 自动机器学习的研究动机
自动机器学习的研究动机

本文作者第四范式涂威威,该文首发于《中国计算机学会通讯》第15卷第3期
自动机器学习的研究动机
机器学习在推荐系统、在线广告、金融市场分析、计算机视觉、语言学、生物信息学等诸多领域都取得了成功,在这些成功的应用范例中,也少不了人类专家的参与。Google、 Facebook、百度、阿里巴巴、腾讯等科技公司依靠其顶尖的机器学习专家团队来支撑机器学习在企业内部的各种应用,各类科研机构也在花费大量经费,维护着机器学习科学家团队。然而,对于很多传统企业、中小型企业和一般的科研机构,就很难组建出这样的机器学习专家团队,其原因是机器学习专家的缺口太大,人才短缺,人才抢夺激烈,专家团队的管理成本高昂和专家经验不可复制,等等。
为了机器学习能为更多的企业赋能,在更加广泛的场景得到应用,有没有低门槛甚至零门槛的机器学习方法,让更多的人可以在很少甚至几乎没有专业知识的情况下轻松使用,并减少机器学习应用落地对专家人才的依赖?自动机器学习(Automatic/Automated Machine Learning, AutoML)应运而生。其研究目的就是为了使机器学习过程自动化,减少、甚至完全规避人类专家在这个过程中的参与度。
理论出发点
设计机器学习算法是一件困难重重的事情,能否找到一种通用的机器学习算法来解决所有的机器学习问题呢?这个问题在 20 多年前就被解答过,对于所有可能的问题,可以证明的是,如果所有问题同等重要,所有的算法,包括完全随机的算法,它们的期望性能是一样的,所有的算法没有优劣之分,这是著名的没有免费的午餐 (No Free Lunch, NFL)定理的一个不太严谨的直观阐述。
这个定理意味着寻求一种完全通用的机器学习算法是行不通的。于是,研究人员就开始针对不同的问题展开对应的机器学习研究,这导致了机器学习技术广泛应用不可复制的问题。在解决某个特例问题的机器学习算法和针对所有问题完全通用的机器学习算法之间,有一种可能性是存在可以解决某一类而不只是某一个特例的相对通用的机器学习算法。自动机器学习就是从这样的理论考虑出发,试图去寻找更加通用的机器学习算法。
目前自动机器学习研究的主要场景
静态闭环自动机器学习
静态闭环自动机器学习考虑的是静态机器学习问题,即给定固定的训练集,不利用外部知识,寻找在测试集上期望表现最好的机器学习模型。经典的机器学习流程包括数据预处理、特征处理和模型训练。自动机器学习在这三个流程中都有广泛的研究 :
(1) 数据预处理中,研究数据的自动清洗、样本的自动选择、数据的自动增强、数据类型的自动推断等,以达到理解原始数据和提升数据质量的目标。
(2) 对特征处理方法的研究主要包括自动特征生成和自动特征选择。自动特征生成的研究包括单特征变换、多特征组合、深度特征生成、特征学习等。自动特征选择一般会配合自动特征生成使用,先自动生成特征,再进行自动特征选择,对于复杂的特征处理,一般两者交替迭代进行。
(3) 模型训练的研究一般包括自动算法选择和自动算法配置。自动算法试图从广泛的机器学习算法中选择适合问题的某一个或者某几个算法,这些算法又有很多的超参数需要配置,自动算法配置则研究如何进行超参数选择配置,比如如何配置神经网络结构,实际应用中这两者也会配合使用。
外部知识辅助的静态自动机器学习
外部知识辅助的静态自动机器学习试图借鉴人类专家选择数据处理方法、特征处理方法、模型训练算法等的方式进行自动机器学习。人类专家会从以往处理过的机器学习问题中积累经验,并将此推广到之后的机器学习问题中。
动态环境的自动机器学习
动态环境下的自动机器学习研究试图解决的是数据不断积累、概念发生漂移时的问题。
核心技术
自动机器学习的研究核心是如何更好地对数据处理方法、特征处理方法、模型训练方法等基础部件进行选择、组合以及优化,以使学习到的模型的期望性能达到最优(见图 1)。
目前该项研究主要面临三个难点 :
(1) 超参配置与效果之间的函数无法显式表达,属于“黑盒”函数;
(2) 搜索空间巨大,可能的处理方法和组合是指数级,同时不同处理方法拥有各自的超参数,当特征维度超过 20 时,其多目特征组合可能的搜索空间都将远超围棋可能的状态空间 ;
(3) 函数值的每次计算大多涉及数据预处理、特征处理、模型训练的全流程,函数值的计算代价极其昂贵。为了解决这些问题,采用的核心技术是基础搜索方法、基于采样的方法和基于梯度的方法。
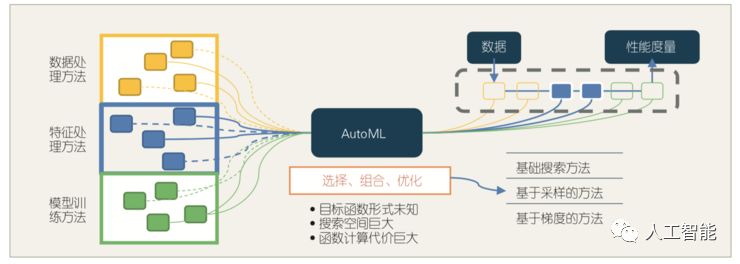
图1 自动机器学习的框架
基础搜索方法
搜索方法中最常见的是格搜索方法。该方法通过遍历多维参数组合构成了网格寻求最优化,容易实现,应用广泛,但是,搜索复杂度随参数维度呈指数增长,并且会将搜索浪费在不太重要的参数维度上。随机搜索方法则是对参数空间进行随机采样,各个维度相互独立,克服了维度灾难和浪费资源搜索的问题。在实际应用中,随机搜索方法往往表现得比格搜索要优秀。
基于采样的方法
基于采样的方法是被研究得最多的方法,大多也是具有理论基础的方法,往往比基础搜索方法表现更优。这类方法一般会生成一个或者多个对样本空间的采样点,之后再对这些采样点进行评估,根据评估的反馈结果进行下一步采样,最后寻找到相对较优的参数点(见图 2)。基于采样的方法分为以下四类:
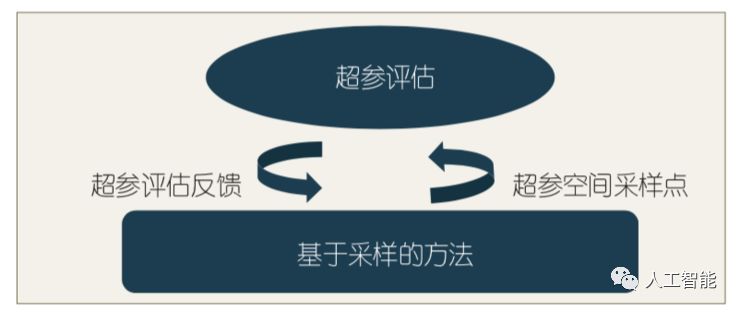
图2 基于采样的方法
基于模型的零阶优化方法
该方法试图建立关于配置参数和最终效果的模型,并依据模型来寻求最优化。这类方法一般先基于已经采样到的点的效果评估建立模型,然后基于学习到的模型采用某种采样策略来生成下一个或者下一组采样点,根据新的采样点得到的效果进一步更新模型,再采样迭代,如此寻求对黑盒函数的最优化。由于待优化的函数是“黑盒”函数,在求解过程中只能获得函数值而不能直接计算函数梯度,因此也被称为零阶优化方法(零阶是相对于传统计算一阶或者二阶梯度的优化方法)或者非梯度方法。
这类方法有两个主要的关注点 : 模型和采样策略。构建的模型一般用来预测配置参数对应的效果。由于采样依据的模型仅仅是依据之前采样得到的点的反馈学习,对函数空间未探索区域的估计一般是不太准确的,采样策略需要在函数最优化和空间探索之间做出权衡,即在开发利用 (exploitation) 和探索 (exploration) 之间做出权衡,简称 E&E。
贝叶斯优化是一种基于概率模型的方法,一般采用高斯过程、贝叶斯神经网络、随机森林等作为模型,然后采用提升概率、提升期望、交叉熵、GP-UCB 等作为采样策略,这些策略都在显式或者隐式地进行 E&E。最常见的是基于高斯过程的贝叶斯优化方法,这类方法在参数维度较低、采样点较少时表现较优,但是在高维、采样点较多时就很难被使用,因此有学者尝试使用贝叶斯神经网络解决这样的问题。
基于分类方法的随机坐标收缩方法 (RAndom COordinate Shrinking, RACOS) 和基于随机坐标收缩分类模型来进行基于模型的零阶优化,有效地解决了贝叶斯优化方法的计算复杂度高、参数类型受限的问题,它一般采用最简单的 ε-greedy 方法来进行 E&E。随机坐标收缩方法被证明在高维度场景下显著优于基于高斯过程的贝叶斯优化方法。
局部搜索方法
局部搜索方法一般定义某种判定邻域的方式, 从一个初始解出发,搜索解的邻域,不断探索更优的邻域解来完成对解空间的寻优。最常见的方法有爬山法、局部集束搜索等。局部搜索简单、灵活并易于实现,但容易陷入局部最优,且解的质量与初始解和邻域的结构密切相关。
启发式方法
启发式方法主要是模拟生物现象,或者从一些自然现象中获得启发来进行优化,最典型的就是基于演化计算方法。这类方法由于很少有理论依据,实际工作中很难对方法的效果进行分析。
基于强化学习的方法
这类方法能够发现一些新的神经网络结构,并被验证具有一定的迁移能力,但是由于强化学习自身的学习算法研究尚未成熟,其优化效率相对低下。
基于梯度的方法
由于对优化部件以及超参数的可微性要求较高,并且计算复杂度也高,因此,直接对优化目标进行梯度求解的方法很少使用。
研究热点
自动机器学习的研究热点是效率和泛化性。解决自动机器学习的效率问题是自动机器学习技术落地的关键之一。效率优化包括六类 :
(1) 混合目标优化,将参数点的评估代价也作为优化目标的一部分,在计算代价和效果之间做权衡。
(2) 同步并行化和异步并行化。
(3) 提前停止迭代,在训练早期就剔除一些表现不太好的参数,节省计算资源,比如最经典的逐次减半策略,每过一段时间都剔除其中一半不好的参数,极大地节省了计算资源(见图 3)。
(4) 对模型训练进行热启动,复用类似参数的训练结果,降低超参数的评估代价。
(5) 对数据进行采样,采用小样本上的参数搜索来代替全样本的参数搜索,由于小样本和全样本最优参数之间可能存在着差异,有一些研究人员试图学习小样本和全样本之间的关系来进行多保真度的自动机器学习(见图 4)。
(6) 将超参数搜索和机器学习过程结合起来,进一步提升效率和效果,比如基于种群的方法。
机器学习关注的核心是泛化性,自动机器学习的目的也是为了提升最终学习到的模型的泛化性。
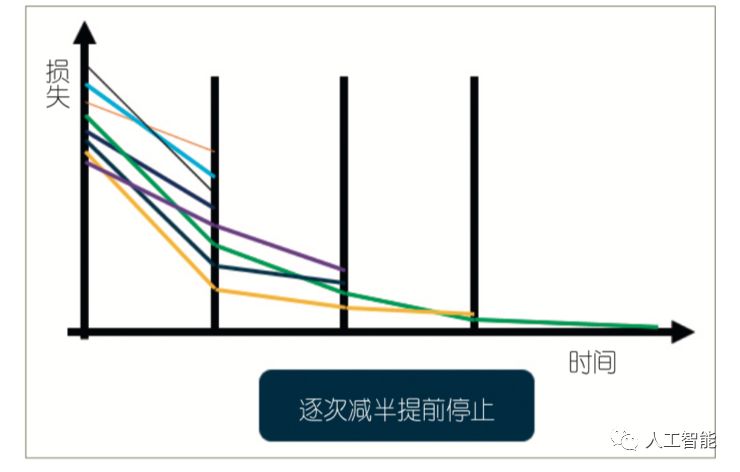
图3 逐次减半策略
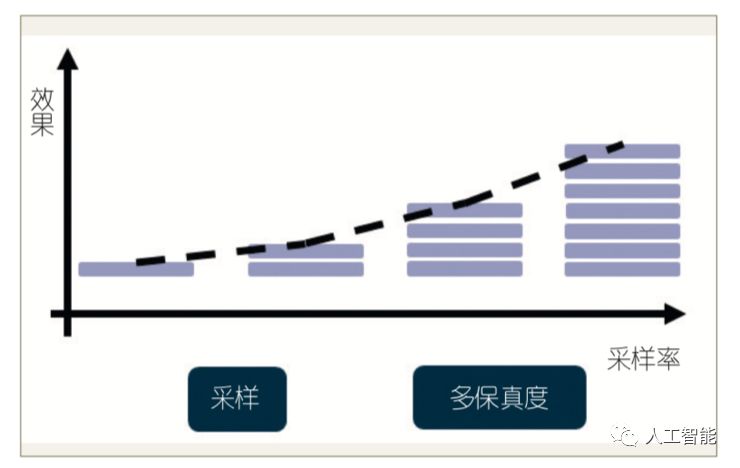
图4 多保真度的自动机器学习
如何判断自动机器学习是否提升了泛化性,一般采用切分训练集和验证集的方式进行估计。为了进一步降低过拟合到验证集的风险,有一些研究关注如何对模型的泛化效果进行更合理的估计。除此之外,由于自动机器学习往往伴随着很多次不同参数的模型学习,与最终只选择一个“最优”的模型不同,选择其中一些模型进行集成学习也是一种提升泛化性的方式。越来越多的工作混合多种效率优化和提升泛化性的策略对自动机器学习算法进行优化。
落地应用
来自不同数据之间解决问题手段的可迁移性 / 可复制性为自动机器学习的落地增加了难度。解决不同问题的手段相似性或者可迁移性 / 可复制性越高,自动化越容易,反之越难。目前自动机器学习落地的应用场景主要有图像数据和表数据。
图像数据
深度学习取得成功的领域来自图像。深度学习的核心在于“自动”学习层次化特征。以前的图像分析需要人工来做,要从原始像素中提取非常多的特征,而深度学习很好地解决了这个问题。深度学习使得特征可学习,同时将人工特征设计转变成了人工神经网络结构设计。对于这类数据,自动机器学习研究的核心是使图像领域的神经网络结构设计自动化。图像数据之间的相似性较大,原始输入都是像素,问题解决方案的可迁移性和可复用性也大,因此,自动机器学习在图像数据上的落地相对容易。
表数据
表数据是抽象数据,不同的表数据之间没有很强的相似性,不同表数据各列的含义千差万别,表数据还与实际业务密切相关,需要解决时序性、概念漂移、噪声等问题,因此自动机器学习在表数据上落地的难度较大,仅仅是自动神经网络结构设计是远远不够的。目前研究的热点还包括如何将分布在多个表中的数据自动转化成最终机器学习所需要的单个表数据。
未来展望
算法方向
在自动机器学习算法方面,未来的工作如果能在 5 个方向上取得突破,将会有较大的价值。
1. 效率提升。效率可从时间复杂度和样本复杂度两方面考量。在给定的计算资源下,更高的效率在一定程度上决定了自动机器学习的可行性,意味着可以进行更多探索,还可能会带来更好的效果。另外,获取高质量有标记的样本往往是非常昂贵的,因此样本复杂度也是影响机器学习落地的关键因素之一。在外部知识辅助的自动机器学习中引入学件 (学件 = 模型 + 模型的规约),利用迁移学习,是未来有效降低样本复杂度的可能方向 (见图 5)。
图5 迁移学习与学件
2. 泛化性。目前自动机器学习在泛化性上考虑较少,泛化性是机器学习最重要的研究方向,未来需要加强。
3. 全流程的优化。与目前大部分自动机器学习只研究机器学习的某一个阶段(比如自动特征、自动算法选择、自动算法配置)不同,实际应用需要全流程的自动机器学习技术。
4. 面对开放世界。现实世界不是一成不变的, 自动机器学习技术需要面对开放的世界,解决数据的时序性、概念漂移、噪声等问题。
5. 安全性和可解释性。为使自动机器学习具有安全性,需要解决攻击应对、噪声抵抗、隐私保护等问题。如果自动机器学习系统被部署到实际系统中与人交互,则需要更好的可解释性。
理论方向
在自动机器学习理论方面,目前研究的甚少,对自动机器学习的泛化能力及适用性也知之甚少。因而,我们一方面要回答目前自动机器学习算法的适用性和泛化能力,另一方面也要回答哪些问题类存在通用的机器学习算法上和更广泛问题空间上的自动机器学习算法的可行性。
-
神经网络
+关注
关注
42文章
4844浏览量
108212 -
核心技术
+关注
关注
4文章
625浏览量
20531 -
机器学习
+关注
关注
67文章
8567浏览量
137268
原文标题:第四范式涂威威:AutoML 回顾与展望
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NFA→FA→GFA自动机转换算法
加性细胞自动机的同构性分析
用于信息加密的分子自动机的编码研究
[自动机与自动线].李绍炎.扫描版
自动机械设计
极小模糊多重集有限自动机及算法
基于统计的AC自动机空间优化
量化自动机器人是什么
自动机终结字查找算法实现优化综述





评论