 谷歌全神经元的设备端语音识别器再推新品
谷歌全神经元的设备端语音识别器再推新品

在近二十年来,尤其是引入深度学习以后,语音识别取得了一系列重大突破,并一步步走向市场并搭载到消费级产品中。然而在用户体验上,「迟钝」可以算得上这些产品最大的槽点之一,这也意味着语音识别的延迟问题已经成为了该领域研究亟待解决的难点。日前,谷歌推出了基于循环神经网络变换器(RNN-T)的全神经元设备端语音识别器,能够很好地解决目前语音识别所存在的延迟难题。谷歌也将这项成果发布在了官方博客上。
2012 年,语音识别研究表明,通过引入深度学习可以显著提高语音识别准确率,因此谷歌也较早地在语音搜索等产品中采用深度学习技术。而这也标志着语音识别领域革命的开始:每一年,谷歌都开发出了从深度神经网络(DNN)到循环神经网络(RNN)、长短期记忆网络(LSTM)、卷积网络(CNNs)等一系列新的架构,进一步地提高了语音识别的质量。然而在此期间,延迟问题依旧是该领域需要攻克的主要难点——当语音助手能够实现快速回答问题时,用户会感觉它有帮助得多。
日前,谷歌正式宣布推出端到端、全神经元的设备端语音识别器,为 Gboard 中的语音输入提供支持。在谷歌 AI 最近的一篇论文《移动设备的流媒体端到端语音识别》(Streaming End-to-End Speech Recognition for Mobile Devices,论文阅读地址:https://arxiv.org/abs/1811.06621)中,其研究团队提出了一种使用循环神经网络变换器(RNN-T,https://arxiv.org/pdf/1211.3711.pdf)技术训练的模型,该技术也足够精简可应用到手机端上。这就意味着语音识别不再存在网络延迟或故障问题——新的识别器即便处于离线状态也能够运行。该模型处理的是字符水平的语音识别,因此当人在说话时,它会逐个字符地输出单词,这就跟有人在实时键入你说的话一样,同时还能达到你对键盘听写系统的预期效果。
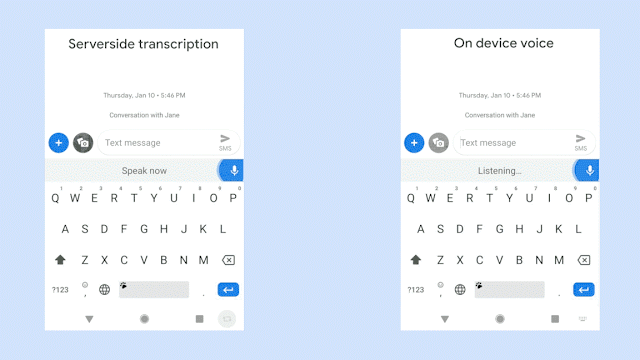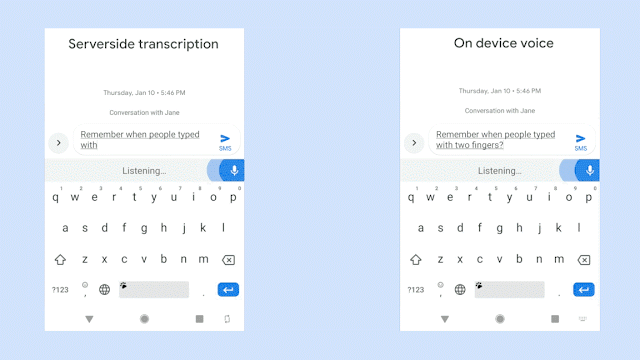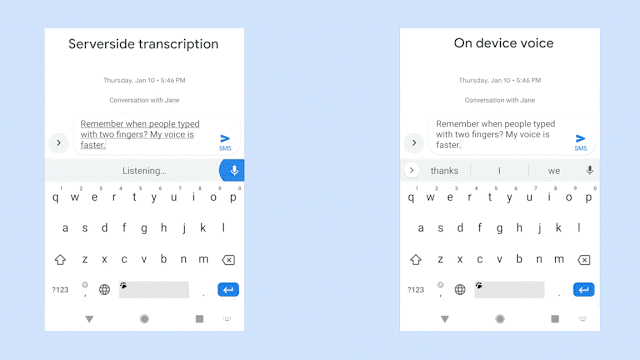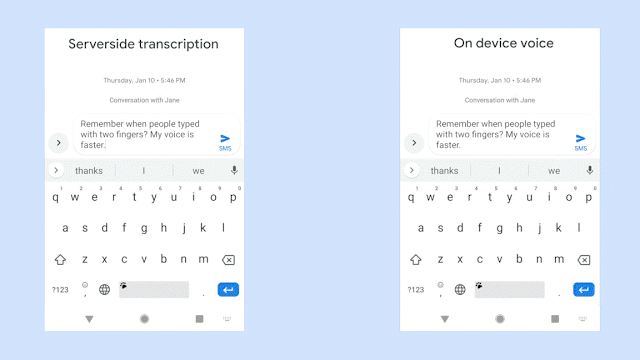
该图对比了识别同一句语音时,服务器端语音识别器(左边)以及新的设备端语音识别器(右边)的生成情况。
关于语音识别的一点历史
传统而言,语音识别系统由几个部分组成:一个将语音分割(一般为 10 毫秒的框架)映射到音素的声学模型;一个将因素合成单词的发音模型;以及一个表达给定短语可能性的语言模型。在早期的系统中,对这些组成部分的优化都是单独进行的。
在 2014 年左右,研究人员就开始重点训练单个神经网络,来直接将一个输入语音波形映射到一个输出句子。研究人员采用这种通过给定一系列语音特征生成一系列单词或字母的序列到序列(sequence-to-sequence)方法开发出了「attention-based」(https://arxiv.org/pdf/1506.07503.pdf)和「listen-attend-spell」(https://arxiv.org/pdf/1508.01211.pdf)模型。虽然这些模型在准确率上表现很好,但是它们一般通过回顾完整的输入序列来识别语音,同时当输入进来的时候也无法让数据流输出一项对于实时语音转录必不可少的特征。
与此同时,当时的一项叫做CTC(connectionist temporal classification)的技术帮助将生产式识别器的延迟时间减半。事实证明,这项进展对于开发出 CTC 最新版本(改版本可以看成是 CTC 的泛化)中采用的 RNN-T 架构来说,是至关重要的一步。
循环神经网络变换器(RNN-T)
RNN-T 是不采用注意力机制的序列到序列模型的一种形式。与大多数序列到序列模型需要处理整个输入序列(本文案例中的语音波形)以生成输出(句子)不同,RNN-T 能持续地处理输入的样本和数据流,并进行符号化的输出,这种符号化的输出有助于进行语音听写。在谷歌研究人员的实现中,符号化的输出就是字母表中的字符。当人在说话时,RNN-T 识别器会逐个输出字符,并进行适当留白。在这一过程中,RNN-T 识别器还会有一条反馈路径,将模型预测的符号输回给自己以预测接下来的符号,具体流程如下图所示:
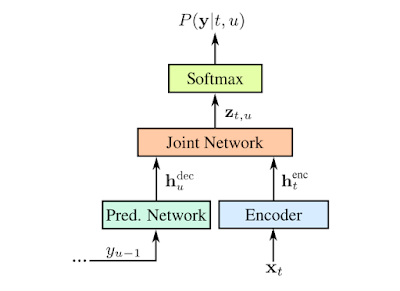
RNN-T 的表示:用 x 表示输入语音样本;用 y 表示预测的符号。预测的符号(Softmax 层的输出)y(u-1)通过预测网络被输回给模型,确保预测同时考虑到当前的语音样本以及过去的输出。预测和解码网络都是LSTM RNN,联合的模型则是前馈网络(feedforward network ,相关论文查看地址:https://www.isca-speech.org/archive/Interspeech_2017/pdfs/0233.PDF)。预测网络由 2 个拥有 2048 个单元的层和 1 个有着 640 个维度的投射层组成。解码网络则由 8 个这样的层组成。图源:Chris Thornton
有效地训练这样的模型本来就已经很难了,然而使用谷歌开发的这项能够进一步将单词错误率减少 5% 的新训练技术,对计算能力也提出了更高的要求。对此,谷歌开发了一种平行实现的方法,让 RNN-T 的损失函数能够大批地在谷歌的高性能云平台 TPUv2 芯片上高效运行。
离线识别
在传统的语音识别引擎中,上文中提到的声学、发音和语言模型被「组合」成一个边缘用语音单元及其概率标记的大搜索图(search graph)。在给定输入信号的情况下,当语音波形抵达识别器时,「解码器」就会在图中搜索出概率最大的路径,并读出该路径所采用的单词序列。一般而言,解码器假设基础模型由 FST(Finite State Transducer)表示。然而,尽管现在已经有精密的解码技术,但是依旧存在搜索图太大的问题——谷歌的生成式模型的搜索图大小近 2GB。由于搜索图无法轻易地在移动电话上托管,因此采用这种方法的模型只有在在线连接的情况中才能正常工作。
为了提高语音识别的有效性,谷歌研究人员还试图通过直接将在设备上托管新模型来避免通信网络的延迟及其固有的不可靠性。因此,谷歌提出的这一端到端的方法,不需要在大型解码器图上进行搜索。相反,它采取对单个神经网络进行一系列搜索的方式进行解码。同时,谷歌研究人员训练的 RNN-T 实现了基于服务器的传统模型同样的准确度,但是该模型大小仅为 450MB,本质上更加密集、更加智能地利用了参数和打包信息。不过,即便对于如今的智能手机来说,450 MB 依旧太大了,这样的话当它通过如此庞大的网络进行网络信号传输时,速度就会变得很慢。
对此,谷歌研究人员通过利用其于 2016 年开发的参数量化(parameter quantization )和混合内核(hybrid kernel)技术(https://arxiv.org/abs/1607.04683),来进一步缩小模型的大小,并通过采用 ensorFlow Lite 开发库中的模型优化工具包来对外开放。与经过训练的浮点模型相比,模型量化的压缩高出 4 倍,运行速度也提高了 4 倍,从而让 RNN-T 比单核上的实时语音运行得更快。经过压缩后,模型最终缩小至 80MB。
谷歌全新的全神经元设备端 Gboard 语音识别器,刚开始仅能在使用美式英语的 Pixel 手机上使用。考虑到行业趋势,同时随着专业化硬件和算法的融合不断增强,谷歌表示,希望能够将这一技术应用到更多语言和更广泛的应用领域中去。
-
谷歌
+关注
关注
27文章
6264浏览量
112156 -
语音识别
+关注
关注
39文章
1828浏览量
116319
原文标题:语音识别如何突破延迟瓶颈?谷歌推出了基于 RNN-T 的全神经元设备端语音识别器
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
485AI语音识别模块:多路语音控制,实现安防设备语音联动
应用案例 | 40倍镜下解析小鼠脑部神经元:深视智能sCMOS相机赋能膜片钳实验高效开展


【新品发布】艾为重磅发布端侧AI高性能NPU语音芯片,打造智能语音体验新标杆

语音识别芯片有哪些(语音识别芯片AT680系列)
神经元设备和脑机接口有何渊源?

脉冲神经元模型的硬件实现
SNN加速器内部神经元数据连接方式
【「AI芯片:科技探索与AGI愿景」阅读体验】+神经形态计算、类脑芯片
绝对值光栅编码器:工业精密控制的“数字神经元”

新一代神经拟态类脑计算机“悟空”发布,神经元数量超20亿




评论