 爬虫框架是什么
爬虫框架是什么
爬虫框架是什么
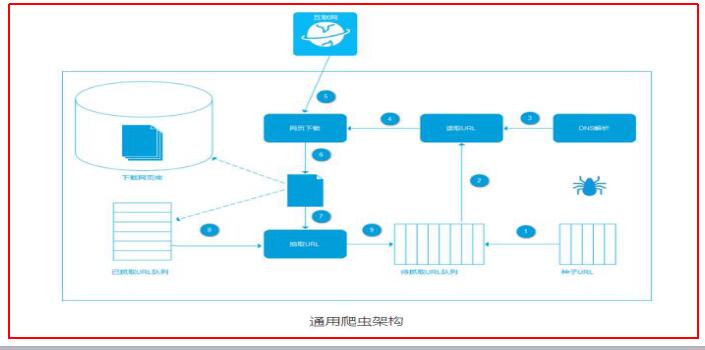
爬虫系统首先从互联网页面中精心选择一部分网页,以这些网页的链接地址作为种子URL,将这些种子放入待抓取URL队列中,爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。
然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面的下载。
对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取队列中,这个队列记录了爬虫系统已经下载过的网页URL,以避免系统的重复抓取。
对于刚下载的网页,从中抽取出包含的所有链接信息,并在已下载的URL队列中进行检查,如果发现链接还没有被抓取过,则放到待抓取URL队列的末尾。在之后的抓取调度中会下载这个URL对应的网页。
如此这般,形成循环,直到待抓取URL队列为空,这代表着爬虫系统将能够抓取的网页已经悉数抓完,此时完成了一轮完整的抓取过程。
爬虫框架有哪些
1、神箭手云爬虫框架
是一个免费的网络爬虫框架,为开发者提供成套的开发教程和开发工具,为企业提供专业化的数据抓取、数据实时监控和数据分析服务。
最大的特点是一站式服务,通过底层框架简化了网络爬虫开发难度,而且提供了丰富的开源网络爬虫资源。
2、Nutch
这是一个开源Java实现的搜索引擎,提供了我们运行自己的搜索引擎所需的全部工具,包括全文搜索和Web爬虫。Nutch目前最新的版本为versionv2.3。
3、Crawler4j
Crawler4j是一个开源的Java类库提供一个用于抓取Web页面的简单接口。可以利用它来构建一个多线程的Web爬虫。
4、WebMagic
WebMagic是一个简单灵活的Java爬虫框架。
它的特性包括:简单的API,可快速上手;模块化的结构,可轻松扩展;提供多线程和分布式支持
5、Heritrix
这是一个由java开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
-
爬虫
+关注
关注
0文章
82浏览量
6933
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论