 如何选择适合的聚类算法?聚类分析时需要使用什么变量?
如何选择适合的聚类算法?聚类分析时需要使用什么变量?
聚类分析(cluster analysis)是常见的数据挖掘手段,其主要假设是数据间存在相似性。而相似性是有价值的,因此可以被用于探索数据中的特性以产生价值。常见应用包括:
用户分割:将用户划分到不同的组别中,并根据簇的特性而推送不同的广告欺诈检测:发现正常与异常的用户数据,识别其中的欺诈行为
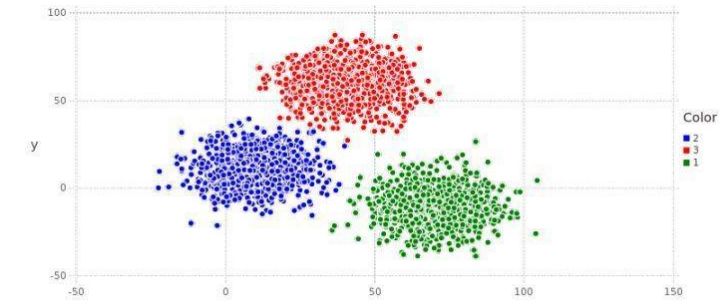
如上图,数据可以被分到红蓝绿三个不同的簇(cluster)中,每个簇应有其特有的性质。显然,聚类分析是一种无监督学习,是在缺乏标签的前提下的一种分类模型。当我们对数据进行聚类后并得到簇后,一般会单独对每个簇进行深入分析,从而得到更加细致的结果。
常见的聚类方法有不少,比如K均值(K-Means),谱聚类(Spectral Clustering),层次聚类(Hierarchical Clustering),大部分机器学习参考书上都有介绍,此处不再赘述。今天主要探讨实际聚类分析时的一些技巧。
01 如何选择适合的聚类算法
聚类算法的运算开销往往很高,所以最重要的选择标准往往是数据量。
但数据量上升到一定程度时,如大于10万条数据,那么大部分聚类算法都不能使用。最近读到的一篇对比不同算法性能随数据量的变化[1]很有意思。在作者的数据集上,当数据量超过一定程度时仅K均值和HDBSCAN可用。
我的经验也是,当数据量超过5万条数据以后,K均值可能是比较实际的算法。但值得注意的是,K均值的效果往往不是非常好,我曾在如何正确使用「K均值聚类」?中对K均值进行过总结:
因此不难看出,K均值算法最大的优点就是运行速度快,能够处理的数据量大,且易于理解。但缺点也很明显,就是算法性能有限,在高维上可能不是最佳选项。
一个比较粗浅的结论是,在数据量不大时,可以优先尝试其他算法。当数据量过大时,可以试试HDBSCAN。仅当数据量巨大,且无法降维或者降低数量时,再尝试使用K均值。
一个显著的问题信号是,如果多次运行K均值的结果都有很大差异,那么有很高的概率K均值不适合当前数据,要对结果谨慎的分析。
另一种替代方法是对原始数据进行多次随机采样得到多个小样本,并在小样本上聚类,并融合结果。比如原始数据是100万,那么从中随机采样出100个数据量等于1万的样本,并在100个小数据集上用更为复杂的算法进行聚类,并最终融合结果。
此处需要注意几点问题:
随机采样的样本大小很重要,也不能过小。需要足够有代表性,即小样本依然可以代表总体的数据分布。如果最终需要划分很多个簇,那么要非常小心,因为小样本可能无法体现体量很小的簇。
在融合过程中要关注样本上的聚类结果是否稳定,随机性是否过大。要特别注意不同样本上的簇标号是否统一,如何证明不同样本上的簇结果是一致的。
因此我的经验是,当数据量非常大时,可以优先试试K均值聚类,得到初步的结果。如果效果不好,再通过随机采样的方法构建更多小样本,手动融合模型提升聚类结果,进一步优化模型。
02 聚类分析时需要使用什么变量?
这个是一个非常难回答的问题,而且充满了迷惑性,不少人都做错了。举个简单的例子,我们现在有很多客户的商品购买信息,以及他们的个人信息,是否该用购买信息+个人信息来进行聚类呢?
未必,我们需要首先回答最重要的一个问题:我们要解决什么问题?
如果我们用个人信息,如性别、年龄进行聚类,那么结果会被这些变量所影响,而变成了对性别和年龄的聚类。所以我们应该先问自己,“客户购物习惯”更重要还是“客户的个人信息”更重要?
如果我们最在意的是客户怎么花钱,以及购物特征,那就应该完全排除客户的个人信息(如年龄性别家庭住址),仅使用购买相关的数据进行聚类。这样的聚类结果才是完全由购买情况所驱动的,而不会受到用户个人信息的影响。
那该如何更好的利用客户的个人信息呢?这个应该被用在聚类之后。当我们得到聚类结果后,可以对每个簇进行分析,分析簇中用户的个人情况,比如高净值客户的平均年龄、居住区域、开什么车。无关变量不应该作为输入,而应该得到聚类结果后作为分析变量。
一般情况下,我们先要问自己,这个项目在意的是什么?很多时候个人信息被错误的使用在了聚类当中,聚类结果完全由个人信息所决定(比如男性和女性被分到了两个簇中),对于商业决策的意义就不大了。一般来说,应该由商业数据驱动,得到聚类结果后再对每个簇中的用户个人信息进行整合分析。
但值得注意的是,这个方法不是绝对的。在聚类中有时候也会适当引入个人信息,也可以通过调整不同变量的权重来调整每个变量的影响。
03 如何分析变量的重要性?
首先变量选择是主观的,完全依赖于建模者对于问题的理解,而且往往都是想到什么用什么。因为聚类是无监督学习,因此很难评估变量的重要性。介绍两种思考方法:
考虑变量的内在变化度与变量间的关联性:一个变量本身方差很小,那么不易对聚类起到很大的影响。如果变量间的相关性很高,那么高相关性间的变量应该被合并处理。直接采用算法来对变量重要性进行排序:比如 Principal Feature Analysis [2],网上有现成的代码 [3]。
另一个鸡生蛋蛋生鸡的问题是,如果我用算法找到了重要特征,那么仅用重要特征建模可以吗?这个依然不好说,我觉得最需要去除的是高相关性的变量,因为很多聚类算法无法识别高相关性,会重复计算高相关性特征,并夸大了其影响,比如K均值。
04 如何证明聚类的结果有意义?如何决定簇的数量?
聚类分析是无监督学习,因此没有具体的标准来证明结果是对的或者错的。一般的判断方法无外乎三种:
人为验证聚类结果符合商业逻辑。比如我们对彩票客户进行聚类,最终得到4个簇,其中分为:
“高购买力忠实客户”:花了很多钱的忠实客户,他们可能常年购买且花费不菲
“普通忠实客户”:常年购买,但每次的购买额度都不大
“刺激性消费单次购买者”:只购买了几次,但是一掷千金
“谨慎的单次购买者”:只购买了几次,每次买的都很谨慎
我们可以用通过商业逻辑来解释聚类结果,结果应该大致符合行业专家的看法。最终你的聚类结果需要回归到现实的商业逻辑上去,这样才有意义。
预先设定一些评估标准,比如簇内的紧凑度和簇间的疏离度,或者定义好的函数如Silhouette Coefficient。一般来说设定一个好的评估标准并不容易,所以不能死板的单纯依赖评估函数。
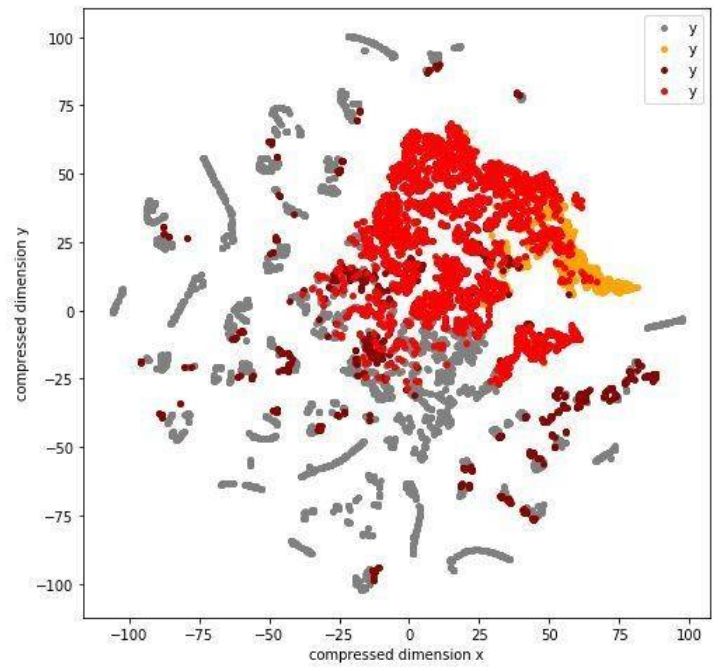
通过可视化来证明不同簇之间的差异性。因为我们一般有超过两个变量,所以会需要先对数据进行压缩,比如很多流形学习的方法多维缩放(multi-dimensional scaling)。
以下图为例,我把数据分成了四个簇,并用T-SNE压缩到二维并绘制出来。从直观上看,不同簇间有了一定区别。类似的可视化也可以在变量间两两绘制,或者直接画pairplot。
所以如何定义一个好的聚类结果?我认为应该符合几个基本标准:
符合商业常识,大致方向上可以被领域专家所验证可视化后有一定的区别,而并非完全随机且交织在一起如果有预先设定的评估函数,评估结果较为优秀
因此决定簇的数量也应该遵循这个逻辑,适当的数量应该满足以上三点条件。如果某个簇的数量过大或者过小,那可以考虑分裂或者合并簇。
当然,聚类作为无监督学习,有很多模棱两可的地方。但应时时牢记的是,机器学习模型应服务商业决策,脱离问题空谈模型是没有意义的。
-
数据挖掘
+关注
关注
1文章
406浏览量
24201 -
聚类算法
+关注
关注
2文章
118浏览量
12120 -
聚类分析
+关注
关注
0文章
16浏览量
7407
原文标题:【集客经营】干货:如何对用户进行「聚类分析」?
文章出处:【微信号:xiacoinfo,微信公众号:资治通信】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于PLSA模型的用户兴趣聚类算法研究
基于C均值聚类的定位算法
聚类分析的简单案例
浅谈Matlab中的聚类分析 Matlab聚类程序的设计
如何使用K-Means聚类算法改进的特征加权算法详细资料概述
如何在python中安装和使用顶级聚类算法?
10种聚类算法和Python代码3
10种聚类算法和Python代码4





 工商网监
工商网监
评论