大脑打造“以一当十”的GAN:仅用10%标记数据,生成图像却更逼真
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
借助谷歌Gemini和Imagen模型生成高质量图像

Freepik携手Magnific AI推出AI图像生成器
深入理解渲染引擎:打造逼真图像的关键

谷歌发布AI文生图大模型Imagen
谷歌发布Imagen 3,提升图像文本生成技术
OpenAI发布图像检测分类器,可区分AI生成图像与实拍照片
深度学习生成对抗网络(GAN)全解析





 工商网监
工商网监
评论