 厉害了!ICCV 2019投稿数量翻倍!
厉害了!ICCV 2019投稿数量翻倍!
昨日,ICCV 2019官方推特发布消息,公布了今年大会投稿情况:共计接收投稿4328篇,与上届相比,接收投稿数量翻倍。根据目前发布的数据,中科院和清华大学超越微软、谷歌等,投稿数量遥遥领先,分别为237篇和175篇。
厉害了!ICCV 2019投稿数量翻倍!
ICCV (国际计算机视觉大会),是计算机视觉方向的三大顶级会议之一,在世界范围内每两年召开一次。ICCV论文录用率非常低,是三大会议中公认级别最高的。
昨日,ICCV 2019官方推特发布了今年接收到的论文投稿情况:
推文链接:
https://twitter.com/ICCV19/status/1109353497856802816
今年ICCV接收的投稿数量高达4328篇,创下了其有史以来的记录!更值得注意的是,上一届ICCV的投稿数量仅是2143篇,今年翻倍!
ICCV 2019中科院、清华投稿数量遥遥领先
刚刚公布完投稿总数,ICCV 2019官方推特又公布了投稿单位分布情况:
推文链接:
https://twitter.com/ICCV19/status/1109735362757312512
新智元对其做了一下简单的整理:
中国科学院:237篇;
清华大学:175篇;
微软:103篇;
谷歌:100篇;
苏黎世联邦理工学院:99篇;
华为:91篇;
Facebook:85篇;
UC伯克利:82篇;
牛津大学:70篇;
斯坦福:58篇;
MIT:53篇;
Adobe:53篇;
首尔大学:49篇;
韩国先进科技学院:48篇;
百度:47篇;
卡内基梅隆大学:45篇;
伊利诺伊大学厄巴纳-香槟分校:39篇;
法国国立计算机及自动化研究院:36篇;
康奈尔大学:32篇;
Amazon:31篇;
maxplanckpress:29篇;
EPFL_en:25篇;
Apple:1篇。
以上是由ICCV 2019官方推特截止目前发布的各投稿单位论文投稿数量的情况。
中科院和清华大学遥遥领先微软和谷歌,投稿数量分别高达237篇和175篇。国外高校投稿数量较高的是苏黎世联邦理工学院和UC伯克利,分别为99篇和82篇。
从企业角度看,微软和谷歌投稿数量较多,分别是103篇和100篇。国内企业华为投稿最多,为91篇;其次是百度,47篇。
从目前公布的投稿数量来看,中国高校和企业在今年的ICCV可谓是大放异彩。但正如刚刚提到的,ICCV的论文录用率非常低,新智元在此也预祝中国高校和企业会有一个好的成绩!
ICCV 2017大会回顾:崛起的中国
在上一届大会(即ICCV 2017)中的各种统计数字中,可能最引人瞩目的,是中国崛起。
根据投稿作者的邮箱地址,有844篇论文(将近40%)来自中国,美国以934篇位居第一。看投稿数量,中美两国也遥遥领先。
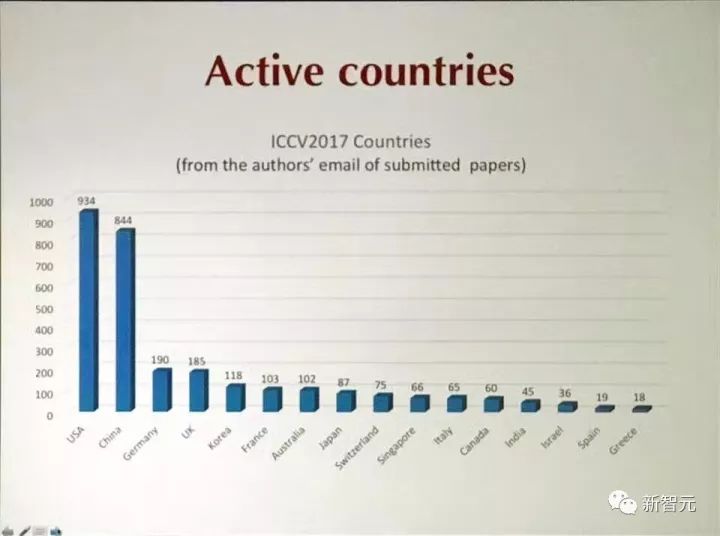
其中,投稿数量最多的机构是清华大学,超越了CMU,超越了谷歌,超越了MIT。上海交通大学和北航分别位列第八、第九。
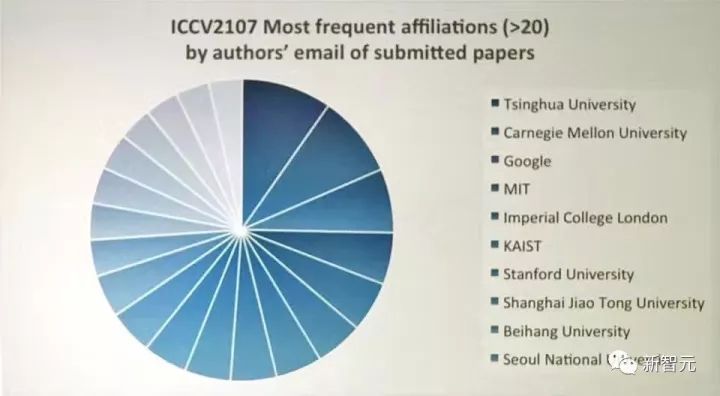
新智元粗略统计,2017年ICCV 接收论文中,有40%的第一作者都是华人。
虽然不尽是华人,我们也在上届大会主席团队中见到了熟悉的名字,上届ICCV的大会主席之一是微软亚洲研究院首席研究员池內克史。两位Workshop Chair,一位是微软的Sing Bing Kang,另一位是预定出任CVPR 2019 程序主席的上海科技大学&特拉华大学教授虞晶怡。
ICCV 2017 热词:新智元对ICCV 2017录用论文标题做了词频统计,“深度学习”、GAN、识别、检测依然是热词。
当然,在上一届ICCV中,最大的一个亮点无疑是何恺明包揽两项最佳论文。
ICCV 2017的最佳论文奖(Marr prize)颁发给了Facebook AI实验室(FAIR)何恺明等人的论文《Mask R-CNN》。
ICCV 2017最佳论文颁发给了Mask R-CNN
论文标题非常简洁,就是“Mask R-CNN”:
摘要
我们提出一个概念上简单,灵活,通用的物体实例分割框架(object instance segmentation)。我们的方法能有效检测图像中的对象,同时为每个实例生成高质量的分割掩膜(segmentation mask)。我们将该方法称为 Mask R-CNN,是在 Faster R-CNN 上的扩展,即在用于边界框识别的现有分支上添加一个并行的用于预测对象掩膜(object mask)的分支。Mask R-CNN 的训练简单,仅比 Faster R-CNN 多一点系统开销,运行速度是 5 fps。此外,Mask R-CNN 很容易推广到其他任务,例如可以用于在同一个框架中判断人的姿势。
我们在 COCO 竞赛的3个任务上都得到最佳结果,包括实例分割,边界框对象检测,以及人物关键点检测。没有使用其他技巧,Mask R-CNN 在每个任务上都优于现有的单一模型,包括优于 COCO 2016 竞赛的获胜模型。我们希望这个简单而有效的方法将成为一个可靠的基准,有助于未来的实例层面识别的研究。
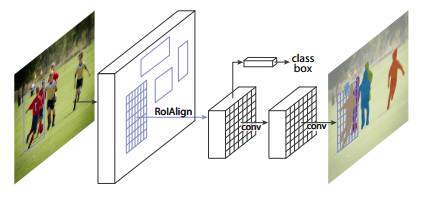
图1:用于实例分割的 Mask R-CNN 框架
Mask R-CNN 在概念上十分简单:Faster R-CNN 对每个候选物体有两个输出,即一个类标签和一个边界框偏移值。作者在 Faster R-CNN 上添加了第三个分支,即输出物体掩膜(object mask)。因此,Mask R-CNN 是一种自然而且直观的想法。但添加的 mask 输出与类输出和边界框输出不同,需要提取对象的更精细的空间布局。Mask R-CNN 的关键要素包括 pixel-to-pixel 对齐,这是 Fast/Faster R-CNN 主要缺失的一块。
最佳学生论文也出自 FAIR 团队之手,一作是 Tsung-Yi Lin。值得一提,何恺明也有参与,不愧为大神。
ICCV 2017最佳学生论文颁发给了FAIR的《密集物体检测Focal Loss》
摘要
目前,最准确的目标检测器(object detector)是基于经由 R-CNN 推广的 two-stage 方法,在这种方法中,分类器被应用到一组稀疏的候选对象位置。相比之下,应用于规则密集的可能对象位置采样时,one-stage detector 有潜力更快、更简单,但到目前为止,one-stage detector 的准确度落后于 two-stage detector。在本文中,我们探讨了出现这种情况的原因。
我们发现,在训练 dense detector 的过程中遇到的极端 foreground-background 类别失衡是造成这种情况的最主要原因。我们提出通过改变标准交叉熵损失来解决这种类别失衡(class imbalance)问题,从而降低分配给分类清晰的样本的损失的权重。我们提出一种新的损失函数:Focal Loss,将训练集中在一组稀疏的困难样本(hard example),从而避免大量简单负样本在训练的过程中淹没检测器。为了评估该损失的有效性,我们设计并训练了一个简单的密集目标检测器 RetinaNet。我们的研究结果显示,在使用 Focal Loss 的训练时,RetinaNet 能够达到 one-stage detector 的检测速度,同时在准确度上超过了当前所有 state-of-the-art 的 two-stage detector。
希望在今年的ICCV中,中国高校和企业依旧能够大放异彩!
-
微软
+关注
关注
4文章
6596浏览量
104055 -
计算机视觉
+关注
关注
8文章
1698浏览量
45993 -
深度学习
+关注
关注
73文章
5503浏览量
121154
原文标题:ICCV 2019论文投稿翻倍创纪录:共计4328篇,中科院与清华遥遥领先
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ADS8671 datasheet里写的是小信号输入-3db带宽为15KHz,是不是意味着正常信号超过10K衰减已经很厉害了?
苹果商城中国市场规模已翻倍
使用双TPA3118做双声道,负芯片无法识别同步,发热厉害怎么解决?
调试OPA541AP做的线性电流源时,OPA541AP发热很厉害怎么解决?
用运放OPA657作为前级跟随,频率增大到3M以下就开始衰减,为什么?
使用时VCA820能正常工作,但是发热比较厉害,为什么?
光纤跳线的数量怎么计算
使用OPA1632做一个模拟信号的调理电路,发热比较厉害的原因?
用放大器搭成的光电二极管放大电路,出来的波形信号不太好,这是为什么呢?
功放自激问题如何解决?
用stm32做的foc控制,电机空载抖动比较厉害的原因?
如何自制CAN调试器?
Find My查找大升级,苹果Find My可添加物品翻倍





 工商网监
工商网监
评论