 Github上放出了只需4-8块GPU就能训练的“改进版”BigGAN模型代码
Github上放出了只需4-8块GPU就能训练的“改进版”BigGAN模型代码
机器学习模型训练成本往往令普通人倍感头疼,动辄几十上百块泰坦,别说买,就是租都肉疼。近日,BigGAN作者之一在Github上放出了只需4-8块GPU就能训练的“改进版”BigGAN模型代码,可以说是穷人的福音。新模型使用PyTorch实现。
机器学习模型训练是一个耗时费力的过程,而且随着人们对模型性能要求的提升,训练模型需要的计算力正以惊人的速度增长,堆叠高性能GPU进行数据训练几乎是唯一选择,动辄几十块上百块的泰坦,搞的地主家也没有余粮。
BigGAN效果拔群,但训练成本同样让人望而却步,想自己搞?先摸摸钱包再说。
现在,BigGAN原作者之一Andrew Brock在Github上放出了只需4-8块GPU就能训练的新版BigGAN,想穷人之所想,急穷人之所急,可以说是非常亲民了。新模型使用的是PyTorch,而不是TF。
下面一起看看这个新模型的具体介绍,以下内容来自Github上的简介。
本资源包含由Andrew Brock,JeffDonahue和Karen Simonyan进行的大规模GAN高保真自然图像合成训练的BigGAN,只需4-8块 GPU的训练代码。
本段代码由Andy Brock和Alex Andonian编写。
运行环境和条件
PyTorch 1.0.1
tqdm,numpy,scipy和h5py
ImageNet训练集
首先,可以选择准备目标数据集的预处理HDF5版本,以实现更快的输入输出。之后需要计算FID所需的Inception时刻。这些都可以通过修改和运行以下代码来完成
shscripts / utils / prepare_data.sh
默认情况下,ImageNet训练集被下载到此目录中的根文件夹中,并将以128x128像素分辨率准备缓存的HDF5。
在scripts文件夹中,有多个bash脚本可以训练具有不同批量大小的BigGAN。假设您无法访问完整的TPU pod,因此通过梯度累积(在多个小批量下进行梯度平均,并且仅在N次累积后执行优化程序步骤),以此形式表示大批量。
默认情况下,可以使用launch_BigGAN_bs256x8.sh脚本训练一个全尺寸的BigGAN模型,批大小为256和8个梯度累积,总批量为2048。在8张V100上进行全精度训练(无张量),训练需要15天,期间共进行约150k次迭代。
首先需要确定设置可以支持的最大批量大小。这里提供的预训练模型是在8个V100上(每个显存16GB )上训练的,这个配置可以支持比默认使用的B1S256稍多一些的载荷。一旦确定了这一点,就应该修改脚本,使批大小乘以梯度累积的数量等于所需的总批量大小(BigGAN默认为2048)。
另外,此脚本使用--load_in_memarg,将整个(最大支持64GB)的I128.hdf5文件加载到RAM中,以加快数据的加载速度。如果没有足够的RAM做硬件支持(可能需要96GB以上的RAM),请删除此参数。
度量标准和抽样
在训练期间,脚本将输出带有训练指标和测试指标的日志,同时保存模型权重和优化程序参数的多个副本(前者保存最近的2个,后者保存5个最高得分),并且每次保存权重时将生成样本和插值。 logs文件夹包含处理这些日志的脚本,并使用MATLAB绘制结果。
训练之后,可以使用sample.py生成其他样本和插值,使用不同的截断值,批量大小,站立统计累积次数等进行测试。有关示例,请参阅sample_BigGAN_bs256x8.sh脚本。
默认情况下,所有内容都保存在weights/samples/logs/data文件夹中,这些文件夹设置与此repo位于同一文件夹中。可以使用--base_root参数将所有这些指向不同的基本文件夹,或者使用各自的参数(例如--logs_root)选择每个基础文件夹的特定位置。
此代码中包含了运行BigGAN-deep的脚本,但还没有完全训练使用它们的模型,因此用户可以视作这些模型尚未测试过。此外,我代码中还包括在CIFAR上运行模型的脚本,以及在ImageNet上运行SA-GAN(包括EMA)和SN-GAN的脚本。
SA-GAN代码假设用户配置在4张TitanX(或等同于该配置的GPU RAM),并且将以批量大小为128以及2个梯度累积运行。
关于初始度量标准的重要说明
本资源使用PyTorch内置的初始网络来计算IS和FID分数。这些分数与使用Tensorflow官方初始代码获得的分数不同,仅用于监控目的。使用--sample_npz参数在模型上运行sample.py,然后运行inception_tf13来计算实际的TensorFlow IS。请注意,需要安装TensorFlow 1.3或更早版本,因为1.4或更高版本会破坏原始的IS代码。
预训练模型
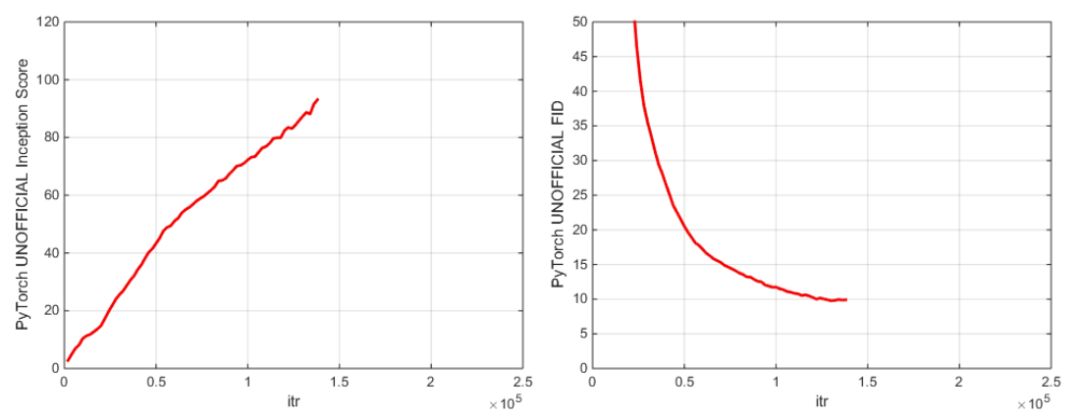
PyTorch初始分数和FID分数
我们引入了两个预训练模型检查点(使用G,D,G的EMA副本,优化器和状态dict):
主要检查点是在 128x128 ImageNet 图像上训练的 BigGAN,该模型使用 BS256 和 8 梯度累积,并在崩溃前实现,其 TF Inception Score 为 97.35 +/- 1.79,
详见:
https://drive.google.com/open?id=1nAle7FCVFZdix2—ks0r5JBkFnKw8ctW
第一个模型(100k G iters)的早期检查点,性能更高,在崩溃之前实现,可能更容易微调。
详见:
https://drive.google.com/open?id=1dmZrcVJUAWkPBGza_XgswSuT-UODXZcO。
另外,使用Places-365数据集的预训练模型即将推出。
此repo还包含用于将原始TF HubBigGAN 生成器权重的PyTorch的移植脚本。有关更多详细信息,请参阅TFHub文件夹中的脚本。
使用自己的数据集或创建新的训练函数微调模型
如果想恢复中断训练或微调预训练模型,请在运行相同的启动脚本,添加--resume参数。实验名称是由训练配置自动生成的,但如果希望使用修改后的优化器设置微调模型,可以使用--experiment_namearg进行文件名的覆盖。
要准备自己的数据集,需要将其添加到datasets.py并修改utils.py中的convenience dicts,以获得数据集的相应元数据。在prepare_data.sh中重复此过程(也可以选择生成HDF5预处理副本,并计算FID的Inception Moments)。
默认情况下,训练脚本将保存初始分数最高的前5个检查点。对于ImageNet以外的数据集,初始分数可能是一种非常差的质量标准,可以使用--which_bestFID来代替。
要使用自己的训练函数(如训练BigVAE):修改train_fns.GAN_training_function或在if config['which_train_fn'] =='GAN'之后添加新的训练函数。
本模型的主要亮点
本资源库提供完整的训练和指标日志以供参考。重现论文过程中最困难的事情之一就是检查训练早期的记录日志是否规整,特别是在训练时间长达数周的情况下。希望这将有助于未来的工作。
本资源库包括一个加速的FID计算 - 原始的scipy版本可能需要超过10分钟来计算矩阵sqrt,此版本使用加速的PyTorch版本,计算时间不到1秒。
本资源用了一种加速、低内存消耗的正交寄存器实现。默认情况下,只计算最大奇异值(谱范数),但本段代码通过 —num_G_SVs 参数支持了更多 SV 的计算。
本模型与原始BigGAN之间的主要区别
我们使用来自SA-GAN的优化器设置(G_lr= 1e-4,D_lr = 4e-4,num_D_steps= 1,与BigGAN的设置不同(G_lr = 5e-5,D_lr = 2e-5,num_D_steps = 2)。虽然这样牺牲了些许性能,但这是削减训练时间的第一步。
默认情况下,本资源不使用Cross-Replica BatchNorm(又名Synced BatchNorm)。本资源尝试的两种变体与内置的BatchNorm具有略微不同的梯度(尽管是相同的前向传递),可以满足训练要求。
梯度累积意味着需要更频繁地更新SV估计值和BN统计量(频度增加了8倍)。这意味着BN统计数据更接近于常设统计数据,而且奇异值估计往往更准确。因此,在测试模式下默认使用G来衡量指标(使用BatchNorm运行统计估算,而不是像文件中那样计算常设统计数据)。
我们仍然支持常设统计信息(具体见sample.sh脚本)。这也可能导致早期累积的梯度变得过时,但在实践中这已经不再是个问题。
目前给出的预训练模型未经过正交正则化训练。似乎增加了模型由于截断变得不可修复的可能性,但本资源库中给出特定模型似乎格外好运,没有碰到这种情况。不过,我们还是提供两个经过高度优化(快速和最小内存消耗)的正交寄存器实现,直接计算正交寄存器梯度。
Github资源地址:
https://github.com/ajbrock/BigGAN-PyTorch
-
gpu
+关注
关注
28文章
4704浏览量
128740 -
机器学习
+关注
关注
66文章
8382浏览量
132452 -
GitHub
+关注
关注
3文章
467浏览量
16389
原文标题:学生党福音!仅4个GPU打造自己的BigGAN,PyTorch代码已开源
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
PyTorch GPU 加速训练模型方法
使用PyTorch在英特尔独立显卡上训练模型
GitHub Copilot引入多模型支持
FP8模型训练中Debug优化思路
GitHub推出GitHub Models服务,赋能开发者智能选择AI模型
llm模型训练一般用什么系统
深度学习模型训练过程详解
【大语言模型:原理与工程实践】大语言模型的预训练
如何提高自动驾驶汽车感知模型的训练效率和GPU利用率
AI训练,为什么需要GPU?


FPGA在深度学习应用中或将取代GPU
在AMD GPU上如何安装和配置triton?

基于YOLOv8实现自定义姿态评估模型训练






 工商网监
工商网监
评论