 人工合成 DNA存储,液体转移DNA成难点
人工合成 DNA存储,液体转移DNA成难点
现代存储技术已经无法满足字节的海啸式增长,但是大自然也许已为这个难题提供了解决方案。
比如,DNA。
上个月,来自微软和华盛顿大学的研究人员宣布:以人工合成为DNA为载体的存储和读取数据的全自动系统研制成功,迈出了该技术从研究实验室走进商业应用关键的一步。
在一次概念验证测试中,该研究团队成功地在人工合成的DNA片段中编码了“hello”一词,并使用全自动端到端系统将其转换回数字数据。
其实早在2016年7月,微软和华盛顿大学的研究人员就已经宣布,利用DNA存储技术完成了约200MB数据的保存,相对于当时最大存储为739KB的EBI文件来说已经实现了信息存储了飞跃。
该研究声称,如果信息封装密度像大肠杆菌的基因那么高,全世界的存储需求可用1千克的DNA来满足。
这一结果发布在当年9月份的《自然(Nature)》杂志上。

两年多的时间过去了,微软和华盛顿大学的研究人员又取得了新突破:不仅存储量翻了5倍——能够在DNA中存储1000MB的数据,还实现了从存储到提取信息的重大突破。也就是说,用DNA存储数据已经成为可能。
该研究结果发表在一篇名为《DNA自动存储端到端自动化演示》的论文中,并于3月21日出版在Nature Scientific Reports版块。

人工合成DNA存储
DNA存储数字信息的空间比目前建造的数据中心要小好几个数量级。我们每天都在产生海量数据,从商业信息到可爱的动物视频再到医学扫描图像和外太空图像,因此DNA非常适合用来存储大规模的数据。
微软首席研究员Karin Strauss称:“我们的最终目标是将一个全自动系统投入到实际应用。对终端用户来说,这类似于云端存储服务——将数据上传到数据中心并存储在那里,用户随时可以查看并下载云端数据。要做到这一点,我们首先需要从自动化角度证明这是可用的。”
华盛顿大学的高级研究科学家Chris Takahashi说:“信息存储在人工合成的DNA分子中(而不是人类或其它生物的DNA分子),并且可以在发送到系统之前进行加密。 虽然这个过程的关键部分可以由DNA合成器和DNA测序仪等机器完成,但到目前为止,许多中间步骤都需要在研究实验室中进行人工操作,这在实际应用中是很难实现。”
“总不能让一群人带着移液器(一种用于定量转移液体的小型器具)在数据中心里四处奔跑,而且移液器在使用过程中容易出现人为错误,成本也很高。”
从信息存储商业化的角度来看,人们需要降低合成DNA的成本,包括合成存储信息的DNA双链和提取信息的DNA测序。
自动化是DNA存储商用关键
微软的研究人员说,自动化是另一个关键因素,因为它可以实现商业级规模的存储并极大降低成本。
现有的存档技术在几十年内将不再适用,而DNA存储信息的时间要比它长得多。比如说:DNA可以在猛犸象牙和原始人骨骼中存在数万年。
值得强调的是,这还不是理想的储存条件。DNA包含的遗传密码是通用的,也就是说自然界所有生物共用同一套遗传密码,基于此,理论上来说人类可以解读所有生物的遗传信息。
DNA是由四个碱基:腺嘌呤(A)、胸腺嘧啶(T)、胞嘧啶(C)和鸟嘌呤(G)构建而成的。微软和华盛顿大学联合开发了一套DNA数据自动存储系统,将数字数据的1和0转换为构成DNA的A、T、C和G,然后将其它必要反应液注入合成器,合成器就能合成DNA片段并将其推入储存器。
将1和0 转换成DNA的A、T、C、G
当系统需要检索信息时,它会添加其它化学物质来提取所需的DNA,并使用微流体泵将液体推入系统的其它部分。接着“读取”DNA序列并将其转换回计算机可以理解的信息。

研究人员表示,研究项目的目标不是要证明系统能够以多快的速度或多低的成本运作,而只是为了证明自动化是可行的。
DNA自动化存储系统的一个直接好处是,它可以让研究人员从繁复的实验中挣脱出来,去解决更深层次的问题。
微软研究员Bichlien Nguyen说:“自动化系统能进行重复性的工作,这使得人们能够从更宏观的角度制定新策略,从根本上进行更快的创新。”
分子信息系统实验室的团队已经证明DNA可以存储宠物照片,文学作品,流行视频和档案信息,并且在检索数据的过程中不出错。
研究人员还开发了一些技术来执行很有意义的计算任务——比如只搜索包含苹果或绿色自行车的图像,使用的是DNA分子本身,而不必将文件转换回数字格式。
华盛顿大学的Luis Ceze教授说:“我们肯定会看到一种新型计算机系统的诞生,人们可以使用DNA分子存储数据,用电子设备进行控制和处理。将DNA和计算机结合到一起为未来提供了无限的可能。”
人类的DNA存储探索
人类对DNA数据存储能力的探索早已有之。
1988年,艺术家乔•戴维斯与哈佛的学者合作,第一个将数字信号0和1对应到DNA的四个碱基。他们把DNA序列插入到大肠杆菌里,仅仅编码了35个字节。当排列成一个5*7的矩阵时,1对应到暗像素,0对应到亮像素,它们组成了一幅古代日耳曼如尼字母图画,代表生命和女性的地球。
现在戴维斯已经加入了丘奇的实验室,该实验室2011年起开始探索DNA数据存储。哈佛团队希望该应用可以减少合成DNA的高成本,就像基因组学的测序成本已经降低了许多。丘奇与加州大学洛杉矶分校的瑟里• 库苏里(Sri Kosuri)以及约翰•霍普金斯大学的基因组专家高原(Yuan Gao)于2011年11月实施了概念证明性实验。
他们的团队使用了很多短DNA片段编码了一本丘奇与他人合写的659KB数据的书。每个片段的一部分用来进行排序后片段组装顺序,剩余部分用于编码数据。将数据保存在DNA之中需要将二进制0和1数据转换为4种核苷酸,其中0用腺苷酸或胞嘧啶来编码,而1则用鸟苷酸或胸腺嘧啶。
这种灵活性帮助团队设计序列,避免测序中高GC区读取错误、重复序列或发卡结构导致的绑定彼此的片段发生序列折叠。他们没有做严谨的纠错,而是依靠每个片段拥有多个拷贝的信息冗余。结果对片段测序后,他们发现了22个错误,大大高于可靠存储的要求。
同时在EBI,高德曼、伯尼和他们的同事也在使用很多DNA片段来编码一个739KB的数据存储,包含一个图片、ASCII文本、声音文件和一个PDF版的华生和克里克标志性的双螺旋结构。为了避免重复碱基和其他来源的错误,EBI领导的这个团队使用了一个更加复杂的系统(见“制作存储体”)。
一方面是将0和1组成的二进制数据编码修改成以3个数为基础,即0,1和2,然后持续地轮换使用每一个数的代表,因此而避免在读取数据时序列可能出现的问题。通过利用序列重叠,100个碱基长度的片段持续位移25个碱基,EBI的科学家们确保有4个版本的片段来做错误检查和互相比较。
液体转移DNA难点
与基于硅的计算系统不同,基于DNA的存储和计算系统必须使用液体来转移DNA分子。流体本质上与电子不同,这意味着我们需要全新的技术解决方案。
华盛顿大学的团队与微软正在合作开发一种可编程系统,利用电和水的特性在电极网格上移动水滴,从而实现实验自动化。名为“Puddle”和“PurpleDrop”的一整套软件和硬件可以混合、分离、加热或冷却不同的液体并按标准实验步骤进行实验。
MISL团队下一步要做的是将简单的端到端自动化系统与PurpleDrop等技术以及能够使用DNA分子进行搜索的技术相结合。研究人员专门设计了模块化的自动化系统,使其能够随着新的DNA技术的出现而发展。
-
存储器
+关注
关注
38文章
7484浏览量
163763 -
DNA
+关注
关注
0文章
243浏览量
31026
原文标题:让DNA说Hello!微软成功研制用DNA存储读取数据的全自动系统
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
DNA计算机研究取得突破性进展:PB级数据存储与高效处理
人工神经元模型中常见的转移函数有哪些
基于微流控技术的DNA甲基化分析方法研究进展综述
基于熵驱动链置换策略的高灵敏mRNA检测与细胞内成像研究
电感耦合等离子体质谱+DNA纳米机器人用于HPV病毒的高效检测
高通量测序技术及原理介绍
深度学习破解DNA数据复制难题
基于离子浓度极化的微流控平台用于ctDNA的高灵敏度检测

DNA存储卡:高价与遥远现实

特色应用:TriVista在生命科学领域的应用

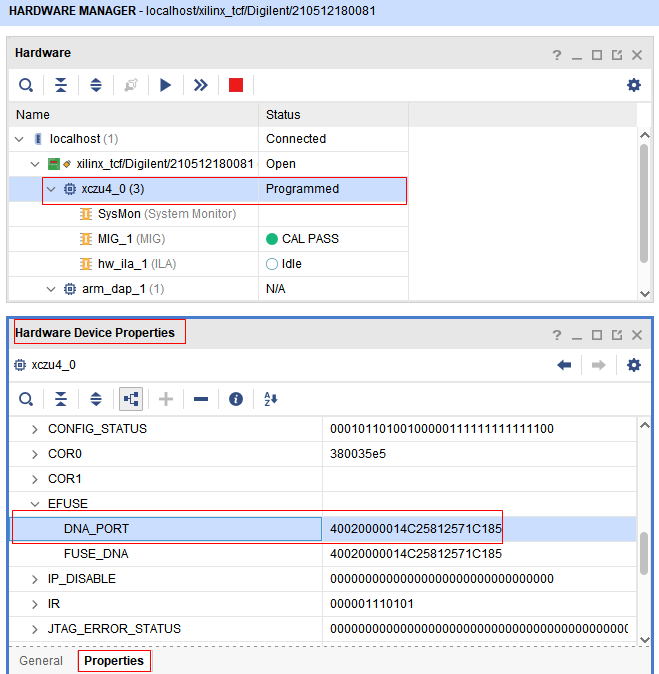
读取Xilinx FPGA芯片设备标识符的方法-DNA





 工商网监
工商网监
评论