 从上到下的系统架构分析方法Intel PMU的详细资料概述
从上到下的系统架构分析方法Intel PMU的详细资料概述
引言
现代 CPU 大多具有性能监控单元(Performance Monitoring Unit, PMU),用于统计系统中发生的特定硬件事件,例如缓存未命中(Cache Miss)或者分支预测错误(Branch Misprediction)等。同时,多个事件可以结合计算出一些高级指标,例如每指令周期数(CPI),缓存命中率等。一个特定的微体系架构可以通过 PMU 提供数百个事件。对于发现和解决特定的性能问题,我们很难从这数百个事件中挑选出那些真正有用的事件。 这需要我们深入了解微体系架构的设计和 PMU 规范,才能从原始事件数据中获取有用的信息。
自顶向下的微体系架构分析方法(Top-Down Microarchitecture Analysis Method, TMAM)可以在乱序执行的内核中识别性能瓶颈,其通用的分层框架和技术可以应用于许多乱序执行的微体系架构。TMAM 是基于事件的度量标准的分层组织,用于确定应用程序中的主要性能瓶颈,显示运行应用程序时 CPU 流水线的使用情况。
概述
现代高性能 CPU 的流水线非常复杂。 一般来说,CPU 流水线在概念上分为两部分,即前端(Front-end)和后端(Back-end)。Front-end 负责获取程序代码指令,并将其解码为一个或多个称为微操作(uOps)的底层硬件指令。uOps 被分配给 Back-end 进行执行,Back-end 负责监控 uOp 的数据何时可用,并在可用的执行单元中执行 uOp。 uOp 执行的完成称为退役(Retirement),uOp 的执行结果提交并反馈到>架构状态(CPU 寄存器或写回内存)。 通常情况下,大多数 uOps 通过流水线正常执行然后退役,但有时候投机执行的 uOps 可能会在退役前被取消,例如在分支预测错误的情况下。
在最近的英特尔微体系结构上,流水线的 Front-end 每个 CPU 周期(cycle)可以分配4个 uOps ,而 Back-end 可以在每个周期中退役4个 uOps。 流水线槽(pipeline slot)代表处理一个 uOp 所需的硬件资源。 TMAM 假定对于每个 CPU 核心,在每个 CPU 周期内,有4个 pipeline slot 可用,然后使用专门设计的 PMU 事件来测量这些 pipeline slot 的使用情况。在每个 CPU 周期中,pipeline slot 可以是空的或者被 uOp 填充。 如果在一个 CPU 周期内某个 pipeline slot 是空的,称之为一次停顿(stall)。如果 CPU 经常停顿,系统性能肯定是受到影响的。TMAM 的目标就是确定系统性能问题的主要瓶颈。
下图展示并总结了乱序执行微体系架构中自顶向下确定性能瓶颈的分类方法。这种自顶向下的分析框架的优点是一种结构化的方法,有选择地探索可能的性能瓶颈区域。 带有权重的层次化节点,使得我们能够将分析的重点放在确实重要的问题上,同时无视那些不重要的问题。
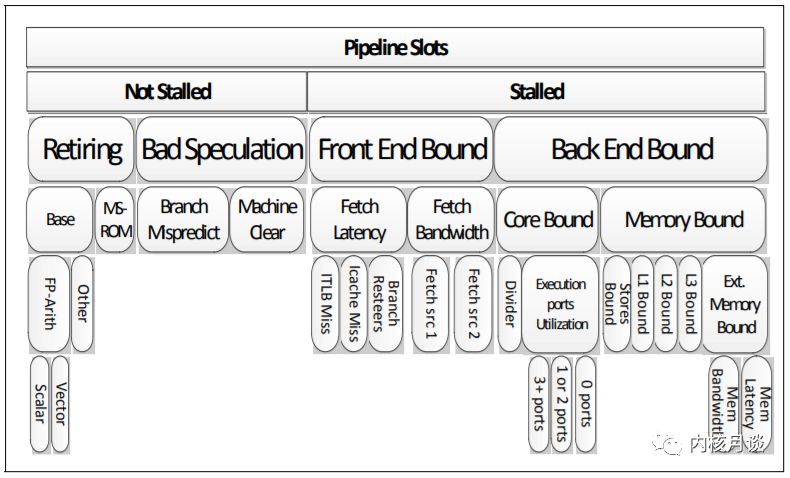
例如,如果应用程序性能受到指令提取问题的严重影响, TMAM 将它分类为 Front-end Bound 这个大类。 用户或者工具可以向下探索并仅聚焦在 Front-end Bound 这个分类上,直到找到导致应用程序性能瓶颈的直接原因或一类原因。
设计
Top Level
在最顶层,TMAM 将 pipeline slot 分为四个主要类别:
Front-end Bound
1Front-endBound表示pipeline的Front-end不足以供应Back-end。
Front-end是pipeline的一部分,负责交付uOps给Back-end执行。
Front-endBound进一步分为FetchLatency(例如,ICacheorITLBmisses)
和FetchBandwidth(例如,sub-optimaldecoding)。
Back-end Bound
1Back-endBound表示由于缺乏接受执行新操作所需的后端资源而导致
停顿的pipelineslot。它进一步分为分为MemoryBound(由于内存子系统造成的
执行停顿)和CoreBound(执行单元压力ComputeBound或者缺少指令级并行ILP)。
Bad Speculation
1BadSpeculation表示由于分支预测错误导致的pipelineslot被浪费,
主要包括(1)执行最终被取消的uOps的pipelineslot,以及(2)由于从
先前的错误猜测中恢复而导致阻塞的pipelineslot。
Retiring
1Retiring表示运行有效uOp的pipelineslot。理想情况下,
我们希望看到所有的pipelineslot都能归类到Retiring,
因为它与IPC密切相关。尽管如此,高Retiring比率并不意味着没有提升优化的空间。
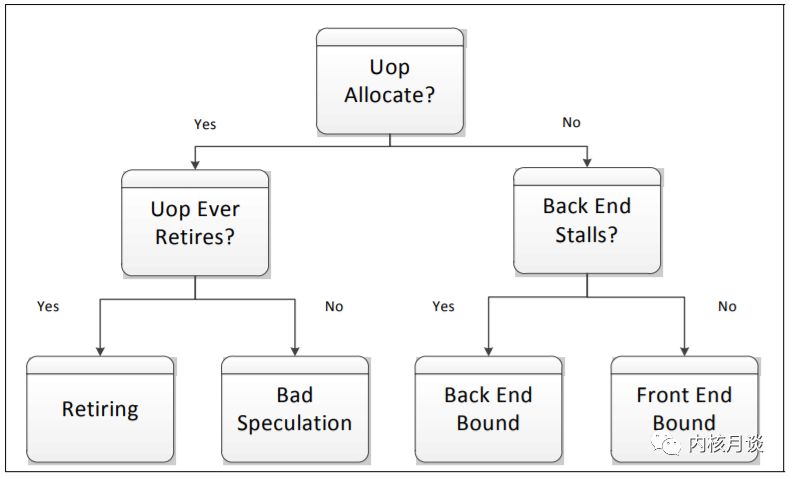
后两者表示非停顿的 pipeline slot,前两者表示停顿的 pipeline slot。 下图描述了一个简单的决策树来展示向下分析的过程。如果一个 pipeline slot 被某个 uOp 使用,它将被分类为 Retiring 或 Bad Speculation,具体取决于它是否最终提交。如果 pipeline 的 Back-end 部分不能接受更多操作(也称为 Back-end Stall),未使用的 pipeline slot 被分类为 Back-end Bound。Front-end Bound 则表示>在没有 Back-end Stall 的情况下没有操作(uOps)被分配执行。
Front-end Bound
在许多情况下,Front-end 指令带宽可能会影响性能,特别是在高 IPC 的情况下。一些专用单元被引入,用来隐藏流水线 Fetch 指令延迟以及维持所需的带宽,例如 Loop Stream Detector (LSD) 以及 Decoded I-cache (DSB)。
TMAM 进一步将 Front-end Bound 划分为延迟和带宽两个子类:
ICache miss 属于 Fetch Latency 分类
指令解码器的低效问题属于 Fetch Bandwidth 分类
这些度量标准都是以自顶向下的方式定义的。Fetch Latency 表示任何原因导致的指令提取饥饿(没有指令输送)。我们所熟知的 icache and i-TLB miss 就属于这个类别,但是并不局限于此。Branch Resteers 表示流水线刷新(pipeline flush)之后的指令提取延迟。pipeline flush 可能由一些清除状态的事件引起,例如 branch misprediction 或者 memory nukes。Branch Resteers 与 Bad Speculation 密切相关。
Back-end Bound
Back-end Bound 分为 Memory Bound 和 Core Bound,通过在每个周期内基于执行单元的占用情况来分析 Back-end 停顿。为了达到尽可能大的 IPC,需要使得执行单元保持繁忙。例如,在一个有4个 slot 的机器中,如果在稳定状态下只能执行三个或更少的 uOps,就不能达到最佳状态,即 IPC 等于4。这些次优周期称为 Execution Stalls。
Memory Bound
1MemoryBound对应缓存和内存子系统相关的ExecutionStalls。这些停顿通常表现为执行单元在短时间内饥饿,例如load操作没有在缓存中命中。对于常见情况,内存访问的真正代价是调度程序没有其他准备好的uOps提供给执行单元。后面的uOps可能正在等待进行中的内存访问,或者依赖于其他未准备好的uOps。23ExecutionStalls包含几个子类,每个子类都与特定的高速缓存级别相关联,取决于各个高速缓存级别是否可以满足所需的数据。在某些情况下,ExecutionStall可能会经历显著的延迟,远远大于相应缓存级别的标准延迟,即使没有发生相应的缓存未命中。例如,L1D高速缓存通常具有与ALU停顿相当的较短的延迟。然而在某些情况下,如load操作被阻塞,无法将数据从较早的store操作转发(forward)到一个重叠地址,这个load负载可能会遭受较高的延迟,虽然最终能在L1D中命中。在这种情况下,in-flight的load操作将持续很长时间并且不会产生L1Dmiss。因此,这个问题属于L1Bound子类。45此外,与store操作相关的ExecutionStalls都属于StoresBound子类。由于内存访问顺序要求,store操作被缓存并异步执行。通常,store操作对性能影响很小,但不能完全忽视。TMAM将StoresBound定义为那些执行端口利用率(executionportutilization)较低,以及存在大量需要消耗资源用来缓冲store操作的周期。67最后,TMAM在Ext.MemoryBound子类下使用了一个简单的启发式算法来区分MEMBandwidth和MEMLatency。该启发式算法的主要根据是当前有多少请求依赖从内存中获取的数据。每当这类请求的占用率超过一个高阈值时(例如最大请求数的70%),TMAM将其标记为可能受内存带宽的限制。其他部分都属于内存延迟子类。
Core Bound
1CoreBound对应于执行单元存在压力或者程序中缺少指令级别并行(ILP)。Corebound的
停顿可能表现为较短的执行饥饿周期或者执行端口利用率不佳,这使得识别Corebound比较困难。
例如,一个长延迟的除法操作可能会序列化执行,而服务于特定类型uOps的执行端口上的压力
可能表现为一个周期内只有少量端口被使用。23CoreBound的问题一般可以通过更好的代码生成来缓解。例如,一系列相关的算术
运算将被标记为CoreBound。编译器可以通过更好的指令调度来缓解这种停顿。
矢量化(Vectorization)也可以缓解CoreBound的问题。
Bad Speculation
Bad Speculation 表示由于不正确的预测而浪费的 pipeline slot,主要包括两部分:
执行了最终不会被提交的 uOps 的 slots
从错误预测中恢复而导致流水线被阻塞的 slots
TMAM 的一个关键原则就是将 Bad Speculation 放在了最顶层, Bad Speculation 确定了受到错误执行路径影响的工作负载的比例,并反过来决定了其他类别中观察值的准确性。TMAM 进一步将 Bad Speculation 分类为 Branch Mispredict 和 Machine Clears,这两种情况导致的问题和 pipeline flush 相像。Branch Mispredict 主要关注如何使程序控制流对分支预测更友好,Machine Clears 则主要指出一些异常情况,例如清除内存排序机(memory ordering machine clears)或者自修改代码(self modifying code)。
Retiring
理想情况下,我们希望看到所有的 slots 都被标记为 Retiring 类别。尽管如此,Retiring 比例高并不意味着没有更多的性能提升空间。诸如 Floating Point Assists (FP_ASSISTS) 的微指令(Microcode)序列通常会影响性能并且可以避免。这类情况被标记为 MSROM 子类以便引起注意。
非矢量化(non-vectorized)代码的高 Retiring 比值可能是进行向量化(vectorization)代码的一个重要提示。这样做基本上可以让更多的操作通过单指令 uOp 完成,从而提高性能。TMAM 进一步将 Retiring->Base 子类划分为 FP Arith,并区分标量操作和矢量操作。
应用/工具
pmu-tools 是 Adni Kleen 开发的开源工具包,针对 Intel CPU 提供友好的接口来访问原始事件,并提供一些附加功能。toplev 是 pmu-tools 中的一个工具,在 Intel CPU 的 Linux perf 基础上实现了 TMAM 方法。toplev 可以定位 CPU Bound 代码的瓶颈,不能识别其他(Not bound by CPU)代码的瓶颈。toplev 是一个计数工具,它使用 PMU 来计数事件。toplev 的一个典型使用场景是,用户已经根据一个标>准工具(例如 perf, sysprof, pyprof)进行采样,了解 hot code 的分布,但是你想知道为什么这部分代码运行很慢。
安装
toplev 在 Linux 上运行,需要安装 perf 工具。toplev 还需要访问 PMU,在 VM 中运行时需要注意启用这个特性。注意,toplev 需要禁用 NMI watchdog,并以 root 身份运行。
1%gitclonehttps://github.com/andikleen/pmu-tools2%cdpmu-tools3%exportPATH=$PATH:`pwd`4%sudosysctl-p'kernel.nmi_watchdog=0'
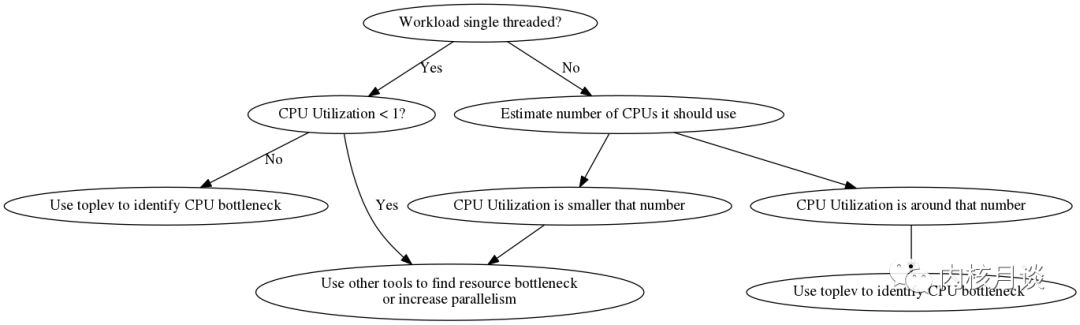
确定 CPU Bound 任务
第一步是确定程序是否真的是 CPU Bound 型工作负载。toplev 只能帮助定位解决 CPU Bound 问题。如果瓶颈在其他地方,则必须使用其他方法。非 CPU 瓶颈可以是网络,磁盘IO,显卡等。
选择要计数的代码
一般来说toplev测量整个系统的性能数据;当指定一个工作负载时,toplev将在工作负载运行的时间段内测量整个系统,这一点和perf的使用是类似的。
1%toplev.pymy-workload2或者3%toplev.pysleepXXX
让我们衡量一个简单的工作负载。这是一个 bc 表达式,在作者电脑上运行大约1秒(在大多数情况下,使用长时间运行的工作负载可能会更好),使用第一层级(-lxxx 参数用来设定测量的最大层级)运行以避免任何 PMU 计数器的多路复用。
1%toplev.py-l1bash-c'echo"7^199999"|bc>/dev/null' 2Willmeasurecompletesystem. 3Usinglevel1. 4... 5C0BADBad_Speculation:31.66% 6Thiscategoryreflectsslotswastedduetoincorrect 7speculations,whichincludeslotsusedtoallocateuopsthat 8donoteventuallygetretiredandslotsforwhichallocation 9wasblockedduetorecoveryfromearlierincorrect10speculation...11C1FEFrontend_Bound:42.46%12ThiscategoryreflectsslotswheretheFrontendofthe13processorundersuppliesitsBackend...14C1BEBackend_Bound:27.25%15Thiscategoryreflectsslotswherenouopsarebeing16deliveredduetoalackofrequiredresourcesforaccepting17moreuopsintheBackendofthepipeline...18C0-T0CPUutilization:0.00CPUs19NumberofCPUsused...20C0-T1CPUutilization:0.00CPUs21C1-T0CPUutilization:0.00CPUs22C1-T1CPUutilization:0.00CPUs
每当首次打印层节点时,toplev 都会打印一个描述。默认情况下,它显示一个简短描述,长描述可以使用--long-desc来启用。在之后的例子中,我们禁用描述以获得较短的输出。toplev 输出中,一些值以 core 为单位,另一些则以 thread 为单位收集。多 socket 的情况下还会有 socket 分类。
上面的例子中,我们没有将工作负载(bc)绑定到某个 CPU,所以不清楚 C0 或 C1 的值是否相关。由于 bc 是单线程的,我们可以将它绑定到一个已知的 CPU 核心,并使用--core来过滤该核心上的输出。
1%toplev.py--coreC0--no-desc-l1taskset-c0bash-c'echo"7^199999"|bc>/dev/null'2Willmeasurecompletesystem.3Usinglevel1.4...5C0BADBad_Speculation:33.29%6C0-T0CPUutilization:0.00CPUs7C0-T1CPUutilization:0.00CPUs
可以结合 taskset 绑定到更多的 CPU 进行多线程工作,并将结果进行过滤。结果显示bc受限于 Bad Speculation。现在我们可以选择更多的节点并更详细地分析问题。
如果已知工作负载是单线程的,并且系统当前空闲,那么也可以显式指定--single-thread选项来测量工作负载,而不是默认测量整个系统
1%toplev.py--no-desc--single-threadbash-c'echo"7^199999"|bc>/dev/null'2..3BADBad_Speculation:32.65%4CPUutilization:0.00CPUs
程序在初始化阶段的行为相比生命周期后期的行为有很大的差异。为了精确测量,跳过这个阶段通常是有用的。这可以用-D xxx选项来完成,xxx是跳过的毫秒数(需要较新版本的 perf)。当程序运行时间足够长时,这通常是不需要的,但是它有助于提高小测试的精度。默认情况下,toplev 同时测量内核和用户代码。如果只对用户代码感兴趣,则可以使用--user选项。这往往会减少测量噪声,因为中断被过滤掉了。还有一个--kernel选项用来测量内核代码。在具有多个阶段的复杂工作负载上,测量间隔也是有用的。这可以用-I xxxi选项指定,xxx是间隔的毫秒数。perf 要求时间间隔至少需要 100ms。toplev 将输出每个间隔的测量值。这往往会产生大量的数据,所以绘制输出很有必要。
选择正确的层次和多路复用
PMU 只有有限数量的计数器可以同时测量事件。任何多于一个层次的 toplev 运行,或者启动了额外的CPU 指标,则需要更多的计数器。在这种情况下,内核驱动程序将开始多路复用(Multiplexing),并定期更改事件组(在1毫秒和10毫秒之间,通常2.5毫秒,取决于内核配置)。多路复用可能会导致测量错误,因为 toplev 中的几个节点中的公式需要关联多个事件组的数据。因此 toplev 在反复执行同样事情的工作负载上效果最好,但在执行许多不同的短事件的工作负载上效果不佳。
只要没有使用 PMU 的或者有问题的其他工作负载处于活动状态,则第一层次(-l1)和未启用额外指标的 toplev 不会进行多路复用。一开始的时候,不采用多路复用来进行分析通常是一个好主意。更高的层次和指标提供了额外的信息,但也增加了复用,因此可能导致更多的测量错误。如果工作负载非常重复,可以使用--no-multiplex关闭复用。toplev 会根据需要多次重新运行工作量。在 BIOS 中禁用超线程将使通用计数器的数量增加一倍,并减少多路复用。
有关问题的更多详细信息和解决方法,可以参阅 reasons for measuring issues
数组求和实例的测试分析
我们考虑测量一些 beating the compiler 的例子。beating the compiler 实现了一个简单的问题,即数组求和,从高级脚本语言开始,然后利用底层操作逐步优化。测试代码运行在启用了 Turbo 的 Intel Core i7-4600U(Haswell)笔记本电脑上。
开始是简单直接的Python实现。
1defsum_naive_python():2result=03foriindata:4result+=i5returnresult
我们用 toplev 来运行这段代码,跳过初始化阶段(大约80毫秒,通过预先测量得到)。一般来说,测量太短的程序是很困难的(太多的其他影响占主导地位)。在这种情况下,我们通过迭代5000次测试来调试程序运行至少几秒钟。
1%toplev.py-D80-l1--no-desc--coreC0taskset-c0pythonfirst.pynumbers2..3C0FEFrontend_Bound:22.08%4C0RETRetiring:75.01%
所以 Python 是一点 Front-end Bound,但是从 toplev 中没有其他发现可见的问题。我们可以通过将层级提高到3来更仔细地分析 Front-end Bound。注意这可能有缺点,因为它会导致多路复用。在这种情况下,工作负载运行时间越长越好(我们将基准函数循环5000次)。
1%toplev.py-D80-l3--coreC0taskset-c0pythonfirst.pynumbers 2... 3C0FEFrontend_Bound:21.91% 4C0FEFrontend_Bound.Frontend_Bandwidth:15.91% 5C0FEFrontend_Bound.Frontend_Bandwidth.DSB:32.11% 6ThismetricrepresentsCorecyclesfractioninwhichCPUwas 7likelylimitedduetoDSB(decodeduopcache)fetch 8pipeline... 9C0RETRetiring:74.97%10C0RETRetiring.Base:74.88%
可以观察到 Front-end Bound 是 DSB (decoded uop cache) fetch。具体描述被简化了,可以使用--long-desc来查看更具体的描述。
让我们来看看第二个 Python 版本。这个版本使用 Python 中的内建函数 sum() 来数组求和,以便将更多的执行动作从解释器推送到 Python C 核心。
1defsum_builtin_python():2returnsum(data)
在这种情况下,我们知道 python 代码是单线程的(系统的其余部分是空闲的),所以可以使用--single-thread。
1%toplev.py--single-thread-l3-D80pythonsecond.pynumbers2...3FEFrontend_Bound:27.40%4FEFrontend_Bound.Frontend_Bandwidth:23.20%5FEFrontend_Bound.Frontend_Bandwidth.DSB:46.30%6ThismetricrepresentsCorecyclesfractioninwhichCPUwas7likelylimitedduetoDSB(decodeduopcache)fetch8pipeline...
然而这并没有改变多少结果。Python 是相当重(heavy-weight)的,大大加重了 CPU 的前端,但其中大部分至少在解码的 icache 中运行。
现在我们来看一个标准的C实现,它应该快得多:
1intsum_simple(int*vec,size_tvecsize)2{3intres=0;4inti;5for(i=0;i< vecsize; ++i) {6 res += vec[i];7 }8 return res;9}
这个循环被编译成一个简单的测试工具,使用 gcc 4.8.3 并关闭优化,使用 toplev 进行测量:
1%toplev.py-l1--single-thread--force-events./c1-unoptimizednumbers2BEBackend_Bound:60.34%3Thiscategoryreflectsslotswherenouopsarebeing4deliveredduetoalackofrequiredresourcesforaccepting5moreuopsintheBackendofthepipeline...
这个版本比 Python 版本运行速度快4倍。瓶颈已经完全进入 Back-end。我们可以在第三层级更仔细地看待它:
1%toplev.py-l3--single-thread--force-events./c1-unoptimizednumbers 2BEBackend_Bound:60.42% 3BE/MemBackend_Bound.Memory_Bound:32.23% 4BE/MemBackend_Bound.Memory_Bound.L1_Bound:32.44% 5ThismetricrepresentshowoftenCPUwasstalledwithout 6missingtheL1datacache... 7Samplingevents:mem_load_uops_retired.l1_hit:pp,mem_load_uops_retired.hit_lfb:pp 8BE/CoreBackend_Bound.Core_Bound:45.93% 9BE/CoreBackend_Bound.Core_Bound.Ports_Utilization:45.93%10Thismetricrepresentscyclesfractionapplicationwas11stalledduetoCorecomputationissues(nondivider-12related)...
可以看到它是 L1 Bound 和 Core Bound。 L1 Bound 可能是因为未优化的 gcc 代码倾向于将所有变量存储在堆栈上,没有进行全面的寄存器优化。 我们可以用-O2打开优化器,看看会发生什么:
1%toplev.py-l3--single-thread./c1-o2numbers2RETRetiring:83.66%3RETRetiring.Base:83.62%4ThismetricrepresentsslotsfractionwheretheCPUwas5retiringuopsnotoriginatedfromthemicrocode-sequencer...6Samplingevents:inst_retired.prec_dist:pp
L1 Bound 完全消失,工作负载的大部分时间都在 Retire,这是很好的。这个版本也比未优化的C版本快了85%。注意这些好处有些极端的情况,可能完全取决于代码的行为。
优化 Retiring 的一种方法是对代码进行矢量化(Vectorization),并在每条指令上做更多的工作。通过gcc -O3启用矢量化。不幸的是,它不能矢量化我们简单的循环。
1c1.c:9:note:notvectorized:notsuitableforgatherload_32=*_31;
我们可以从 beating the compiler 中尝试Roguelazer手动优化的内嵌汇编 AVX2 版本。这应该会减少 Retiring,因为它在每个 SIMD 指令中可以执行多达8个加法,同时它还使用了循环展开。
1%toplev.py-l3--single-thread./c-asmnumbers 2BEBackend_Bound:64.15% 3BE/MemBackend_Bound.Memory_Bound:... 4BE/MemBackend_Bound.Memory_Bound.L1_Bound:49.32% 5ThismetricrepresentshowoftenCPUwasstalledwithout 6missingtheL1datacache... 7Samplingevents:mem_load_uops_retired.l1_hit:pp,mem_load_uops_retired.hit_lfb:pp 8BE/MemBackend_Bound.Memory_Bound.L3_Bound:48.68% 9ThismetricrepresentshowoftenCPUwasstalledonL3cache10orcontendedwithasiblingCore...11Samplingevents:mem_load_uops_retired.l3_hit:pp12BE/CoreBackend_Bound.Core_Bound:28.27%13BE/CoreBackend_Bound.Core_Bound.Ports_Utilization:28.27%14Thismetricrepresentscyclesfractionapplicationwas15stalledduetoCorecomputationissues(nondivider-16related)...
Retiring 瓶颈已经消失,我们终于看到了 Backend_Bound.Memory_Bound 瓶颈,在这种情况下,L1 Bound 和 L3 Bound所占百分比几乎相等,其余的是核心执行。
-
寄存器
+关注
关注
31文章
5405浏览量
122960 -
cpu
+关注
关注
68文章
11017浏览量
215441 -
PMU
+关注
关注
1文章
117浏览量
22046
原文标题:从上到下的系统架构分析方法 - Intel PMU
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
stm32 mini板子框体刷屏时框体本身明显有从上到下的刷屏感觉
汽车控制电脑板的元件分析和详细资料概述


PLC控制系统的设计与应用实例详细资料概述





 工商网监
工商网监
评论