 微软新研究提出一个新的多任务深度神经网络模型——MT-DNN
微软新研究提出一个新的多任务深度神经网络模型——MT-DNN
微软新研究提出一个新的多任务深度神经网络模型——MT-DNN。MT-DNN结合了BERT的优点,并在10大自然语言理解任务上超越了BERT,在多个流行的基准测试中创造了新的最先进的结果。
语言嵌入是将自然语言符号文本(如单词、短语和句子)映射到语义向量表示的过程。这是自然语言理解(NLU)深度学习方法的基础。学习对多个NLU任务通用的语言嵌入是非常必要的。
学习语言嵌入有两种流行方法,分别是语言模型预训练和多任务学习(MTL)。前者通过利用大量未标记的数据学习通用语言嵌入,但MTL可以有效地利用来自许多相关任务的有监督数据,并通过减轻对特定任务的过度拟合,从正则化效果中获益,从而使学习的嵌入在任务之间具有通用性。
最近,微软的研究人员发布了一个用于学习通用语言嵌入的多任务深度神经网络模型——MT-DNN。MT-DNN结合了MTL和BERT的语言模型预训练方法的优点,并在10个NLU任务上超越了BERT,在多个流行的NLU基准测试中创造了新的最先进的结果,包括通用语言理解评估(GLUE)、斯坦福自然语言推理(SNLI)和SciTail。
MT-DNN的架构
MT-DNN扩展了微软在2015年提出的多任务DNN模型(Multi-Task DNN),引入了谷歌AI开发的预训练双向transformer语言模型BERT。
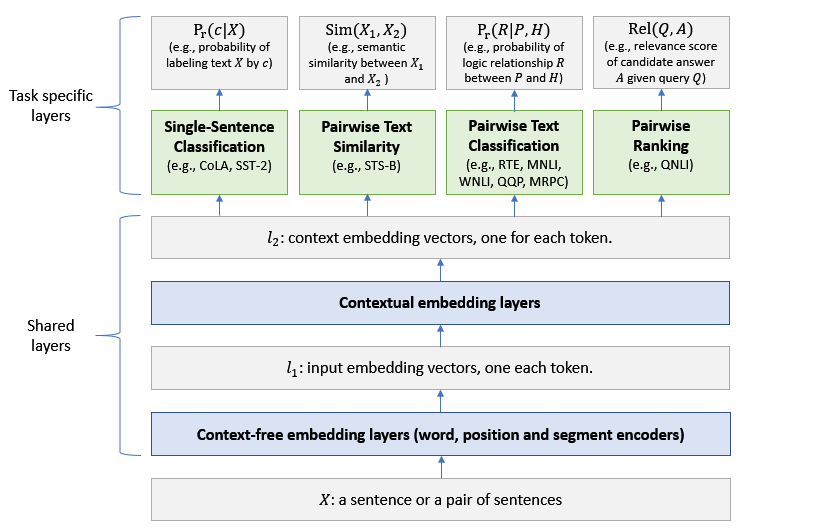
MT-DNN架构
MT-DNN模型的架构如上图所示。低层在所有任务之间共享,而顶层是特定于任务的。输入X可以是一个句子或一对句子,其中的每个单词都先被表示为一个嵌入向量序列,表示为l_1。
然后,基于transformer的编码器捕获每个单词的上下文信息,并在l_2中生成共享的上下文嵌入向量。
最后,对于每个任务,额外的 task-specific 的层生成特定于任务的表示,然后是分类、相似度评分或相关性排序所需的操作。MT-DNN使用BERT来初始化它的共享层,然后通过MTL改进它们。
领域自适应结果
评估语言嵌入的通用性的一种方法是测量嵌入适应新任务的速度,或者需要多少特定于任务的标签才能在新任务上获得不错的结果。越通用的嵌入,它需要的特定于任务的标签就越少。
MT-DNN论文的作者将MT-DNN与BERT在领域自适应(domain adaption)方面的表现进行了比较。
在域适应方面,两种模型都通过逐步增加域内数据(in-domain data)的大小来适应新的任务。
SNLI和SciTail任务的结果如下表和图所示。可以看到,在只有0.1%的域内数据(SNLI中为549个样本,SciTail中为23个样本)的条件下,MT-DNN的准确率超过80%,而BERT的准确率在50%左右,这说明MT-DNN学习的语言嵌入比BERT的更加通用。
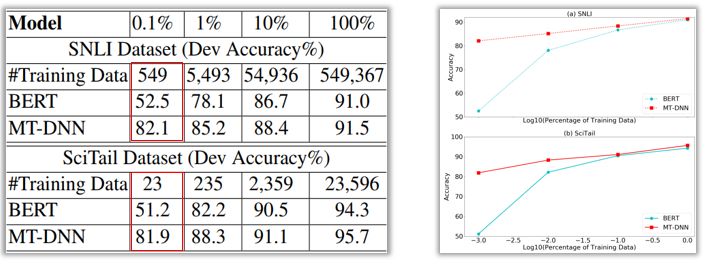
与BERT相比,MT-DNN在SNLI和SciTail数据集上的精度更高。
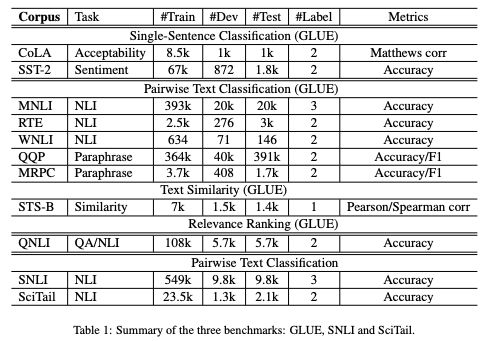
在GLUE、SNLI和SciTail 3个benchmarks上的结果
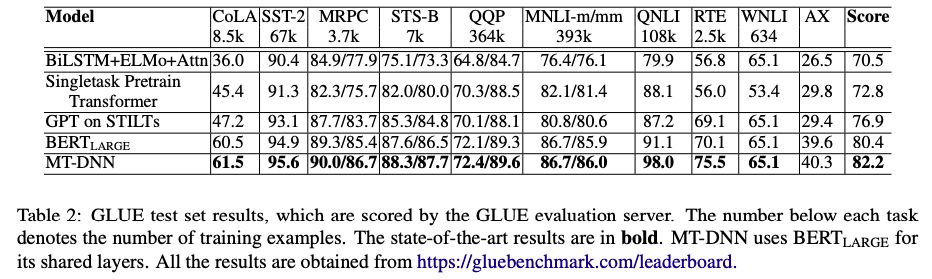
在GLUE测试集的结果,MT-DNN在10个任务上的结果均超越了BERT
模型开源
微软已经在GitHub开源MT-DNN包,其中包含了预训练的模型、源代码,并描述了如何重现MT-DNN论文中报告的结果,以及如何通过domain adaptation使预训练的MT-DNN模型适应任何新任务。
-
微软
+关注
关注
4文章
6642浏览量
104793 -
神经网络
+关注
关注
42文章
4789浏览量
101528 -
深度学习
+关注
关注
73文章
5527浏览量
121833
原文标题:10大任务超越BERT,微软提出多任务深度神经网络MT-DNN
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论