 SVD的数据压缩原理
SVD的数据压缩原理

前言
奇异值分解(SVD)在降维,数据压缩,推荐系统等有广泛的应用,任何矩阵都可以进行奇异值分解,本文通过正交变换不改变基向量间的夹角循序渐进的推导SVD算法,以及用协方差含义去理解行降维和列降维,最后介绍了SVD的数据压缩原理 。
1. 正交变换
正交变换公式:
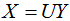
上式表示:X是Y的正交变换,其中U是正交矩阵,X和Y为列向量 。
下面用一个例子说明正交变换的含义:
假设有两个单位列向量a和b,两向量的夹角为θ,如下图:
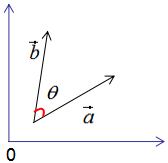
现对向量a,b进行正交变换:
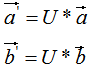
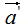 ,
,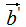 的模:
的模:
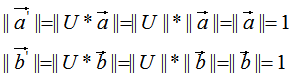
由上式可知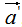 和
和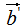 的模都为1。
的模都为1。
 和
和 的内积:
的内积:
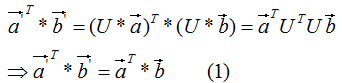
由上式可知,正交变换前后的内积相等。
 和
和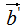 的夹角
的夹角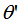 :
:
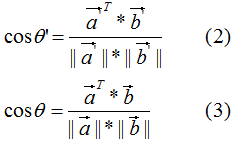
比较(2)式和(3)式得:正交变换前后的夹角相等,即: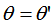
因此,正交变换的性质可用下图来表示:
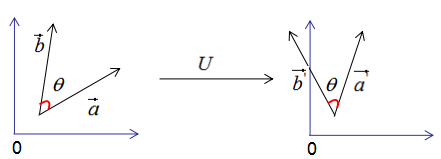
正交变换的两个重要性质:
1)正交变换不改变向量的模。
2)正交变换不改变向量的夹角。
如果向量 和
和 是基向量,那么正交变换的结果如下图:
是基向量,那么正交变换的结果如下图:
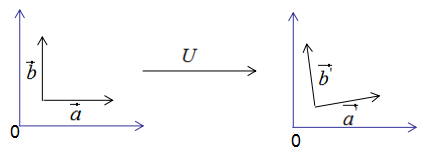
上图可以得到重要结论:基向量正交变换后的结果仍是基向量。基向量是表示向量最简洁的方法,向量在基向量的投影就是所在基向量的坐标,我们通过这种思想去理解特征值分解和推导SVD分解。
2. 特征值分解的含义
对称方阵A的特征值分解为:
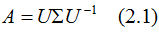
其中U是正交矩阵,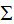 是对角矩阵。
是对角矩阵。
为了可视化特征值分解,假设A是2×2的对称矩阵,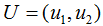 ,
,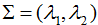 。(2.1)式展开为:
。(2.1)式展开为:
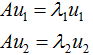
用图形表示为:
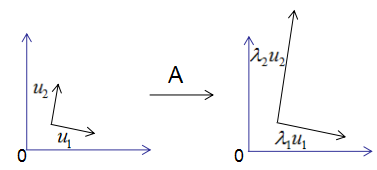
由上图可知,矩阵A没有旋转特征向量,它只是对特征向量进行了拉伸或缩短(取决于特征值的大小),因此,对称矩阵对其特征向量(基向量)的变换仍然是基向量(单位化)。
特征向量和特征值的几何意义:若向量经过矩阵变换后保持方向不变,只是进行长度上的伸缩,那么该向量是矩阵的特征向量,伸缩倍数是特征值。
3. SVD分解推导
我们考虑了当基向量是对称矩阵的特征向量时,矩阵变换后仍是基向量,但是,我们在实际项目中遇到的大都是行和列不相等的矩阵,如统计每个学生的科目乘积,行数为学生个数,列数为科目数,这种形成的矩阵很难是方阵,因此SVD分解是更普遍的矩阵分解方法。
先回顾一下正交变换的思想:基向量正交变换后的结果仍是基向量。
我们用正交变换的思想来推导SVD分解:
假设A是M*N的矩阵,秩为K,Rank(A)=k。
存在一组正交基V:
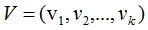
矩阵对其变换后仍是正交基,记为U:
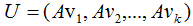
由正交基定义,得:
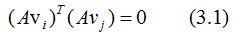
上式展开:
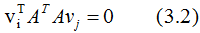

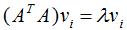
∴ (3.2)式得:
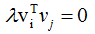
即假设成立 。
图形表示如下:
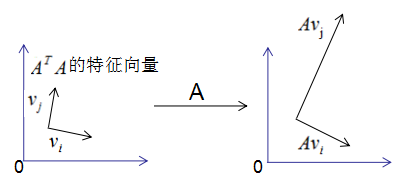
正交向量的模:
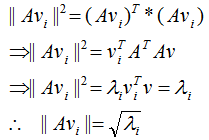
单位化正交向量,得:
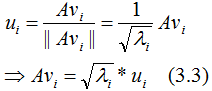
结论:当基向量是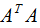 。
。
用矩阵的形式表示(3.3)式:
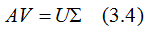
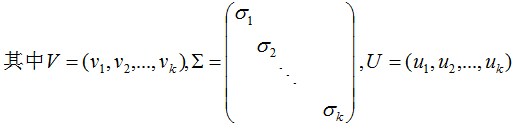
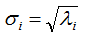
V是N*K矩阵,U是M*K矩阵,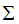 是M*K的矩阵,需要扩展成方阵形式:
是M*K的矩阵,需要扩展成方阵形式:
将正交基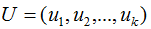 扩展
扩展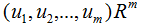 空间的正交基,即U是M*M方阵 。
空间的正交基,即U是M*M方阵 。
将正交基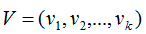 扩展成
扩展成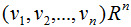 空间的正交基,其中
空间的正交基,其中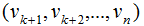 是矩阵A的零空间,即:
是矩阵A的零空间,即:
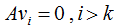
对应的特征值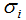 =0,
=0,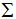 是M*N对角矩阵,V是N*N方阵
是M*N对角矩阵,V是N*N方阵
因此(3.4)式写成向量形式为:
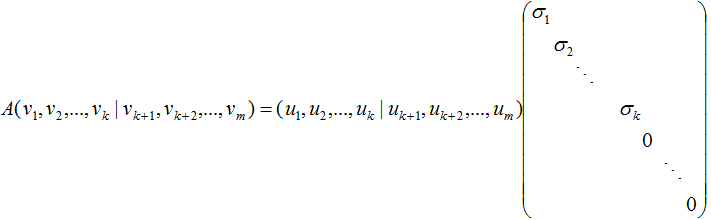
得:
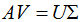
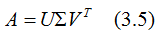
(3.5)式写成向量形式:
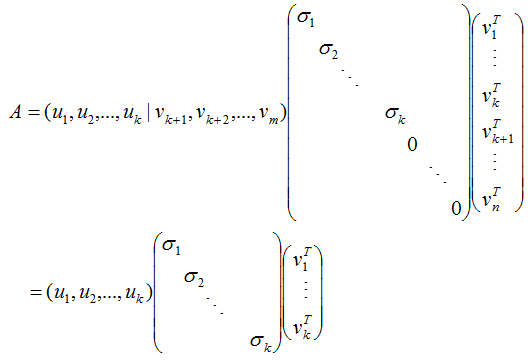
令:
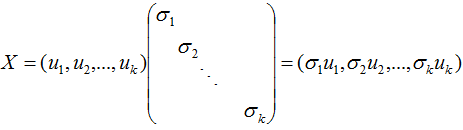
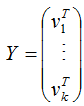
则:
A = XY
因为X和Y分别是列满秩和行满秩,所以上式是A的满秩分解。
(3.5)式的奇异矩阵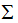 的值
的值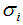 是
是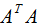 特征值的平方根,下面推导奇异值分解的U和V:
特征值的平方根,下面推导奇异值分解的U和V:
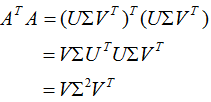
即V是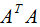 的特征向量构成的矩阵,称为右奇异矩阵。
的特征向量构成的矩阵,称为右奇异矩阵。
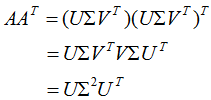
即U是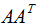 的特征向量构成的矩阵,称为左奇异矩阵 。
的特征向量构成的矩阵,称为左奇异矩阵 。
小结:矩阵A的奇异值分解:
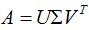
其中U是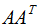 的特征向量构成的矩阵,V是
的特征向量构成的矩阵,V是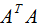 的特征向量构成的矩阵,奇异值矩阵
的特征向量构成的矩阵,奇异值矩阵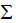 的值是
的值是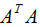 特征值的平方根 。
特征值的平方根 。
3. 奇异值分解的例子
本节用一个简单的例子来说明矩阵是如何进行奇异值分解的。矩阵A定义为:
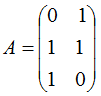
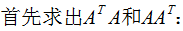
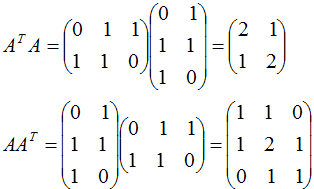
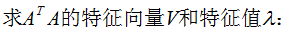

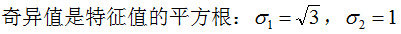
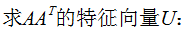
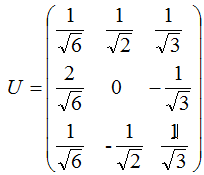
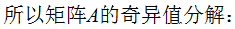
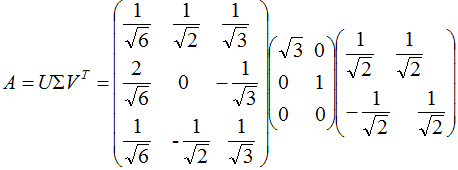
4. 行降维和列降维
本节通过协方差的角度去理解行降维和列降维,首先探讨下协方差的含义:
单个变量用方差描述,无偏方差公式:
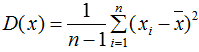

两个变量用协方差描述,协方差公式:
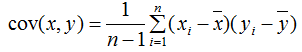
多个变量(如三个变量)之间的关系可以用协方差矩阵描述:
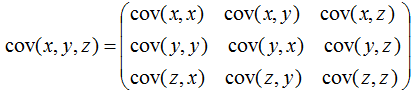
相关系数公式:
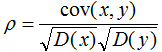
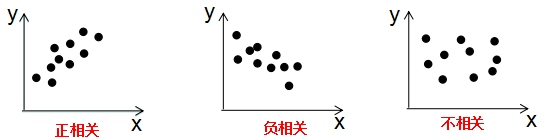
由上式可知,协方差是描述变量间的相关关系程度:
1)协方差cov(x,y) > 0时,变量x与y正相关;
2)协方差cov(x,y)<0时,变量x与y负相关;
3)协方差cov(x,y)=0时,变量x与y不相关;
变量与协方差关系的定性分析图:
现在开始讨论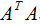 和
和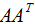 的含义:
的含义:
假设数据集是n维的,共有m个数据,每一行表示一例数据,即:
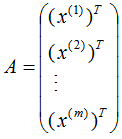
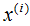 表示第i个样本,
表示第i个样本,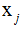
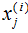 表示第i个样本的第j维特征 。
表示第i个样本的第j维特征 。
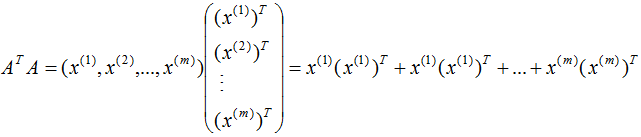
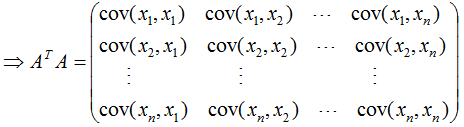
由上式可知,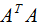 是描述各特征间相关关系的矩阵,所以
是描述各特征间相关关系的矩阵,所以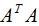 的正交基V是以数据集的特征空间进行展开的。
的正交基V是以数据集的特征空间进行展开的。
数据集A在特征空间展开为:
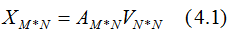
由上一篇文章可知,特征值表示了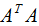 在相应特征向量的信息分量。特征值越大,包含矩阵
在相应特征向量的信息分量。特征值越大,包含矩阵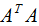 的信息分量亦越大。
的信息分量亦越大。
若我们选择前r个特征值来表示原始数据集,数据集A在特征空间展开为:
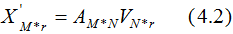
(4.2)式对列进行了降维,即右奇异矩阵V可以用于列数的压缩,与PCA降维算法一致。
行降维:
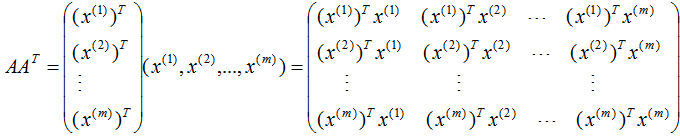
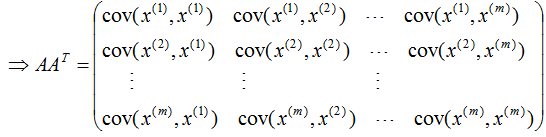
由上式可知: 是描述样本数据间相关关系的矩阵,因此,左奇异矩阵U是以样本空间进行展开,原理与列降维一致,这里不详细介绍了 。
是描述样本数据间相关关系的矩阵,因此,左奇异矩阵U是以样本空间进行展开,原理与列降维一致,这里不详细介绍了 。
若我们选择前r个特征值来表示原始数据集,数据集A在样本空间展开为:
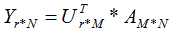
因此,上式实现了行降维,即左奇异矩阵可以用于行数的压缩。
5. 数据压缩
本节介绍两种数据压缩方法:满秩分解和近似分解
矩阵A的秩为k,A的满秩分解:
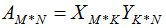
满秩分解图形如下:
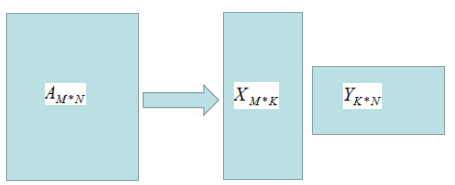
由上图可知,存储X和Y的矩阵比存储A矩阵占用的空间小,因此满秩分解起到了数据压缩作用。
若对数据再次进行压缩,需要用到矩阵的近似分解。
矩阵A的奇异值分解:
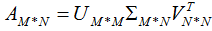
若我们选择前r个特征值近似矩阵A,得:
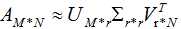
如下图:
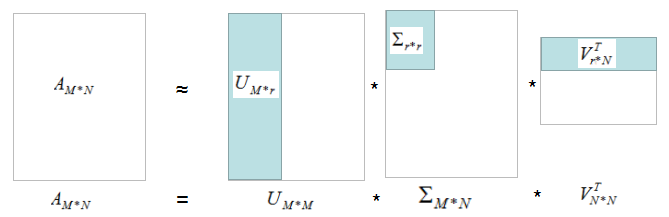
我们用灰色部分的三个小矩阵近似表示矩阵A,存储空间大大的降低了。
6. SVD总结
任何矩阵都能进行SVD分解,SVD可以用于行降维和列降维,SVD在数据压缩、推荐系统和语义分析有广泛的应用,SVD与PCA的缺点一样,分解出的矩阵解释性不强 。
-
矩阵
+关注
关注
1文章
450浏览量
36277 -
向量
+关注
关注
0文章
55浏览量
12068 -
SVD
+关注
关注
0文章
21浏览量
12493
原文标题:奇异值分解(SVD)原理总结
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【TL6748 DSP申请】井下数据压缩技术
数据压缩技术

JPEG2000数据压缩的FPGA实现
基于运动状态改变的GPS轨迹数据压缩算法
数据压缩的重要性
数据压缩算法计算步骤及过程
有趣!史记:数据压缩算法列传
高性能无损数据压缩FPGA IP,LZO无损数据压缩IP



评论