 中午不知道吃什么,用Python爬取美团外卖评论帮你选餐
中午不知道吃什么,用Python爬取美团外卖评论帮你选餐
一、介绍
朋友暑假实践需要美团外卖APP评论这一份数据,一开始我想,这不就抓取网页源代码再从中提取数据就可以了吗,结果发现事实并非如此,情况和之前崔大讲过的分析Ajax来抓取今日头条街拍美图类似,都是通过异步加载的方式传输数据,不同的是这次的是通过JS传输,其他的基本思路基本一致,希望那些数据能帮到她吧
二、流程
目标站点分析用浏览器打开美团外卖APP评论,F12
1.首先我们要找到我们想要的评论数据,在第一次“失败”的直接抓取网页源代码后,我们发现它是通过Ajax加载的,我们点击JS选项,可以发现JS项目里面的返回结果有我们想要的数据,勾选Preserve log,当点击查看更多评论时,后台(JS里)会出现新的Ajax请求,发现还有参数start和的变化,其他请求参数不变,start的参数变化是以10递增的,的参数变化可就让人摸不着头脑(这个时候我们也不要方,因为大多情况下没有规律的参数都是没用的)
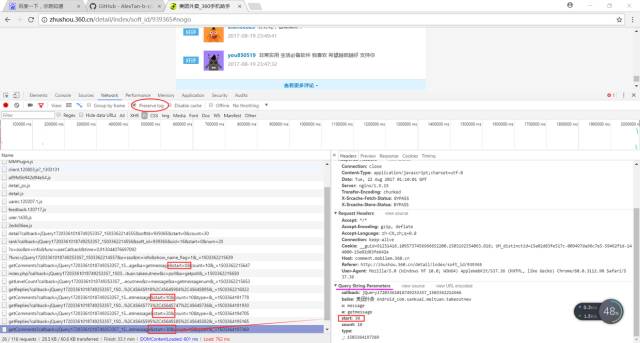
2.经过我们对http://comment.mobilem.360.cn/comment/getComments?callback=jQuery17203361018749253357_1503362214558&baike=%E7%BE%8E%E5%9B%A2%E5%A4%96%E5%8D%96+Android_com.sankuai.meituan.takeoutnew&c=message&a=getmessage&start=0&count=10&_=1503362215647进行分析后发现它的标准式为‘http://comment.mobilem.360.cn/comment/getComments?&baike=%E7%BE%8E%E5%9B%A2%E5%A4%96%E5%8D%96+Android_com.sankuai.meituan.takeoutnew&start=’+str(i*10),i每次增加1,就包含新的十条评论的内容,所以我们通过改变i的值就可以拿到不同的数据
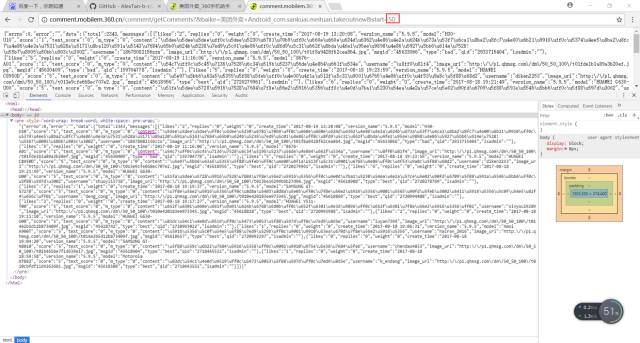
分析url的网页源代码,在源代码里有我们想要的评论数据,我们可以用正则(在这里正则还是比较好用的)把我们想要的信息弄下来
开启循环,批量抓取
保存数据至文本和数据库
#之前是这样处理的:def parse_one_page(html): pattern2 = re.compile('"m_type":"0",(.*?),"username"', re.S) items=re.findall(pattern2,html) for item in items: item = "{" + item + "}" item=json.loads(item) write_to_file(item) print(item) save_to_mongo(item)#皮皮哥告诉了我他的独家正则匹配方法可以匹配出来,这样的确获得的item没有编码问题def parse_one_page(html): pattern = '"content":".*?"' items=re.findall(pattern,html) for item in items: item =eval(item.split(':',1)[1]) write_to_file(item) print(item) save_to_mongo(item)#对一般正则写法获得的item进行的方法,这是从皮皮哥那里得知的,亲测有效def parse_one_page(html): pattern = re.compile('rsion_name".*?"content":(.*?),"username"', re.S) items=re.findall(pattern,html) #print(items) for item in items: item = item.encode('utf-8').decode('unicode_escape') write_to_file(item) print(item) save_to_mongo(item)三、代码
#config.pyMONGO_URL='localhost'MONGO_DB='meituan'MONGO_TABLE='meituan'
import requestsfrom requests.exceptions import RequestExceptionimport jsonimport refrom day31.config import *import pymongoclient=pymongo.MongoClient(MONGO_URL)db=client[MONGO_DB]base_url='http://comment.mobilem.360.cn/comment/getComments?callback=jQuery17209056727722758744_1502991196139&baike=%E7%BE%8E%E5%9B%A2%E5%A4%96%E5%8D%96+Android_com.sankuai.meituan.takeoutnew&start='def the_url(url): try: response = requests.get(url) if response.status_code==200: response.encoding='utf-8' return response.text return None except RequestException: print('请求出错') return Nonedef the_total(): html=the_url(base_url) pattern1 = re.compile('"total":(.*?),"messages"', re.S) Total = re.findall(pattern1, html) Total=int(':'.join(Total)) #print(type(Total)) show='总计评论%d条'%Total print(show) write_to_file(show) return Totaldef parse_one_page(html): pattern2 = re.compile('"m_type":"0",(.*?),"username"', re.S) items=re.findall(pattern2,html) for item in items: item = "{" + item + "}" item=json.loads(item) write_to_file(item) print(item) save_to_mongo(item)def save_to_mongo(result): try: if db[MONGO_TABLE].insert(result): print('储存到MongoDB成功',result) except Exception: print('储存到MongoDB失败',result)def write_to_file(content): with open('meituan_result.text','a',encoding='utf-8') as f: f.write(json.dumps(content,ensure_ascii=False)+'\n') f.close()def main(): Total=the_total() Total=int(Total/10)+2 for i in range(Total): url = base_url + str(i*10) if the_url(url)!=None: html=the_url(url) parse_one_page(html) else: print('输完啦') ps='PS:因为有些评论空,所以实际评论比抓取的少' #这是我瞎猜的 write_to_file(ps) print(ps)if __name__ == '__main__': main()
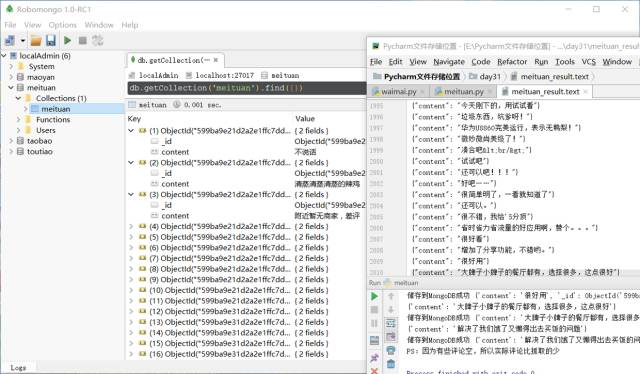
四、最后得到的数据视图和文件
五、总结
1.程序报错很正常,不要一报错就问别人,先自己思考、百度
2.在数据类型处理方面的知识还要加强
-
源代码
+关注
关注
96文章
2946浏览量
66800 -
python
+关注
关注
56文章
4799浏览量
84810
原文标题:中午不知道吃什么?用Python爬取美团外卖评论帮你选餐!
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
校园点餐订餐外卖跑腿Java源码

DAC7714应用于MCBSP模块,clk与cs都是模块内部产生的,LD信号不知道怎么给出?
华为Mate系列新品携手美团外卖首发
关于陶瓷电路板你不知道的事

又一电工不知道,施耐德变频器怎么复位,如果不告诉你,你知道怎么复位吗?






 工商网监
工商网监
评论